Chrono: Multimodal LLM을 위한 간단한 시간 표현 청사진
Chrono는 비디오-언어 Multimodal LLM (MLLM)이 시간 정보를 이해하도록 돕는 간단한 청사진을 제안합니다. 기존 모델들은 비디오 내 특정 순간을 찾는 시간적 위치 파악(temporal localization) 문제 해결을 위해 복잡한 아키텍처나 추가 모듈을 사용했습니다. 반면, Chrono는 비디오 프레임과 해당 프레임의 타임스탬프를 텍스트 토큰으로 변환하여 번갈아 입력하는 간단한 시퀀스 설계만으로 이 문제를 해결합니다. 이 접근법은 기존의 이미지-텍스트 MLLM에 쉽게 적용 가능하며, 복잡한 구조 변경 없이도 Charades-STA, QVHighlights 등 주요 벤치마크에서 SOTA 성능을 달성하여, 단순하고 의도적인 설계의 효과를 입증합니다. 논문 제목: Chrono : A Simple Blueprint for Representing Time in MLLMs
Meinardus, Boris, et al. "Chrono: A Simple Blueprint for Representing Time in MLLMs." arXiv preprint arXiv:2406.18113 (2024).
Chrono : A Simple Blueprint for Representing Time in MLLMs
Boris Meinardus Hector G. Rodriguez Anil Barta Anna Rohrbach Marcus Rohrbach
Abstract
최근 **Large Language Model (LLM)**의 성공은 멀티모달 도메인으로의 확장을 촉진하여 이미지-텍스트 Multimodal LLM (MLLM), 그리고 나아가 비디오-텍스트 모델의 개발로 이어졌다. 본 연구에서는 비디오-언어 모델에서 문맥적(contextual) 및 시간적(temporal) 이해의 어려움을 비디오 내 temporal localization task를 탐구함으로써 조사한다.
이 문제를 해결하기 위해 기존 연구들은 복잡한 task-specific 아키텍처를 개발하거나, 시간 정보를 MLLM에 임베딩하기 위한 새로운 모듈을 도입하거나, 또는 비디오 스크립트와 같은 추가 입력 신호를 활용하여 문맥적 및 시간적 정보를 최적으로 인코딩해왔다.
흥미롭게도, 우리는 이러한 노력의 대부분이 훨씬 더 간단한 설계에 의해 능가될 수 있음을 발견했다. 우리는 **Chrono **를 소개한다. Chrono는 **이미지-텍스트 사전학습된 MLLM에 적용할 수 있는 범용 시퀀스 청사진(universal sequence blueprint)**이다.
다양한 MLLM 아키텍처, fine-tuning 및 zero-shot 설정, 그리고 여러 데이터셋에 걸친 광범위한 ablation을 통해, 우리는 가장 널리 사용되는 벤치마크인 Charades-STA, QVHighlights, ActivityNet Captions에서 moment retrieval 분야의 새로운 SOTA를 달성했으며, NeXT-GQA에서 grounded video question answering 분야의 새로운 SOTA를 달성했다.
1. Introduction
사전학습된 대규모 언어 모델(LLM)의 최근 성공(Brown et al., 2020; Zhang et al., 2022; Chung et al., 2022)은 비전 및 언어 양쪽 modality를 함께 이해할 수 있는 생성형 이미지-텍스트 사전학습 멀티모달 대규모 언어 모델(MLLM) 개발에 영감을 주었다(Alayrac et al., 2022; Li et al., 2023; Huang et al., 2024b). 그러나 비디오 데이터에 대한 대규모 사전학습은 더 높은 계산 및 어노테이션 비용으로 인해 확장하기가 더 어렵다. 이러한 문제를 해결하기 위해 최근 연구들은
 Figure 1. MLLM에 시간 개념을 어떻게 부여할 수 있을까? 기존 연구들이 별도의 모듈과 다양한 사전학습 전략을 활용하는 것과 달리, Chrono는 MLLM이 시간의 언어를 자연스럽게 이해하고 이를 비디오의 해당 세그먼트와 연결할 수 있도록 한다.
Figure 1. MLLM에 시간 개념을 어떻게 부여할 수 있을까? 기존 연구들이 별도의 모듈과 다양한 사전학습 전략을 활용하는 것과 달리, Chrono는 MLLM이 시간의 언어를 자연스럽게 이해하고 이를 비디오의 해당 세그먼트와 연결할 수 있도록 한다.
이미지-텍스트 사전학습 모델을 이미지-비디오 전이 학습(transfer learning)에 활용한다(Yu et al., 2023; 2024; Lei et al., 2021b; Luo et al., 2022; Fang et al., 2021; Ju et al., 2022). 이러한 모델들은 비디오-텍스트 검색(video-text retrieval) (Luo et al., 2022), 비디오 캡셔닝(video captioning) (Xu et al., 2023), 또는 객관식 비디오 질문 응답(multiple choice video question answering) (Yu et al., 2024) 분야에서 유망한 결과를 보여준다. 하지만 이러한 task들은 정확한 시간 이해를 요구하지 않는 반면, 모먼트 검색(moment retrieval, MR) task는 편집되지 않은 비디오에서 open-ended 자연어 쿼리와 관련된 모든 모먼트의 정확한 시간적 위치를 파악해야 하며, 아직 광범위하게 탐구되지 않았다.
이 task는 비디오 검색 또는 비디오 인덱싱과 같은 여러 잠재적으로 가치 있는 응용 분야를 가지고 있지만, 가장 중요하게는 비디오-언어 모델의 구체적인 시간 이해를 위한 테스트 베드로 활용될 수 있다. 더 구체적으로, 이 task는 open-ended 자연어 쿼리가 주어졌을 때, 잠재적으로 수 분 길이의 비디오에서 여러 이벤트들을 이해하고, 구별하며, 시간적으로 위치를 파악하는 것을 요구한다. MLLM의 맥락에서, 이 task를 sequence-to-sequence 예측 task로 가장 잘 모델링하는 방법, 특히 모델이 시간을 추론하고 시작 및 종료 타임스탬프를 정확하게 예측할 수 있도록 시간을 가장 잘 인코딩하는 방법은 여전히 미해결 과제이다.
전통적으로, 기존 연구들은 비디오 feature (Feichtenhofer et al., 2019) 또는 CLIP (Radford et al., 2021)을 활용하여 복잡하고 task-specific한 feature fusion 모듈을 훈련하고, 궁극적으로 고정된 후보 집합을 예측함으로써 모먼트 검색의 과제에 접근한다. Figure 1에서 보여지듯이, 최근 및 동시 진행된 접근 방식들은 MLLM을 시간적으로 grounding된 비디오-언어 task에 활용하며, 그중 가장 관련성이 높은 것이 모먼트 검색이다. 그러나 이들은 종종 대규모 instruction tuning 데이터셋 (Ren et al., 2023; Qian et al., 2024; Yang et al., 2023), 복잡한 다단계 훈련 (Huang et al., 2024a), 특수 아키텍처 (Qian et al., 2024; Ren et al., 2023), 또는 비디오 스크립트와 같은 추가 입력 신호 (Yang et al., 2023)를 요구한다. 이와 대조적으로, 우리는 이미지-텍스트 사전학습 MLLM이 비디오 모먼트 검색을 수행할 수 있도록 하는 새로운 멀티모달 입력 시퀀스 청사진인 Chrono를 개발한다. 흥미롭게도, 우리의 철저한 ablation 연구는 Figure 1에서 보여지듯이, 우리의 간단한 접근 방식이 훨씬 더 복잡한 모든 기존 방법들을 능가한다는 것을 보여준다. 우리는 이러한 입력 설계가 이미지-텍스트 사전학습 MLLM을 fine-tuning할 때나 강력한 MLLM을 zero-shot 응용 프로그램에 사용할 때 모두 최고의 시간적 grounding 능력을 가능하게 한다는 것을 보여준다. 우리의 접근 방식은 널리 사용되는 벤치마크인 Charades-STA (Gao et al., 2017), QVHighlights (Lei et al., 2021a), ActivityNet Captions (Krishna et al., 2017)에서 state-of-the-art (SOTA) 결과를 달성한다. 우리는 BLIP-2 (Li ets al., 2023)와 GPT-4o (OpenAI, 2024a)라는 서로 다른 아키텍처를 가진 두 MLLM backbone에 대해 광범위한 ablation study를 수행하여 신중한 설계 선택의 관련성을 논의한다. 비디오 모먼트 검색 데이터셋 외에도, 우리는 grounded video QA (GVQA)를 위한 데이터셋인 NExT-GQA (Xiao et al., 2023)도 고려한다. 여기서 task는 질문의 답변과 관련된 시간적 세그먼트를 지역화하는 것이다. 여기서는 Chrono가 이 task를 위해 훈련되지 않았음에도 불구하고 그러한 비디오 증거를 지역화하고 답변을 생성하는 능력을 평가하며, 다시 한번 SOTA 결과를 달성한다.
우리의 주요 기여는 다음과 같다: (i) 우리는 이미지-텍스트 사전학습 MLLM을 활용하여 모먼트 검색을 open-ended sequence-to-sequence 문제로 변환하여 접근한다. (ii) 입력 비디오에서 이벤트의 시간 이해를 향상시키기 위해, 우리는 새로운 멀티모달 입력 시퀀스를 설계하고, MLLM에서 시간을 표현하기 위한 간단하고 보편적인 청사진인 Chrono를 소개한다. (iii) Chrono 모델은 널리 사용되는 모먼트 검색 벤치마크 (Gao et al., 2017; Lei et al., 2021a; Krishna et al., 2017)에서 state-of-the-art를 향상시키고, grounded VQA (Xiao et al., 2023)에서 새로운 SOTA를 달성한다. (iv) 광범위한 실험과 ablation은 Chrono의 효과와 설계 선택의 중요성을 입증하며, 신중한 간단한 방법 탐구가 복잡하고 잠재적으로 과도하게 설계된 방법들을 능가할 수 있음을 강조한다. (v) 우리는 우리의 코드와 모델을 공개적으로 이용 가능하게 한다.
2. Related Work
2.1. Moment Retrieval Models
Moment Retrieval은 정제되지 않은(untrimmed) 비디오를 분석하여 주어진 open-ended 자연어 쿼리에 해당하는 관련 클립을 찾는 것을 목표로 한다. 기존 접근 방식은 proposal-based 또는 proposal-free 방법으로 나뉜다.
- Proposal-based 방법은 첫 번째 단계에서 사전 정의된 proposal(예: sliding window (Anne Hendricks et al., 2017; Gao et al., 2017) 및 temporal anchor (Chen et al., 2018; Wang et al., 2020))을 기반으로 moment 후보를 식별하는 것을 학습한다. 두 번째 단계에서는 이러한 후보들을 텍스트 쿼리에 더 잘 맞도록 정제한다.
- Proposal-free 접근 방식 중에서는 regression-based 방법이 일반적이다 (Lei et al., 2021a; Yan et al., 2023; Liu et al., 2022; Mun et al., 2020; Zeng et al., 2020). 이들은 초기 proposal을 생성하는 첫 번째 단계 없이 관련 moment의 시간적 경계(temporal boundaries)를 직접 예측한다.
그럼에도 불구하고, proposal-free 방법은 여전히 고정된 수의 후보 window를 confidence score와 함께 예측하며, 이를 기반으로 예측을 정렬한다. 고정된 수의 proposal을 사용하는 것은 몇 가지 단점이 있다. 예를 들어, proposal 개수 하이퍼파라미터 튜닝에 사용된 데이터보다 더 많은 action을 포함하는 비디오에 일반화되지 않거나, 중복 proposal에 대한 연산 낭비가 발생할 수 있다.
최근 연구들은 멀티모달 LLM을 사용하여 temporal modeling에 대한 다양한 접근 방식을 탐구해왔다. Ren et al. (2023)은 Q-Former를 통해 temporal information을 통합하여 time-sensitive frame embedding을 TimeChat 모델에 도입했다. Huang et al. (2024a)는 VTimeLLM을 광범위한 video-language pretraining을 포함하는 3단계 학습 설정으로 학습시켰다. Momentor (Qian et al., 2024)는 전용 Temporal Perception Module을 제안하고, Lita (Huang et al., 2025)는 특수 temporal token을 탐구한다.
이러한 최근의, 그리고 여러 경우 동시 진행된 접근 방식들은 MLLM이 temporal understanding에 잠재력이 있음을 보여주지만, 종종 대규모 instruction tuning dataset (TimeChat, Momentor), 복잡한 다단계 학습 (VTimeLLM), 또는 특수 아키텍처 (Momentor)를 요구한다. 이와 대조적으로, 우리의 연구는 temporal information을 표현하는 데 있어 신중한 설계 선택이 moment retrieval task에 대한 사전 학습 없이도 moment retrieval을 가능하게 할 수 있음을 보여준다. 더욱이, 다운스트림 task에 대한 직접적인 finetuning과 결합될 때, 우리의 Chrono 청사진은 값비싼 pretraining이나 아키텍처적 복잡성 없이도 우수한 성능을 달성할 수 있다. 체계적인 ablation을 통해, 우리는 단순한 설계 선택(예: absolute integer timestamp 사용)이 특수 token이나 전용 temporal module을 도입하는 더 복잡한 접근 방식보다 뛰어난 성능을 보일 수 있음을 입증한다.
2.2. Image-to-Video Transfer Learning
고품질의 대규모 비디오-언어 데이터셋의 제한적인 공개 가용성과 비디오를 사용한 학습에 필요한 막대한 연산 요구 사항은 대규모 비디오-언어 사전학습에 상당한 어려움을 제기한다. 제한된 수의 비디오 프레임을 활용하여 학습 효율성을 높임으로써 이미지-언어 사전학습 모델을 이미지-투-비디오 전이 학습에 활용하는 아이디어는 최근 많은 연구(Yu et al., 2023; 2024; Cao et al., 2022; Fang et al., 2021; 2022; Ju et al., 2022; Lei et al., 2021b; Luo et al., 2022; Ma et al., 2022; Lei et al., 2022; Xue et al., 2023; Wang et al., 2022)에서 입증되었듯이 효과적임이 밝혀졌다. 특히, (Yu et al., 2024)는 MLLM의 문맥 이해 능력을 활용하여 비디오 QA task를 수행한다. 저자들은 BLIP-2 모델을 학습시켜 질문과 관련된 4개의 프레임을 개별적으로 선택하고, 이를 사용하여 또 다른 BLIP-2 모델을 fine-tuning하여 질문에 답한다. 우리 또한 사전학습된 BLIP-2 모델을 활용하고, 이를 moment retrieval이라는 다운스트림 task에 fine-tuning하여 Yu et al. (2024)보다 큰 폭의 localization 개선을 달성한다. 나아가, moment retrieval을 기본적으로 수행할 수 없는 GPT-4o (OpenAI, 2024b)와 같은 강력한 이미지-텍스트 모델도 우리의 Chrono blueprint를 사용하면 경쟁력 있는 결과를 얻을 수 있음을 보여준다.
3. Chrono ©
MLLM에서 시간을 가장 잘 표현하는 방법을 탐구하기 위해, 우리는 moment retrieval task를 적합한 테스트 베드로 선정하였다. 이 task는 자유 형식의 자연어 쿼리가 주어졌을 때, 편집되지 않은 비디오에서 모든 관련 순간(moment)을 시간적으로 지역화(temporally localize)하는 것이다. 따라서 핵심 과제는 비디오 내의 다양한 이벤트 간의 문맥적 및 시간적 관계를 효과적으로 모델링하는 것이다. 예를 들어, Figure 2에서 보여주듯이, 한 남자가 카메라에 대고 말한 후 쇼를 시청하는 것과 같은 상황이다.
더 나아가, 비디오에 포함된 정보의 양 때문에 단일 forward pass에서 비디오의 모든 프레임을 context로 활용하는 것은 계산적으로 불가능하다. 이러한 문제들을 해결하기 위해 우리는 moment retrieval을 language modeling task로 간주하고, generative MLLM의 문맥 이해 능력을 활용하여 비디오를 나타내는 프레임 내의 의미론적 및 시간적 행동 전개(semantic and temporal action development)를 해석하고 이해한다.
우리는 먼저 MLLM에서 timestamp를 설계하는 공간을 철저히 탐구한다. 우리의 분석 결과, Chrono라는 제안된 레시피가 도출되었는데, 이는 이미지-텍스트로 사전학습된 MLLM이 비디오 프레임과 그에 상응하는 시간적 grounding을 fine-tuning 및 zero-shot 설정 모두에서 해석할 수 있도록 한다. Section 3.1에서는 우리가 제안하는 청사진인 Chrono를 제시한다. Section 3.2에서는 우리의 model-agnostic Chrono 청사진이 fine-tuning 및 zero-shot 설정을 사용하여 MLLM을 적응시키는 데 어떻게 활용될 수 있는지 논의한다.
3.1. Chrono blueprint
본 연구는 이미지-텍스트 사전학습된 MLLM이 자연어 쿼리가 주어졌을 때 비디오 내 temporal grounding task를 위해 비디오와 시간을 이해하는 방법을 탐구한다. 이를 위해 우리는 전통적인 moment retrieval task를 open-ended sequence-to-sequence 문제로 재구성하며, 다음과 같은 새로운 멀티모달 입력 시퀀스를 설계한다:
(a) 샘플링된 비디오 프레임에서 얻은 시각적 의미론적 맥락(visual semantic context), (b) 각 이벤트에 대한 시간적 맥락(temporal context). 이는 각 프레임의 시간적 위치(즉, 타임스탬프)와 전체 비디오 길이를 통해 모델링된다. (c) 자연어 설명 형태의 쿼리(query).
우리 모델의 출력은 시간 간격 시퀀스이며, 각 시간 간격은 쿼리와 관련된 순간(moment)을 나타낸다. 이 시퀀스는 시작 시간과 종료 시간을 가진 (잠재적으로) 여러 순간들의 중첩된 리스트 형식을 따른다. 특히, 우리는 어떤 새로운 특수 토큰도 추가하지 않고 backbone MLLM의 고유한 어휘를 사용하는데, 이는 우리 프레임워크가 더욱 일반적이고 zero-shot 설정에서도 적용 가능하도록 한다.
비디오 내 다양한 동작과 자연어 쿼리 간의 맥락적 및 시간적 관계를 모델링하기 위해, 우리는 moment retrieval을 sequence-to-sequence task로 재구성하고 새로운 멀티모달 입력 시퀀스를 개발한다. Figure 2에 나타난 바와 같이, 이 시퀀스는 **프레임 , 타임스탬프 (), 비디오 길이 , 쿼리 , 그리고 현재 task를 명시하는 task prompt **로 구성된다. zero-shot 설정에서는 형식 준수(format-adherence) prompt도 포함되는데, 이는 Appendix Figure 4에 제시되어 있다.
특히, 타임스탬프 를 표현하는 방법은 여러 가지가 있다. 시간은 절대적 또는 상대적 형태로 표현될 수 있다 (예: "79.9"초 또는 상대적 위치를 나타내는 "0.40" (0은 비디오 시작, 1은 끝)). 또한 소수점 숫자이거나 가장 가까운 정수로 반올림될 수 있다 (예: "80"초 또는 상대적 위치를 나타내는 "40"). 타임스탬프는 프레임 뒤에 연결되거나 프레임과 교차(interleave)될 수 있다. Figure 2에서 보듯이, 우리는 시간을 정수 초(integer absolute form)의 단순한 텍스트 토큰으로 표현하고 해당 프레임과 교차시키는 방식이 가장 좋은 성능을 보인다는 것을 발견했다. 이러한 발견은 우리의 멀티모달 입력 시퀀스에 대한 최종 설계로 이어진다:
여기서 은 반올림 연산을 나타낸다. Section 4.1에서는 시간 표현의 다양한 변형과 입력 시퀀스 요소들의 연결 방식을 탐구한다.
마지막으로, 모델은 잠재적으로 여러 개의 관련 있는 시간 구간 의 시퀀스를 예측하도록 요구받으며, 이는 시작 시간과 종료 시간을 초 단위로 포함하는 중첩된 순간 리스트 형식을 따른다:
특히, 이 청사진은 MLLM 아키텍처에 구애받지 않으며, 어떤 이미지-텍스트 사전학습 모델이든 간단한 fine-tuning과 심지어 zero-shot 설정에서도 적용될 수 있다. 이에 대해서는 Section 3.2에서 논의한다.
Chrono: MLLM에서 시간을 표현하기 위한 간단한 청사진
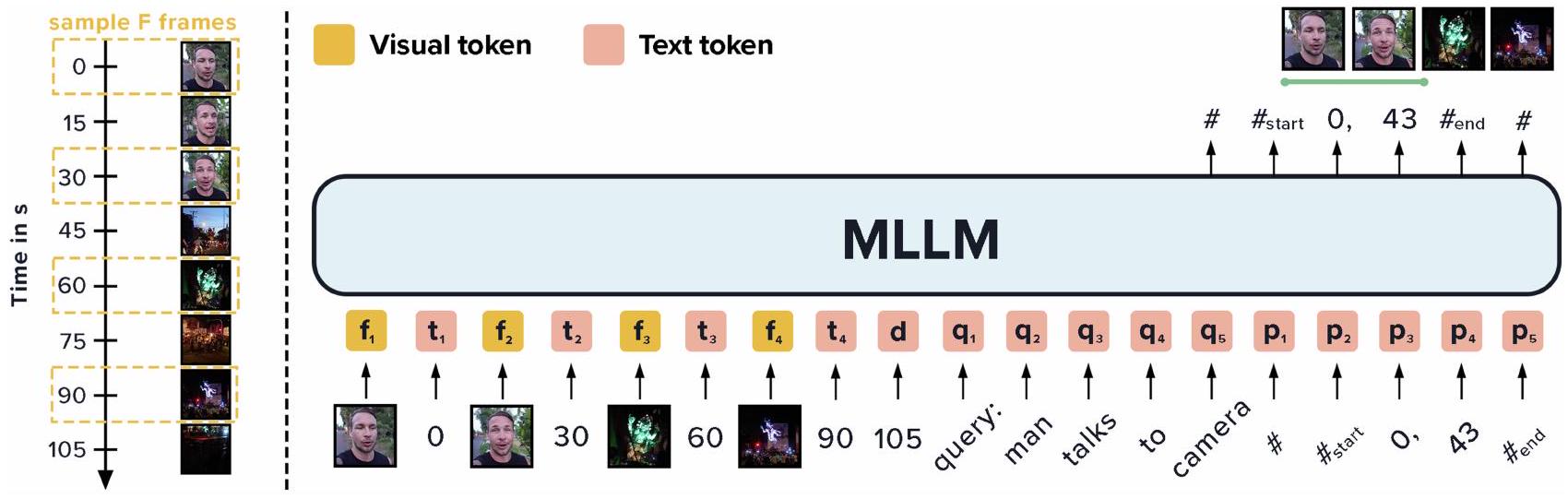
Figure 2. Chrono © 모델 개요. 본 연구에서는 우리 프레임워크가 모델에 구애받지 않으며(model-agnostic), 이미지-텍스트 사전학습된 MLLM을 zero-shot (fine-tuning 없음) 설정에서도 적용할 수 있음을 보여준다. 우리는 프레임 임베딩과 각 샘플링된 프레임의 타임스탬프를 교차(interleave)하여 MLLM을 위한 prompt를 구성하며, 그 뒤에 비디오 길이, moment retrieval 쿼리, 그리고 task prompt가 이어진다 (task prompt는 시각화되지 않음). MLLM은 전역 BOS 및 EOS 토큰( #으로 표시), window의 시작 및 끝 토큰( #start 및 #end로 표시), 그리고 각 window의 해당 시작 및 종료 시간을 예측함으로써 잠재적으로 여러 개의 검색된 순간(moment) 시퀀스를 출력한다. 모델을 fine-tuning하는 경우(Chrono-BLIP), 우리는 MLLM을 고정(freeze)하고 parameter-efficient fine-tuning (Hu et al., 2022)을 활용하여 추가 adapter layer만 fine-tuning한다.
3.2. Training and Zero-Shot Chrono Setup
이 섹션에서는 Chrono blueprint를 적용하는 두 가지 다른 옵션을 설명한다. 우리는 생성형 MLLM을 학습시키거나, moment retrieval task에 대해 zero-shot adaptation을 수행할 수 있다. 우리는 전통적인 컴퓨터 비전 문제인 moment retrieval을 open-ended 자연어 sequence-to-sequence task로 변환한다.
학습 설정 (Training Setup)
모델 학습을 위해 우리는 표준 최대 우도(maximum likelihood) 목적 함수를 최적화한다. 학습을 더욱 최적화하고 제한된 비디오 데이터를 최대한 활용하기 위해, 우리는 LoRA (Hu et al., 2022)를 통한 parameter-efficient fine-tuning을 구현하고 비디오 프레임을 무작위로 샘플링한다. 이를 통해 우리는 MLLM 파라미터의 일부만 학습할 수 있다. 또한, 프레임을 무작위로 샘플링함으로써, 매 epoch마다 동일한 비디오의 다른 프레임과 타임스탬프를 분석하여 해당 가중치를 최적화한다. 자세한 내용은 Appendix B.2.2를 참조하라.
특히 우리 실험에서는 **encoder-decoder 스타일의 MLLM인 BLIP-2 (Li et al., 2023)**를 활용한다. 우리는 **BLIP-2의 frozen image encoder와 Q-Former를 결합한 것을 범용 프레임 인코더(general-purpose frame encoder)**로 지칭한다. 이 프레임 인코더는 개의 서브 샘플링된 각 프레임에 개별적으로 적용되어, 프레임 임베딩을 생성하고 이를 언어 공간으로 투영하여 공유 임베딩 공간을 생성한다. 이전 연구들 (Wang et al., 2024; Ren et al., 2023; Yang et al., 2023; Zhang et al., 2023b)은 시간적, 문맥적으로 상호 연관된 프레임 또는 비디오 수준 임베딩을 생성하기 위해 추가적인 trainable Transformer 기반 모듈을 통합한다. 이와 대조적으로, 우리는 프레임 간의 시간적 및 문맥적 관계를 학습하기 위해 LLM의 self-attention 및 cross-attention 메커니즘만을 활용한다. 우리는 이러한 Chrono blueprint의 구현을 Chrono-BLIP이라고 명명한다.
Zero-Shot 설정 (Zero-Shot Setup)
Zero-shot adaptation을 위해, 우리는 Chrono 프레임워크를 instruction-following 능력을 가진 MLLM에 적용할 수 있다. 학습 설정과 마찬가지로, 비디오 프레임을 해당 타임스탬프, 비디오 길이, 사용자 쿼리 및 instruction prompt와 함께 interleave하여 제공한다. 차이점은 instruction prompt를 수정하여 MLLM backbone이 원하는 task를 이해하고 해결하며, 원하는 형식으로 반환하도록 하는 것이다.
우리 실험에서는 Chrono blueprint의 능력을 다른 MLLM 아키텍처, 즉 decoder-only 아키텍처에서도 시연하고자 하며, 따라서 GPT4o (OpenAI, 2024a)를 MLLM backbone으로 선택한다. 우리는 이 프레임워크의 구현을 Chrono-GPT라고 부르며, 사용된 전체 prompt는 Appendix Figure 4에 제공되어 있다.
4. Experiments
이 섹션에서는 우리의 설계 선택의 효과를 설명하고, 우리의 방법론을 state-of-the-art와 비교한다. 우리는 Chrono를 가장 널리 사용되는 세 가지 video moment retrieval (MR) 데이터셋인 Charades-STA (Gao et al., 2017), QVHighlights (Lei et al., 2021a), ActivityNet Captions (Krishna et al., 2017)에서 검증하고, NExT-GQA (Xiao et al., 2023) 벤치마크에서 grounded video question answering task로 프레임워크를 확장한다. 우리는 이 섹션에서 실험 결과를 제시하고 분석하며, 실험 설정에 대한 자세한 내용은 Appendix B에 수록되어 있다.
Table 1. Ablation study.
우리는 (a) prompt 구성 요소와 (b) timestamp 설계를 fine-tuned Chrono-BLIP과 zero-shot Chrono-GPT 모두에 대해 연구한다. Chrono-BLIP의 경우 Charades-STA validation set에서, Chrono-GPT의 경우 QVH validation set에서 ablation을 수행한다.
D: Video Duration, T: Frame Timestamps, Rep: Representation, Rel: Relative, Abs: Absolute, Prec: Precision, Dec: Decimal, Int: Integer, Inter: Interleaved.
| (a) Prompt design components | (b) Timestamp design | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Rep. | Prec. | Inter. | Chrono-BLIP | Chrono-GPT | |||||||||
| Chrono-BLIP | Chrono-GPT | R1@.5 | R1@. 7 | R1@. 5 | R1@. 7 | ||||||||
| D | T | R1@. 5 | R1@. 7 | R1@. 5 | R1@. 7 | (1) | Rel | Dec | 62.30 | 37.22 | 48.39 | ||
| 43.84 | 23.95 | 5.74 | 1.94 | (2) | Abs | Dec | 62.38 | 36.33 | 44.19 | 24.58 | |||
| 55.60 | 32.63 | 4.39 | 1.87 | (3) | Rel | Int | 63.10 | 36.01 | 30.42 | 19.90 | |||
| 67.81 | (4) | Abs | Int | 64.39 | 41.80 | 36.77 | 20.68 | ||||||
| 67.28 | 46.70 | 61.68 | 41.80 | (5) | Rel | Int | 62.84 | 42.19 | |||||
| (6) | Abs | Int | 67.28 | 46.70 | 61.68 |
4.1. Ablation Studies
기본적으로 Charades-STA (QVHighlights/ ActivityNet Captions)용 Chrono 모델은 20 (60)개의 visual frame, 관련 타임스탬프, 비디오 길이, 쿼리, 그리고 task prompt를 활용한다. 별도로 명시되지 않는 한, 우리는 시간을 정수 초 단위의 단순 텍스트 토큰으로 표현하고, 이를 프레임 토큰과 interleave한다.
다음에서는 이러한 설계 선택이 다운스트림 moment retrieval 성능에 미치는 영향을 ablation 실험을 통해 분석한다. 이를 위해 Chrono-BLIP의 결과는 Charades-STA validation set에서, Chrono-GPT의 결과는 QVHighlights validation set에서 보고한다.
4.1.1. DESIGN OF SEQUENCE
Table 1 (a)에서는 프레임만 제공하는 것부터 시작하여 각 구성 요소를 누적적으로 추가하면서, MLLM의 멀티모달 입력 시퀀스 각 부분의 효과를 분석한다. 쿼리는 항상 시퀀스의 일부이다.
Chrono-BLIP의 경우, 시각 입력 외에 비디오 길이(duration)를 추가하면 다운스트림 성능이 크게 향상된다 (2행 vs. 1행). 이는 모델이 각 프레임의 시간적 위치를 추론하기 위한 참조점(point of reference)을 제공하는 것의 중요성을 보여주며, MLLM이 이러한 연관성을 학습할 수 있는 능력을 입증한다. 반면, Chrono-GPT는 fine-tuning된 BLIP-2 모델만큼 추가 정보로부터 강하게 이점을 얻지 못한다. 다시 말하지만, 균일하게 샘플링된 고정된 수의 프레임과 비디오 길이가 주어지면, 모델은 각 프레임이 어떤 타임스탬프에서 샘플링되었는지 계산하는 데 필요한 모든 정보를 갖게 된다. 우리의 실험은 GPT-4o가 이 정보를 활용하지 못하는 것으로 보인다는 것을 보여준다.
하지만, 각 프레임이 샘플링된 특정 타임스탬프를 interleaved 방식으로 제공하면 (Figure 2에 설명된 바와 같이), 두 모델의 성능이 크게 향상된다 (행 (3,4) vs. 행 (1,2)). 이는 추가적인 계산(예: transcript 생성 및 활용)에 의존하지 않으면서도 가능한 한 많은 관련 정보를 제공하도록 입력 context를 설계하는 것의 중요성을 보여준다. 비디오 길이와 함께 모든 타임스탬프를 제공하면 두 모델 모두에서 최고의 성능을 얻을 수 있다 (4행 vs. 3행).
4.1.2. Design of timestamps
본 연구의 핵심 질문은 MLLM이 타임스탬프를 어떻게 가장 잘 표현하고 추론할 수 있는가이다. 타임스탬프는 입력에서 해석되고 출력에서 예측되어야 하기 때문이다. 우리는 타임스탬프를 표현하는 다양한 옵션과 이것이 최종 다운스트림 모델 성능에 미치는 영향을 비교한다.
우리는 다음 두 가지 방식을 탐구한다:
- 비디오 길이에 대한 상대적 위치(relative positions) 사용
- 각 타임스탬프를 절대 시간(absolute time)으로 표현
또한, 이들을 소수점 숫자(예: 절대 시간 "79.9"초, 상대 시간 "0.40")로 표현하는 방식과 정수(예: 절대 시간 "80"초, 상대 시간 "40")로 표현하는 방식을 비교한다. 이 실험들에서 모델의 입력 및 출력 타임스탬프 형식은 항상 일관되게 유지된다. 상대적 위치의 경우, 최종 평가를 위해 ground truth와 비교할 수 있도록 출력값을 절대값으로 후처리한다.
Table 1 (b)의 Chrono-BLIP ablation 결과를 살펴보면, 타임스탬프를 소수점 형태로 표현하는 것이 절대 및 상대 형식 모두에서 성능 저하를 가져온다는 것을 알 수 있다 (행 (1,2)와 행 (3,4) 비교). 우리는 이러한 현상이 소수점 숫자가 토큰화되는 방식 때문이라고 가정한다. 소수점 타임스탬프를 사용하면 더 높은 시간 해상도를 얻을 수 있지만, 이러한 낮은 성능은 소수점 숫자의 토큰화와 관련된 한계에 기인한다고 추정한다. 토크나이저에 따라 "79.9" 또는 "42.05"와 같은 소수점 숫자는 각각 다른 수의 토큰으로 분할될 수 있는 반면, 정수(특정 숫자까지)는 단일 토큰으로 토큰화된다. 그럼에도 불구하고, 이러한 동작은 토크나이저마다 다르며, 따라서 분산이 발생할 수 있다는 점에 유의해야 한다. 또한, 정수 정밀도를 사용할 때 절대 위치(초 단위)가 상대적 표현보다 더 나은 성능을 보인다는 것을 관찰했다. 이는 MLLM의 표현 방식을 염두에 두고 입력과 출력을 설계하는 것의 중요성을 보여준다.
Chrono-GPT의 경향을 분석했을 때, 이러한 경향은 그리 명확하지 않다. Chrono-GPT를 다운스트림 task에서 평가할 때 많은 분산이 관찰되며, 처음 네 행만 살펴보면 GPT-4o가 소수점 정밀도를 선호하는 것처럼 보인다. 우리는 GPT-4o 토크나이저가 숫자를 처리하는 데 더 발전되고 적합하며, 더 일관된 토큰화 체계를 가지고 있다고 가정한다. 그러나 interleaved 설정에서 정수와 소수점 정밀도를 비교했을 때, GPT-4o는 정수 정밀도를 선호한다는 것을 발견했다 (Appendix C.2 참조).
마지막으로, 우리는 프레임 및 시간 토큰의 순서에 대한 설계 선택을 탐구한다. 행 (1)부터 (4)까지는 모든 프레임을 함께 연결한 다음, 각 타임스탬프를 구분자 토큰(">"")으로 분리하여 연결한다. 행 (5)와 (6)에서는 상대 및 절대 타임스탬프 모두에 적용했을 때 프레임 토큰과 시간 토큰을 interleave하는 것의 이점을 관찰한다. Chrono-BLIP과 Chrono-GPT 두 모델 모두에서, 우리의 시퀀스 설계에서 가장 명확한 이점은 프레임과 타임스탬프를 interleave하는 것이 interleave하지 않은 설정보다 훨씬 우수한 성능을 보인다는 것이다. 우리의 실험은 BLIP-2 backbone에 적용했을 때, interleave된 시퀀스 설계에서 가장 가까운 정수로 반올림된 초 단위로 시간을 표현하는 것이 가장 좋은 성능을 낸다는 것을 보여준다. 반면, Chrono-GPT 설정에서는 상대적 표현과 절대적 표현이 동등한 성능을 보인다. 다음 실험 설정에서 단순성과 일관성을 위해 Chrono-GPT에는 행 6의 설정을 사용한다.
4.2. Comparison to the SOTA in Moment Retrieval
다음으로, Section 4.1에서 도출된 최적의 설계 선택을 바탕으로 MR(Moment Retrieval) 분야의 state-of-the-art (SOTA) 접근 방식과 Chrono를 비교한다. 구체적으로, Chrono-BLIP은 다른 fine-tuned baseline과 비교하고, Chrono-GPT는 zero-shot baseline과 비교한다.
첫째, Table 2에서는 바닐라 BLIP-2 모델과의 비교를 포함한다. 이 모델은 BLIP-2의 context에 프레임만 포함하고 각 데이터셋에 대해 fine-tuning 및 평가를 수행한 것이다. 예상대로, 우리의 Chrono-BLIP 모델은 이 baseline을 크게 능가한다. 특히 QVH 데이터셋의 경우, 비디오 길이가 항상 150초로 일정하기 때문에 모델이 각 프레임의 시간적 위치를 더 잘 추론할 수 있어 다른 데이터셋에 비해 개선 폭이 덜 두드러진다. 그럼에도 불구하고, 여전히 우리의 Chrono-BLIP 모델보다 훨씬 낮은 성능을 보인다.
QVHighlights에서 기존 SOTA 방법들과 비교했을 때, Chrono-BLIP은 이전 SOTA인 InternVideo2 (Wang et al., 2024)를 모든 지표에서 크게 능가한다. InternVideo2는 고비용의 비디오 사전학습이 필요한 범용 video-language foundation model이다. 우리 모델은 R1@0.5에서 3.35%, R1@0.7에서 4.06%의 성능 향상을 보인다. Charades-STA에서도 우리의 Chrono-BLIP 모델은 이전 SOTA 모델 (Wang et al., 2024)을 R1@0.7에서 능가하며 새로운 state-of-the-art를 달성한다. InternVideo2는 중간 feature를 추출하고 CG-DETR (Moon et al., 2023a)을 localization head로 활용하여 좋은 성능을 달성하지만, 우리는 훨씬 적은 학습 데이터, 더 작은 모델 크기, 적은 학습 파라미터, 그리고 task-specific 출력 head에 의존하지 않고도 강력한 결과를 보여준다. 우리는 오직 다운스트림 task에 대해서만 fine-tuning을 수행한다. Chrono-BLIP은 ActivityNet Captions의 moment retrieval에서도 이전 SOTA (Yan et al., 2023)를 R1@0.5에서 5.62%, R1@0.7에서 5.35% 능가한다.
우리의 연구는 동일한 image-text 사전학습 MLLM인 BLIP-2 (Li et al., 2023)를 backbone으로 활용하는 SeViLa (Yu et al., 2024)와 가장 유사하다. 우리의 Chrono 모델은 QVHighlights에서 IoU=0.5 및 IoU=0.7 임계값에서 Recall@1 기준으로 SeViLa보다 각각 20.14% 및 23.29% 더 높은 성능을 달성한다. 이는 우리의 새로운 multimodal sequence 설계의 효과를 입증한다. 우리 모델은 contextual 및 temporal 정보를 받아 연속적인 autoregressive forward pass를 통해 관련 순간을 예측한다. 반면, SeViLa는 비디오에 대한 어떠한 contextual 및 temporal 정보 없이 각 프레임이 쿼리와 관련이 있는지 여부만을 분류한다.
또한, 우리는 Chrono-GPT 모델을 모든 세 가지 MR 벤치마크에서 zero-shot 설정으로 평가한다. 예상대로, Chrono-GPT가 달성한 성능은 동일한 데이터셋에서 Moment Retrieval을 위해 명시적으로 학습된 방법들에 비해 훨씬 낮다. 그러나 Chrono 프레임워크 없이 프레임만 제공하는 baseline보다 훨씬 더 나은 성능을 보이며, 이는 우리의 Chrono 청사진이 zero-shot 방식으로 moment retrieval을 가능하게 함을 입증한다. 이는 경쟁력 있는 결과를 가진 가장 간단한 접근 방식을 추구하는 우리의 목표를 강화하며, 실무자들에게 매우 유용할 것이라고 믿는다.
마지막으로, 더 많은 MLLM 기반 MR 모델과 비교하기 위해 Table 3에서 전이 학습(transfer learning) 설정에서의 Chrono-BLIP 성능을 평가한다. 이전 연구들 (Qian et al., 2024; Ren et al., 2023; Huang et al., 2024a)은 여러 temporal grounding 데이터셋에 대해 광범위한 video-language instruction fine-tuning을 수행하고, held-out Charades-STA 데이터셋에서 성능을 평가한다. (Qian et al., 2024)의 학습 코퍼스에는 ActivityNet의 일부가 포함되어 있지만, 그들은 해당 테스트 세트에서도 평가를 수행하는 반면, 우리의 전이 학습 설정은 QVH에서만 학습하고 ActivityNet Captions에서 평가하는 방식이다. Charades-STA 평가를 위해서는 ActivityNet Captions에서 학습한다. 이러한 이전 연구들은 훨씬 더 큰 데이터셋에서 학습하고 더 큰 모델 크기를 가지지만, 우리는 다시 한번 SoTA 결과를 달성한다.
우리는 간단하지만 신중한 설계 선택이 image-text 사전학습 MLLM을 활용하여 state-of-the-art 결과를 달성하는 데 있어 놀라운 효과를 보여준다.
Table 2. QVHighlights (Lei et al., 2021a), Charades-STA (Gao et al., 2017), ActivityNet Captions (Krishna et al., 2017)에 대한 state-of-the-art 비교. 는 QVH 결과가 validation set에서 보고되었음을 나타낸다.
| Method | QVHighlights | Charades-STA | ActivityNet | ||||||
|---|---|---|---|---|---|---|---|---|---|
| R1@. 5 | R1@. 7 | mAP | mAP@. 5 | mAP@. 75 | R1@. 5 | R1@. 7 | R1@. 5 | R1@. 7 | |
| Finetuned for Moment Retrieval | |||||||||
| VLG (2021) | - | - | - | - | - | - | - | 46.30 | 29.80 |
| SeViLa (2024) | 54.50 | 36.50 | - | - | - | - | - | - | - |
| CG-DETR (2023a) | 65.43 | 48.38 | 42.90 | 64.51 | 42.77 | 58.44 | 36.34 | - | - |
| UnLoc-L (2023) | - | - | - | - | - | 60.80 | 38.40 | 48.30 | 30.20 |
| (2023) | 61.36 | 45.79 | 41.74 | 61.86 | 41.91 | 68.47 | 44.92 | - | - |
| InternVideo2-6B (2024) | 71.42 | 56.45 | 49.24 | - | - | 70.03 | 48.95 | - | - |
| BLIP-2 (frames only) | 69.10 | 46.52 | 37.87 | 60.68 | 38.93 | 43.33 | 32.60 | 25.84 | 9.72 |
| Chrono-BLIP | 74.77 | 60.51 | 51.37 | 68.12 | 53.38 | 69.31 | 49.29 | 53.92 | 35.55 |
| Zero-Shot | |||||||||
| GPT-4o (frames only) | 5.49 | 2.17 | 1.1 | 2.81 | 0.76 | 7.02 | 2.12 | 7.20 | 2.80 |
| Chrono-GPT | 61.68 | 41.80 | 33.01 | 52.39 | 35.05 | 28.76 | 10.99 | 31.06 | 17.51 |
Table 3. 데이터셋 간 moment retrieval에 대한 전이 학습 결과. *는 Momentor가 ActivityNet Captions의 하위 집합에서 학습되었음을 나타낸다.
| Charades-STA | ActivityNet | |||||
|---|---|---|---|---|---|---|
| Method | R1@.5 | R1@.7 | R1@.5 | R1@.7 | ||
| Momentor* (2024) | 26.60 | 11.60 | 23.00 | 12.40 | ||
| TimeChat (2023) | 32.20 | 13.40 | - | - | ||
| VTimeLLM (2024a) | 34.30 | 14.70 | - | - | ||
| Chrono-BLIP© |
4.3. Grounded Video QA on NExT-GQA
다음으로, 우리는 Chrono에게 새로운 task인 NExT-GQA (Xiao et al., 2023) 벤치마크에서 **grounded video question answering (GQA)**를 수행하도록 한다. 이는 질문에 답하는 데 관련 있는 순간을 찾아내고, 그 질문에 답하는 것을 의미한다. 벤치마크 및 측정 지표에 대한 자세한 내용은 Appendix B에 제공된다.
GQA에서 Chrono-BLIP을 평가하기 위해, 우리는 SeViLa (Yu et al., 2024)의 localizer-answerer 접근 방식을 따른다. 이 방식은 관련 순간을 찾는 데 60프레임을 사용하고, 그 세그먼트에서 질문에 답하기 위해 새로운 60프레임을 다시 샘플링한다. 우리는 QVH로 사전학습된 Chrono-BLIP 모델을 localizer로 적용하고, 별도의 Flan-T5 XL LLM을 answerer로 fine-tune한다. 특히, 우리는 localization 모델을 fine-tune하지 않으므로, 이를 새로운 도메인, 즉 질문 도메인에 적용한다. 이 도메인에서는 관련 순간이 질문에 명시적으로 설명되지 않아도 관련성이 있을 수 있다. 우리는 또한 60프레임을 균일하게 샘플링하는 방식과도 비교한다. Table 4는 NExT-GQA (Xiao et al., 2023) 벤치마크에서 Chrono-BLIP의 성능을 보여주며, 이전의 state-of-the-art 모델인 SeViLa 및 FrozenBiLM (NG+) (Xiao et al., 2023)과 비교한다.
Table 4. NExT-GQA test set. 첫 네 모델은 NExT-QA에서 명시적으로 fine-tune된 것으로 알려져 있다. Section 4.3의 논의를 참조하라.
| Method | mIoU | IoP@. 5 | A@GQA | A@QA |
|---|---|---|---|---|
| Finetuned on Dataset | ||||
| SeViLA (2024) | 21.7 | 22.9 | 16.6 | 68.1 |
| FrozenBiLM (2023) | 9.6 | 23.7 | 17.5 | 70.8 |
| Chrono-BLIP | 28.7 | 19.4 | 73.9 | |
| Zero-Shot | ||||
| Uniform 60F | 21.1 | 21.1 | 8.7 | 7.1 |
| LLoVi (2023a) | 21.5 | 38.0 | 26.8 | - |
| DeVi (2024) | 22.3 | 37.9 | 28.0 | 71.6 |
| Chrono-GPT | 36.5 | 50.8 | 42.1 | 79.3 |
mIoU 점수를 살펴보면, FrozenBiLM 모델보다 19.13% 더 우수한 성능을 보인다. 실제로 mIoU에서 FrozenBiLM과 SeViLa는 각각 uniform baseline보다 성능이 낮거나 비슷하다. Chrono-BLIP (localizer)과 SeViLa의 localizer는 모두 QVH로만 사전학습되었다. 그러나 Chrono-BLIP은 SeViLa보다 7.03% 더 높은 mIoU를 달성하여 새로운 질문 기반 설정에 훨씬 더 잘 적응한다. 마지막으로, Chrono-BLIP은 A@GQA 지표에서 이전 SOTA보다 1.90% 더 우수한 성능을 보인다.
동일한 프로토콜에 따라, 우리는 Chrono-GPT 모델을 zero-shot 설정에서 평가한다. ablation 결과에서 보듯이, 우리의 timestamp 디자인은 Chrono-GPT에 강력한 zero-shot moment retrieval 능력을 제공한다.
 Figure 3. (1,2) 정확한 multi-window moment retrieval. (3) Chrono-BLIP은 두 개의 정확한 순간과 하나의 잘못된 순간을 예측한다. (4) Chrono-BLIP은 쿼리와 부분적으로만 일치하는 순간을 예측한다. (5) Chrono-BLIP은 QVH로 학습되었음에도 NExT-GQA에서 out-of-distribution 예시를 성공적으로 예측한다. (1)은 Charades-STA에서, (2)부터 (4)는 QVHighlights에서, (5)는 NExT-GQA에서 가져온 것이다.
Figure 3. (1,2) 정확한 multi-window moment retrieval. (3) Chrono-BLIP은 두 개의 정확한 순간과 하나의 잘못된 순간을 예측한다. (4) Chrono-BLIP은 쿼리와 부분적으로만 일치하는 순간을 예측한다. (5) Chrono-BLIP은 QVH로 학습되었음에도 NExT-GQA에서 out-of-distribution 예시를 성공적으로 예측한다. (1)은 Charades-STA에서, (2)부터 (4)는 QVHighlights에서, (5)는 NExT-GQA에서 가져온 것이다.
기초 모델의 강력한 QA 능력과 결합하여, 우리는 NExT-GQA에서 이전 연구들 (Zhang et al., 2023a; Qin et al., 2024)보다 새로운 state-of-the-art 결과를 달성했다. 이들 연구 또한 각각 GPT-4와 GPT-4o를 활용했다. Chrono-GPT를 사용한 NExT-GQA 설정과 다양한 설계 결정에 대한 ablation은 Appendix C.3에 자세히 설명되어 있다.
4.4. Qualitative Results
Figure 3은 ChronoBLIP의 정성적 결과들을 보여준다. 이 결과들은 여러 개의 시간 구간(window)을 예측하는 능력(2, 3), 학습되지 않은 데이터 분포에 대한 일반화 능력(5), 그리고 잘못된 segment를 예측하는 등의 실패 사례(3), **낮은 이미지 해상도로 인해 prompt에 부분적으로만 부합하는 경우(4)**를 보여준다.
(4)번 예시에서 쿼리는 "A woman in long brown hair is trying on a black hat in a shop"이다. Chrono-BLIP은 여성이 상점에서 명확하게 보이는 순간을 예측하지만, 모자를 써보는 장면은 예측하지 못한다. Ground truth segment에서는 여성이 모자를 써보고 있지만, 멀리 떨어져 있어 명확하게 보이지 않는다.
더 많은 비디오와 localization 결과는 Appendix D에 제공되어 있다.
5. Conclusion
우리는 Chrono를 소개한다. Chrono는 비디오-언어 MLLM에 시간 정보를 제공하기 위한 간단한 모델-불가지론적(model-agnostic) 청사진으로, 이를 통해 moment retrieval 및 grounded video question answering과 같은 task를 수행할 수 있게 한다. 우리는 원래 이미지-텍스트로 사전학습된 Chrono 모델이 비디오-언어 modality에 쉽게 적응할 수 있으며, 시각 및 텍스트 토큰으로 구성된 간단한 interleaved 토큰 시퀀스 형태로 시각 및 시간 정보를 통합하는 입력 설계로부터 큰 이점을 얻는다는 것을 보여준다. 구체적으로, fine-tuned Chrono-BLIP은 널리 사용되는 moment retrieval 벤치마크에서 state-of-the-art 결과를 달성하며, zero-shot Chrono-GPT는 grounded video question answering에서 새로운 SoTA를 기록한다. 광범위한 ablation 연구를 통해, 우리는 놀랍게도 우리의 간단한 모델-불가지론적 설계가 task-specific 모델 아키텍처, 광범위한 비디오 사전학습, 비디오 스크립트와 같은 추가 입력 신호, 또는 새로운 시간 embedding 모듈과 같은 측면에 의존하는 모든 이전 SOTA 방법들을 능가한다는 것을 발견했다. 우리는 Chrono의 이러한 다재다능한 sequence-to-sequence 설계가 비디오-언어 모델에서 시간을 인코딩하는 데 있어 기본적인 baseline 또는 잠재적인 best practice로 작용하고, 이미지-텍스트로 사전학습된 MLLM을 비디오 이해 task에 활용하는 추가 연구를 촉발하기를 희망한다.
6. Limitations and Impact
우리는 대규모 사전학습된 MLLM인 BLIP2 (Li et al., 2023)와 GPT-4o (OpenAI, 2024a)를 활용하므로, 이 모델들이 학습했을 수 있는 편향이나 유해한 고정관념(예: 성별 또는 인종 편향)의 존재를 배제할 수 없다. 우리 모델이 유해한 고정관념에 해당하는 순간들을 감지할 가능성이 있다. 따라서 실제 적용 시에는 주의 깊게 모델을 사용할 것을 권장한다. 또한, 우리 모델은 일부 형태의 감시(surveillance)와 관련하여 오용될 수 있는 가능성이 있다.
7. Acknowledgements
본 연구는 LOEWE-Start-Professur (LOEWE/4b//519/05.01.002-(0006)/94), LOEWE-Spitzen-Professur (LOEWE/ 4a//519/05.00.002 및 독일 연방 교육 연구부(Federal Ministry for Education and Research)가 후원하는 Multimodal Reliable AI 분야의 Alexander von Humboldt Professorship로부터 부분적으로 자금을 지원받았다.
A. Appendix Overview
Appendix에서는 본 연구의 추가적인 세부 사항과 실험 결과를 상세히 설명한다. 구체적으로 다음 내용을 다룬다:
- Appendix B에서는 실험 설정에 대해 자세히 설명하며, 사용된 벤치마크와 재현성을 위한 학습 및 zero-shot 설정 세부 정보를 제공한다.
- Appendix C.1에서는 학습 가능한 파라미터 수의 영향에 대한 ablation 결과를 제시한다.
- Appendix C.2에서는 Charades-STA (Table 7) 및 QVHighlights (Table 8)에 대한 zero-shot GPT-4o의 timestamp 설계에 대한 추가적인 상세 ablation을 다룬다. 긴 비디오의 경우, timestamp를 interleave하는 방식이 moment localization 성능을 크게 향상시킨다는 것을 발견했으며, 이는 본 논문의 주요 결과와 일치한다.
- GPT-4o 쿼리에 사용된 정확한 prompt를 Figure 4에 제시한다.
- Appendix D에서는 추가적인 정성적 예시를 제공한다.
- 마지막으로, 벤치마크의 예시 비디오와 Chrono-BLIP의 예측된 moment localization을 보여주는 별도의 비디오 몽타주와 코드를 각각 제공한다.
B. Experimental Setup
B.1. Benchmarks
Charades-STA (Gao et al., 2017)는 평균 길이가 30.6초인 9,848개의 비디오를 포함한다. 이 데이터셋은 평균 8.1초 길이의 moment와 평균 7.22단어 길이의 query를 가진 16,128개의 annotation으로 구성된다. 데이터셋은 원래 학습(12,408)과 테스트(3,720)의 두 가지 분할로 나뉘어 있다. 학습 중 테스트 세트에 과적합되는 것을 방지하기 위해, 우리는 학습 세트의 일부를 새로운 validation 세트로 지정했다. validation 세트에 사용된 비디오는 학습 세트에 포함되지 않는다. 우리의 새로운 데이터셋 분할은 학습, validation, 테스트를 위한 분할로 구성되며, 각각 11,166, 1,242, 3,720개의 annotation을 포함한다. 공정한 비교를 위해, ablation 연구를 완료한 후, 우리는 최종 모델을 원래의 학습 세트에서 학습시키고 테스트 세트의 수치를 보고한다. 재현성을 위해 우리의 분할을 공유할 것이다.
QVHighlights (Lei et al., 2021a)는 가장 최근의 벤치마크 중 하나로, 150초 길이의 비디오 10,148개를 포함한다. 비디오는 YouTube 비디오에서 잘라냈으며, 각 비디오는 관련 moment를 설명하는 평균 11.3단어 길이의 query가 적어도 하나씩 주석되어 있다. 대상 window의 평균 길이는 24.6초이다. 데이터셋은 학습, validation, 테스트 세트로 분할되며, 각각 7,218, 1,150, 1,542개의 query를 포함한다. 이 벤치마크는 하나의 query가 비디오 내의 여러 moment와 연관될 수 있기 때문에 도전적이다. 테스트 세트의 정답은 공개되지 않아 공정한 벤치마크를 보장한다. 테스트 분할에 대한 평가는 평가 서버에 예측을 제출해야만 측정할 수 있다.
ActivityNet Captions (Krishna et al., 2017)는 평균 길이가 2분인 20,000개의 비디오를 포함한다. 이 데이터셋은 72,000개의 segment로 구성되며, 각 segment는 평균 13.5단어 길이의 caption으로 사람이 주석을 달았다. 데이터셋은 학습(37,421), val_1(17,505), val_2(17,031)의 세 가지 분할로 나뉜다. (Yan et al., 2023)을 따라, 우리는 학습 분할을 학습에, val_1을 validation에, val_2를 테스트에 사용한다.
NExT-GQA (Xiao et al., 2023)는 NExT-QA (Xiao et al., 2021) 벤치마크를 확장하여, validation 및 테스트 세트의 질문에 답하는 데 관련 있는 비디오 내 moment에 대한 temporal grounding을 제공함으로써 약한 지도 학습(weakly-supervised) 데이터셋으로 만든다. 이 데이터셋은 NExT-QA의 원래 학습 분할을 포함하며, 34,132개의 샘플로 구성된다. validation 세트는 3,358개의 질문과 3,931개의 segment를 포함하는데, 이는 하나의 샘플이 잠재적으로 여러 관련 moment를 가질 수 있지만, 그중 어떤 단일 moment를 예측하더라도 올바른 예측으로 간주된다는 의미이다. 즉, 모든 관련 moment를 예측할 필요는 없다. 테스트 세트는 5,553개의 질문과 6,600개의 segment를 가진다. segment의 평균 길이는 validation 세트의 경우 7.3초, 테스트 세트의 경우 6.7초이다.
B.1.1. Metrics
MR에 가장 일반적으로 사용되는 지표는 Recall@K와 다양한 IoU(Intersection over Union) 임계값에서 계산된 **mAP(mean average precision)**이다. Recall@K 지표는 상위 K개의 예측된 segment 중 ground truth segment와 임계값보다 큰 temporal IoU를 갖는 segment의 비율로 정의된다. 최근 연구들(Lee & Byun, 2023; Lei et al., 2021a; Moon et al., 2023a;b)에 따라, 우리는 더 도전적인 R1@0.5 및 R1@0.7 점수를 보고한다. 이는 각각 IoU 임계값 0.5 및 0.7에서의 Recall@1 점수에 해당하며, mIoU(mean IoU) 점수도 함께 보고한다. 이러한 선행 연구들을 따라, QVHighlights 데이터셋에서의 MR에 대해서는 IoU 임계값 0.5 및 0.75에서의 mAP 점수와 평균 mAP를 각각 보고한다.
NExT-GQA (Xiao et al., 2023)는 다음 두 가지 지표를 도입한다: (i) IoP(Intersection over Prediction): 예측된 관련 순간(moment)과 ground truth 간의 temporal intersection 길이와 예측된 순간 자체의 길이 간의 비율로 정의된다. (ii) Accuracy@GQA (A@GQA): IoP가 0.5보다 큰 grounding score를 갖는 질문에 대해 올바르게 답변한 정확도이다. IoP는 일반적인 IoU 지표를 완화하여, union 대신 예측 길이만을 고려하여 intersection을 계산한다. 이 지표는 매우 짧은 순간 예측을 장려하며, 전체 관련 순간의 정확한 커버리지에는 관심이 없다.
B.2. Implementation Details
이 섹션에서는 Chrono-BLIP의 fine-tuning 및 평가 세부 사항과 Chrono-GPT의 추가적인 zero-shot 평가 요소를 제시한다.
B.2.1. Training Details for BLIP2
데이터셋의 상대적으로 작은 규모를 고려하여, 우리는 모델의 30억 개 파라미터 LLM backbone 전체를 fine-tuning하는 대신, parameter-efficient fine-tuning (Hu et al., 2022)을 활용하여 1,900만 개의 파라미터만 학습시켰다 (Section 3.2 참조).
우리의 목표는 생성형 언어 모델링 task이므로, 모델은 사소한 형식 불일치(formatting inconsistency)를 출력할 수 있으며, 이는 적절히 처리되지 않으면 예측을 무효화할 수 있다. (Yang et al., 2023)과 유사하게, 우리는 모델의 출력에 휴리스틱을 적용하여 예측의 사소한 결함을 정리하는 후처리(post-process) 과정을 거친다.
Charades-STA의 경우, 각 비디오에서 20개의 비디오 프레임을 추출하는데, 이는 128개의 프레임을 요구하는 이전 연구 (Yan et al., 2023)보다 현저히 적은 양이다. 우리는 최대 20 epoch 동안 32개의 샘플 배치 크기로 학습했으며, 이는 4개의 A100-80GB GPU에 분산되어 약 20 GPU 시간이 소요되었다. QVHighlights와 ActivityNet Captions의 경우, 각 비디오에서 60개의 비디오 프레임을 추출하는데, 이는 이전 연구 (Moon et al., 2023a;b)에서 요구하는 것보다 적은 양이다. 우리는 최대 50 epoch 동안 32개의 샘플 유효 배치 크기로 학습했으며, 이는 8개의 A100-80GB GPU에 분산되고 accumulated gradients를 4로 설정(즉, GPU당 하나의 샘플)하여 약 170 GPU 시간이 소요되었다.
우리는 1e-8의 learning rate (lr)로 시작하여, 총 반복 횟수의 10% 동안 선형 lr warmup을 3e-4까지 수행한 다음, cosine lr decay를 적용한다. 우리는 AdamW (Loshchilov & Hutter, 2017) optimizer를 활용하고, 학습 중에는 프레임을 무작위로 샘플링한다.
B.2.2. Video processing
우리는 Salesforce lavis repository를 기반으로 하며, 비디오에서 프레임을 무작위 및 균일하게 추출하는 그들의 구현을 활용한다. 학습 중에는 데이터 증강(data augmentation)의 수단으로 프레임을 무작위로 샘플링하여 각 배치에서 모델이 보는 프레임을 변경한다. 추론 시에는 전체 비디오를 균등하게 커버하기 위해 균일하게 샘플링한다. 무작위 샘플링의 경우, 먼저 개의 타임스탬프를 균일하게 추출하는데, 이때 첫 번째 타임스탬프는 이고 마지막 타임스탬프는 video_length이다. 그 후, 각 인접한 타임스탬프 쌍 사이에서 하나의 프레임을 무작위로 샘플링하여 최종적으로 n개의 무작위 샘플링된 프레임을 얻는다. 이러한 무작위 샘플링 과정은 균일 샘플링 과정에 노이즈를 추가하는 것으로 볼 수 있다.
학습 중에는 각 프레임을 ** 픽셀로 무작위로 자르고 크기를 조절(crop and resize)**한다. 그런 다음, **고정된 평균을 빼고 지정된 표준 편차로 나누어 각 프레임을 정규화(normalize)**한다. 추론 시에는 무작위 자르기 및 크기 조절을 적용하지 않는다. 오직 정규화만 적용한다.
Table 5. Charades-STA (Gao et al., 2017), QVHighlights (QVH) (Lei et al., 2021a), ActivityNet (ANet) (Krishna et al., 2017)의 기본 모델과 NeXT-GQA (Xiao et al., 2023)의 answerer 학습을 위한 하이퍼파라미터. LR: Learning rate.
| Hyperparameter | Charades-STA | QVH/ ANet/ NeXT-GQA |
|---|---|---|
| Batch size | 32 | 32 |
| Epochs | 20 | 50 |
| LR | ||
| LR warmup | Linear | Linear |
| LR warmup steps | 10% | 10% |
| LR decay | Cosine | Cosine |
| Optimizer | AdamW | AdamW |
| Weight decay | 0.05 | 0.05 |
| # input frames | 20 | 60 |
| # beams | 5 | 5 |
Table 6. LoRA Rank 및 학습 가능한 파라미터 수에 대한 Ablation.
| Rank (# train. params) | R1@0.5 | R1@0.7 | mIoU |
|---|---|---|---|
| 66.03 | 43.03 | 56.59 | |
| 65.71 | 43.59 | 56.78 | |
| 67.28 | |||
| 45.38 | 57.35 |
B.2.3. Finetuning Hyperparameters
Table 5는 하이퍼파라미터의 상세 목록을 보여준다. 모든 모델 및 ablation에 대해 공정한 비교를 보장하기 위해, 특정 파라미터를 ablation하는 경우(Table 1)를 제외하고는 표에 제시된 하이퍼파라미터를 고수한다. 벤치마크에 따라 변경되는 유일한 하이퍼파라미터는 learning rate warmup을 위한 step 수와 입력 프레임 수이다. warmup step 수는 데이터셋 크기에 따라 달라지며, 총 step 수의 10%에 해당한다. 즉,
B.2.4. Zero-Shot GPT-4o experiment details
우리는 API를 통해 gpt-4o-2024-08-06에 쿼리한다. 모든 쿼리에 대해 low image details를 사용한다. high image details를 사용하면 이미지당 더 많은 token이 할당되므로 결과가 더 좋을 가능성이 있지만, 자세히 탐구하지는 않았다. 모든 쿼리에 대해 temperature 0과 최대 생성 길이를 사용하며, 다른 API 파라미터는 기본값으로 설정한다. temperature 0을 사용하더라도 **일부 비결정성(non-determinism)**이 관찰되지만, 모든 결과는 통계적으로 유의미하며, 가능한 경우 최소 두 번의 실행을 평균하여 얻은 값이다.
C. Additional Ablations
C.1. Effect of number of trainable parameters
본 논문에서는 parameter-efficient fine-tuning 기법을 사용하여 적은 수의 파라미터만 학습한다고 언급하였다. 실제로 우리는 **LoRA (Hu et al., 2022)**를 활용하며, rank를 8로 설정하고 이를 대형 language model의 모든 linear layer에 적용하여 약 1,900만 개의 학습 가능한 파라미터를 얻는다.
Table 6에서는 다양한 LoRA rank와 그에 따른 학습 가능한 파라미터 수의 영향을 보여준다. rank를 16으로 설정하여 두 배 많은 파라미터를 학습하더라도 유의미한 성능 향상은 없었다 (4행). 반면, rank를 4 또는 2로 설정하여 더 적은 파라미터(각각 1,000만 또는 600만 개)를 학습하면 Chrono의 성능이 저하되었다 (1행 및 2행).
Table 7. Charades-STA Validation set에 대한 Ablation study. GPT-4o를 사용한 zero-shot 평가에서 timestamp 디자인의 영향.
| Rep. | Prec. | Inter. | R1@0.5 | R1@0.7 | mIoU | |
|---|---|---|---|---|---|---|
| (1) | Rel | Dec | 32.85 | 11.38 | 37.78 | |
| (2) | Abs | Dec | 32.38 | 13.30 | 36.99 | |
| (3) | Rel | Int | 34.68 | 38.04 | ||
| (4) | Abs | Int | 29.91 | 11.28 | 33.43 | |
| (5) | Rel | Int | 11.20 | |||
| (6) | Abs | Int | 28.35 | 11.29 | 35.43 | |
| (7) | Abs | Dec | 28.72 | 10.74 | 34.78 |
Table 8. QVHighlights Validation set에 대한 Ablation study. GPT-4o를 사용한 zero-shot 평가에서 timestamp 디자인의 영향.
| # | Rep. | Prec. | Inter. | R1@0.5 | R1@0.7 | mIoU |
|---|---|---|---|---|---|---|
| (1) | Rel | Dec | 48.39 | 26.06 | 46.45 | |
| (2) | Abs | Dec | 44.19 | 24.58 | 43.82 | |
| (3) | Rel | Int | 30.42 | 14.90 | 33.91 | |
| (4) | Abs | Int | 36.77 | 20.68 | 37.41 | |
| (5) | Rel | Int | ||||
| (6) | Abs | Int | 61.68 | 41.80 | 57.12 | |
| (7) | Abs | Dec | 58.77 | 40.16 | 55.83 |
C.2. Timestamp design for GPT-4o
Table 7과 Table 8은 GPT-4o에 zero-shot prompting을 적용할 때(Figure 4에 제시된 prompt 사용), 다양한 timestamp 표현 방식, 정밀도, 그리고 timestamp를 프레임과 interleave할지 여부에 대한 ablation 결과를 보여준다. Table 8은 우리의 주요 가설을 뒷받침한다. 즉, 프레임 사이에 timestamp를 interleave하는 것이 zero-shot 상황에서도 더 나은 localization 성능으로 이어진다는 것이다.
Charades-STA의 경우, Table 7에서 보듯이 interleaving의 효과는 덜 명확하다. 우리는 이러한 차이가 Charades-STA에서는 (더 짧은 비디오에서) 단 20개의 프레임만 사용하는 반면, QVHighlights에서는 GPT-4o가 (수 분 길이의 비디오에서) 60개의 프레임을 관찰하기 때문에 발생한다고 가정한다. 이는 appended timestamp가 참조하는 프레임으로부터 더 멀리 떨어져 있게 되어, Table 8에서 interleaving frame timestamp와의 간격이 더 커진다는 것을 의미한다. 그러나 Charades-STA에서는 토큰 프레임과 appended timestamp 사이의 거리가 짧아 그 영향이 미미한 것으로 보인다. 또한, 연속적인 프레임이 interleaved timestamp가 있는 일련의 프레임보다 GPT-4o에게 더 분포 내(in-distribution)에 있을 수 있으므로, 매우 짧은 프레임 시퀀스에서는 단순히 timestamp를 append하는 것이 이점을 제공할 수 있다고 가정할 수 있다. 이는 Chrono에서 보여주듯이 fine-tuning 시 학습하기 쉽고 사용되는 일부 timestamp 결정 방식이 zero-shot 모델에서는 out-of-distribution이 되어 성능이 저하될 수 있음을 보여준다.
더 작은 규모로, 상대적(relative) timestamp와 절대적(absolute) timestamp에 대해서도 유사한 경향을 관찰할 수 있다. 상대적 timestamp에 대한 선호도는 짧은 비디오에서 더 높지만, 긴 비디오에서도 유지된다. 우리는 Charades-STA에서 상대적 timestamp의 더 나은 성능이 짧은 비디오에서 더 높은 시간적 해상도를 제공하기 때문일 수 있다고 가정한다. 궁극적으로, Chrono에서 보여주듯이 fine-tuning 시에는 절대적 timestamp가 더 좋을 수 있지만, GPT-4o를 zero-shot으로 사용할 때는 상대적 timestamp가 비슷하거나 더 우수하다는 것을 발견했다. 마지막으로, 두 데이터셋 모두에서 최고의 구성은 소수점 정밀도(decimal precision)보다 정수 정밀도(integer precision)를 사용한다. 후자가 더 높은 시간적 해상도를 제공함에도 불구하고 이러한 결과는 Table 1에서 보여준 fine-tuning 시의 결과와 일치한다.
이러한 발견은 zero-shot 및 fine-tuned 설정에서 다양한 MLLM에 대한 신중한 시퀀스 설계의 중요성과, 비디오 내 시간적 localization을 위한 MLLM의 능력에 미치는 영향을 보여준다.
C.3. Chrono design for NExT-GQA
NExT-GQA에 대한 최적의 Chrono-GPT 설정은 단일 stage를 사용한다. 즉, grounding과 질문 답변을 동일한 모델 응답에서 요청한다. 우리는 이 방식이 2단계 방식보다 더 나은 성능을 보인다는 것을 발견했다. 2단계 방식에서는 모델이 먼저 moment retrieval을 수행한 다음, 질문에 답변하도록 요청받는다. 이러한 결과는 두 번째 stage가 window를 확대하고, 전체적으로 더 많은 프레임을 사용하며, 첫 번째 stage를 context에 유지할 수 있는 경우에도 동일하게 나타났다.
우리는 최종 결과에 대해 1.4FPS를 사용한다. 이는 모든 비디오에 대해 60프레임을 사용하는 것과 비교하여 전체 데이터셋(평균 길이가 약 40초)에서 동일한 수의 프레임을 사용한다.
Table 9. Moment retrieval이 Video QA에 도움이 되는가?
우리는 NExT-GQA validation split에서 1000개의 샘플을 무작위로 선택했다. 모델에게 질문에 답변하는 동시에 moment retrieval을 수행하도록 요청하는 것이 정확도를 향상시키는지를 테스트했다. 또한, 프레임에 타임스탬프를 부여하는 것이 여기에 영향을 미 미치는지도 테스트했다. Chrono-GPT는 절대 시간(absolute time)과 함께 interleaved timestamps를 사용한다. 모든 모델은 1.4FPS의 단일 stage를 사용한다.
| MR | Time | mIoU | mIoP | IoP@.5 | A@GQA | A@QA |
|---|---|---|---|---|---|---|
| - | - | - | - | 79.80 | ||
| 22.47 | 29.85 | 27.13 | 22.03 | 80.07 | ||
절대 interleaved timestamps를 사용하는 것은 temporal grounding을 크게 향상시키며, 결과적으로 grounded accuracy를 향상시킨다. 또한, Table 9에서 볼 수 있듯이, grounding에 의해 threshold되지 않은 전체 정확도(overall accuracy)에도 약간의 도움이 된다. 이는 비디오를 처리하는 모델에 temporal grounding 기능을 포함하는 것이 더 큰 해석 가능성을 제공할 뿐만 아니라, video QA와 같은 다른 task에서의 전반적인 성능도 향상시킬 수 있음을 시사한다.
Abstract
User [Frame at seconds: ] [Frame at seconds: ] [...] [Frame at seconds: ] The video lasts duration seconds. Query: query. Given the video and the query, find the relevant windows. Think step by step. Reason about the events in the video and how they relate to the query. After your reasoning, output 'ANSWER: <your answer> ' in the format specified in the task prompt. Always provide a non-empty answer after your thoughts. If you think the event does not take place in the video, give your best guess, as otherwise the evaluation will be marked as incorrect. Never provide an empty list for <your answer>. The descriptions of moments are sometimes imprecise, so retrieve the closest moment. If you don't see an event remotely similar to the description, guess what is the most likely moment given the context. For instance, for cutting onion this could be between the time we see that the scene takes place in the kitchen and the time we see the onions being boiled in the pan. The answer should be in the format of a list indicating the start and end of a window of moment, [start_window, end_window], for instance [0, . If you detect multiple windows for the same moment, choose the most relevant one. It's important your final answer only contains one window. It is very important that the answer is in this format, otherwise the evaluation will fail.
Assistant
Answer
Figure 4. 단일 창 순간 현지화(single-window moment localization)를 위해 GPT-4o에 사용된 Prompt. 파란색 텍스트는 변수를 나타낸다.
D. Additional Qualitative Results
이 섹션에서는 추가적인 정성적 결과들을 제시하고, 향후 연구에서 다룰 수 있는 모델의 한계점들을 논의한다. 독자의 편의를 위해 각 예시에 대한 논의는 해당 캡션에 포함하였다. 예시 1부터 6까지는 QVHighlights (Lei et al., 2021a)에서 가져왔으며, 예시 6부터 10까지는 Charades-STA (Gao et al., 2017)에서 가져왔다.
본 논문의 본문에서와 같이, ground truth target은 점선으로, 예측된 window는 실선으로 표시하였다.
A girl is excited about showing her bed with a big red heart in it.
 Figure 5. 우리는 모델이 간헐적인 중단과 함께 반복적으로 발생하는 3개의 개별적인 순간을 인식하고 구별하는 능력을 관찰한다. 각 예측된 순간은 해당 자연어 쿼리를 묘사한다.
Figure 5. 우리는 모델이 간헐적인 중단과 함께 반복적으로 발생하는 3개의 개별적인 순간을 인식하고 구별하는 능력을 관찰한다. 각 예측된 순간은 해당 자연어 쿼리를 묘사한다.
Donald Trump speaks in large circular table.
 Figure 6. Chrono-BLIP은 학습 데이터셋에 Donald Trump가 포함된 쿼리가 6개뿐임에도 불구하고, Donald Trump라는 특정 공인을 인식할 수 있다.
Figure 6. Chrono-BLIP은 학습 데이터셋에 Donald Trump가 포함된 쿼리가 6개뿐임에도 불구하고, Donald Trump라는 특정 공인을 인식할 수 있다.
Man and woman sit on opposite sides of circle desk.
 Figure 7. 우리 모델은 ground truth moment와 일치하지 않는 세 번째 window를 예측하지만, 이 예측은 실제로 정확하며 쿼리를 잘 묘사하고 있다.
Figure 7. 우리 모델은 ground truth moment와 일치하지 않는 세 번째 window를 예측하지만, 이 예측은 실제로 정확하며 쿼리를 잘 묘사하고 있다.
Soldiers escort people through the wilderness.
 Figure 8. 이 비디오에는 쿼리를 묘사하지 않는 2초 미만의 짧은 컷을 포함하는 두 그룹의 관련 순간들이 있다. 150초 길이의 비디오에 대해 60프레임 해상도(2.5초마다 한 프레임이 보이는 것에 해당)로는 Chrono-BLIP이 해당 컷을 감지하지 못하고, 두 개의 짧은 순간들을 포함하는 두 개의 긴 순간들을 예측한다. 더욱이, 우리 모델은 ground truth label과 일치하지 않는 세 번째 window(빨간색)를 예측한다. 예측된 순간은 실제로 군인들을 묘사하지만, 그들은 다른 사람들을 호위하고 있지 않다.
Figure 8. 이 비디오에는 쿼리를 묘사하지 않는 2초 미만의 짧은 컷을 포함하는 두 그룹의 관련 순간들이 있다. 150초 길이의 비디오에 대해 60프레임 해상도(2.5초마다 한 프레임이 보이는 것에 해당)로는 Chrono-BLIP이 해당 컷을 감지하지 못하고, 두 개의 짧은 순간들을 포함하는 두 개의 긴 순간들을 예측한다. 더욱이, 우리 모델은 ground truth label과 일치하지 않는 세 번째 window(빨간색)를 예측한다. 예측된 순간은 실제로 군인들을 묘사하지만, 그들은 다른 사람들을 호위하고 있지 않다.
A herd of bison is shown crossing the road.
 Figure 9. 우리 모델은 프레임 샘플링 해상도를 고려할 때, 긴 비디오 내의 매우 짧은 순간이나 고주파 점프 컷(high-frequency jump cuts)을 예측하는 데 어려움을 겪는다.
Figure 9. 우리 모델은 프레임 샘플링 해상도를 고려할 때, 긴 비디오 내의 매우 짧은 순간이나 고주파 점프 컷(high-frequency jump cuts)을 예측하는 데 어려움을 겪는다.
a person awakens in a bedroom.
 Figure 10. 매우 모호한 쿼리가 주어졌을 때, 우리 모델의 예측은 ground truth와 일치한다.
Figure 10. 매우 모호한 쿼리가 주어졌을 때, 우리 모델의 예측은 ground truth와 일치한다.
a person closes a front door.
 Figure 11. 우리 모델은 남자가 현관문을 닫는 행동을 인식하지 못한다. 이는 문이 매우 어둡고 잘 보이지 않기 때문이라고 추정한다. 우리 모델은 문이 명확하게 보이고 닫힌 순간을 예측한다.
Figure 11. 우리 모델은 남자가 현관문을 닫는 행동을 인식하지 못한다. 이는 문이 매우 어둡고 잘 보이지 않기 때문이라고 추정한다. 우리 모델은 문이 명확하게 보이고 닫힌 순간을 예측한다.
the person puts the broom down.
 Figure 12. 우리 모델은 비디오 초반에 빗자루를 내려놓는 동작을 인식하지 못하고, 남자가 빗자루를 다시 집어 들고 있는 순간을 예측한다.
Figure 12. 우리 모델은 비디오 초반에 빗자루를 내려놓는 동작을 인식하지 못하고, 남자가 빗자루를 다시 집어 들고 있는 순간을 예측한다.
the person begins sneezing.
 Figure 13. Chrono-BLIP은 사람이 재채기하는 순간을 인식한다. Ground truth는 false이다.
Figure 13. Chrono-BLIP은 사람이 재채기하는 순간을 인식한다. Ground truth는 false이다.
TU Berlin, Berlin, Germany TU Darmstadt & Hessian.ai, Darmstadt, Germany University of Edinburgh, UK. Correspondence to: Boris Meinardus boris.meinardus00@gmail.com.
Our code is available under https://github.com/sudo-Boris/mrBlip.
Eval server: https://codalab.lisn.upsaclay.fr/competitions/6937