이미지와 오디오의 Joint Slot Attention을 활용한 음원 위치 특정(SSL) 성능 개선
본 논문은 이미지 내에서 소리의 출처를 찾는 Sound Source Localization (SSL) 태스크의 성능을 개선하는 새로운 방법을 제안합니다. 기존 방법들은 노이즈를 포함한 전체 오디오 특징을 사용해 정확도에 한계가 있었으나, 이 연구는 joint slot attention을 이미지와 오디오에 동시에 적용하여 특징을 소리와 관련된 target과 관련 없는 off-target으로 분해합니다. 오직 target slot만을 contrastive learning에 사용하여 소음의 영향을 줄이고, cross-modal attention matching을 통해 두 modality 간의 정렬을 강화하여 더 정확한 음원 위치 특정을 가능하게 합니다. 그 결과, 여러 SSL 벤치마크에서 최고 성능을 달성했습니다. 논문 제목: Improving Sound Source Localization with Joint Slot Attention on Image and Audio
Kim, Inho, et al. "Improving Sound Source Localization with Joint Slot Attention on Image and Audio." Proceedings of the Computer Vision and Pattern Recognition Conference. 2025.
Improving Sound Source Localization with Joint Slot Attention on Image and Audio
Abstract
**음원 위치 파악(Sound Source Localization, SSL)**은 이미지 내에서 소리의 근원지를 찾는 task이다. 위치 파악을 위한 레이블(localization label)이 부족하기 때문에, SSL 분야의 사실상 표준(de facto standard)은 이미지와 오디오를 각각 단일 임베딩 벡터로 표현하고, 이를 contrastive learning을 통해 SSL을 학습하는 방식이었다.
이를 위해 기존 연구들은 로컬 이미지 feature 중 하나를 이미지 임베딩으로 샘플링하고, 모든 로컬 오디오 feature를 통합하여 오디오 임베딩을 얻는 방식을 사용했다. 하지만 이러한 방식은 입력에 실제 타겟과 관련 없는 노이즈나 배경이 존재하기 때문에 최적과는 거리가 멀다.
우리는 이러한 고질적인 문제를 해결하기 위해 이미지와 오디오에 대한 joint slot attention을 활용하는 새로운 SSL 방법을 제안한다. 구체적으로, 두 개의 slot이 이미지 및 오디오 feature에 경쟁적으로 attend하여 이들을 타겟(target) 및 비타겟(off-target) 표현으로 분해하고, 오직 이미지와 오디오의 타겟 표현만을 contrastive learning에 사용한다. 또한, 우리는 이미지와 오디오의 로컬 feature를 더욱 정렬(align)하기 위해 cross-modal attention matching을 도입한다.
우리의 방법은 SSL을 위한 세 가지 공개 벤치마크에서 거의 모든 설정에서 최고의 성능을 달성했으며, cross-modal retrieval 분야에서도 모든 기존 연구를 크게 능가했다.
1. Introduction
사람은 시야 내에서 소리가 어디에서 오는지 쉽게 식별한다. 이러한 능력은 주변 환경과의 상호작용을 촉진하는 인간 지각의 핵심 측면이며, 자율 주행 및 로봇 공학과 같은 다양한 비전 애플리케이션에서도 요구된다 [10, 28, 34]. 이에 영감을 받아, 많은 연구들 [1, 3, 6, 12, 14, 15, 21, 22, 25, 26, 29-33]이 Sound Source Localization (SSL), 즉 쌍을 이루는 이미지 내에서 소리의 근원지를 segmentation mask 형태로 찾아내는 task를 연구해왔다.
이미지-오디오 쌍 데이터에 대한 음원 주석(sound source annotation) 비용이 엄청나게 비싸기 때문에, 기존 방법들 [6, 21, 31, 33]은 음원 레이블 없이 이미지-오디오 쌍 데이터만을 사용하여 SSL을 학습하는 데 집중해왔다. 이를 위해 그들은 이 task를 multiple instance learning [2, 13, 20]으로 간주하고,
 Figure 1: 이전 연구와 우리 연구의 차이점. SSL의 contrastive learning을 위해, 우리 방법은 관련 이미지 영역과 오디오 세그먼트 쌍을 식별하고 활용하는 반면, 이전 연구는 local image feature와 global audio feature를 활용한다.
Figure 1: 이전 연구와 우리 연구의 차이점. SSL의 contrastive learning을 위해, 우리 방법은 관련 이미지 영역과 오디오 세그먼트 쌍을 식별하고 활용하는 반면, 이전 연구는 local image feature와 global audio feature를 활용한다.
주어진 이미지-오디오 쌍에서 이미지의 적어도 하나의 패치(patch)가 오디오와 관련이 있다고 가정한다. 그런 다음, global audio feature와 가장 유사한 local image feature로 이미지를 표현하고, 이러한 feature들을 사용하여 contrastive learning [24, 27]을 통해 SSL을 학습한다 (Figure 1(a)).
이러한 접근 방식이 효과적임이 입증되었지만, 개선할 여지가 많다. 첫째, 오디오에는 두 가지 modality가 공유하는 대상 소리뿐만 아니라, 노이즈나 이미지 외부의 소리와 같은 관련 없는 소리가 포함될 수 있다. 이러한 경우, contrastive learning에 global audio feature를 사용하면 이미지와 오디오 feature 간의 정확한 정렬(alignment)을 방해한다. 둘째, contrastive learning에서 이미지를 단일 local feature로만 표현하면, 모델이 음원 전체가 아닌 작은 식별 가능한 부분만 찾아내게 되어 [35] SSL 정확도가 저하될 수 있다.
이러한 한계점을 해결하기 위해, 우리는 slot attention [17]에 기반한 새로운 SSL 방법을 제안하며, 이는 Figure 1(b)에 개념적으로 설명되어 있다. slot attention에서 slot은 무작위로 샘플링되거나 학습 가능한 embedding으로, 입력 feature를 점진적으로 집계하기 위해 서로 경쟁하며, 이를 통해 feature를 구별되고 배타적인 표현으로 분해한다. 이에 영감을 받아, 우리는 두 개의 학습 가능한 slot을 사용하여 이미지와 오디오 feature를 각 modality별로 두 개의 distinct slot representation으로 공동 분해한다. 하나는 대상(target)을 위한 것이고, 다른 하나는 나머지(off-target)를 위한 것이다. 구체적으로, 우리는 첫 번째 slot을 target slot으로 지정하여, 두 modality에 걸쳐 공유되는 음원과 관련된 정보에 집중하도록 유도한다. slot attention의 배타적 할당(exclusive assignment) 속성은 **두 번째 slot(off-target slot)**이 이미지 배경이나 오디오의 관련 없는 소리와 같은 나머지 요소들을 포착하도록 지시한다. 그런 다음, 이미지와 오디오에서 각각 얻은 두 target slot representation을 사용하여 contrastive learning을 통해 SSL을 학습한다. 단일 global audio feature만을 사용했던 이전 연구와 달리, 우리 방법은 오디오의 관련 부분(즉, target slot)만을 활용하여 더 정확한 SSL을 가능하게 한다. 또한, 이미지의 target slot이 단일 위치가 아닌 음원 영역 전체를 포괄하므로, 우리 방법은 localization이 작은 식별 가능한 부분으로 축소되는 문제를 피한다.
 Figure 2: 제안된 방법의 개요.
첫째, 이미지 및 오디오 feature는 이미지 및 오디오 encoder에 의해 추출되며, slot attention의 key 및 value로 사용된다.
slot attention에서는 두 개의 학습 가능한 slot이 query로 사용되어 입력 feature에 attention을 유도하는 동시에 서로 경쟁하며, feature를 modality별로 target 및 off-target representation으로 분해한다.
그런 다음, target representation만을 사용하여 contrastive learning으로 모델을 학습하고, 두 modality 간의 feature-level alignment를 위해 cross-modal attention matching을 추가로 수행한다.
테스트 시 localization을 위해, audio target representation과 image feature 간의 attention map을 생성한다.
slot attention 학습을 위한 일부 세부 사항(예: decoder 및 slot reconstruction을 위한 loss)은 명확성을 위해 생략되었다.
Figure 2: 제안된 방법의 개요.
첫째, 이미지 및 오디오 feature는 이미지 및 오디오 encoder에 의해 추출되며, slot attention의 key 및 value로 사용된다.
slot attention에서는 두 개의 학습 가능한 slot이 query로 사용되어 입력 feature에 attention을 유도하는 동시에 서로 경쟁하며, feature를 modality별로 target 및 off-target representation으로 분해한다.
그런 다음, target representation만을 사용하여 contrastive learning으로 모델을 학습하고, 두 modality 간의 feature-level alignment를 위해 cross-modal attention matching을 추가로 수행한다.
테스트 시 localization을 위해, audio target representation과 image feature 간의 attention map을 생성한다.
slot attention 학습을 위한 일부 세부 사항(예: decoder 및 slot reconstruction을 위한 loss)은 명확성을 위해 생략되었다.
Target slot representation이 주어지면, audio의 target slot representation을 query로 사용하여 이미지 feature map에 attention map을 생성함으로써 SSL이 수행된다 (Figure 2(b)). 정확한 픽셀 수준 localization을 위해, audio의 target slot은 관련 개별 이미지 feature에서 파생된 key와 잘 정렬되어야 한다. 이 점에서 target slot만을 사용하는 contrastive learning은 audio target slot과 개별 이미지 feature를 연결하지 않으므로 불충분하다. 따라서 우리는 cross-modal attention matching이라는 추가 학습 전략을 도입한다. 이 전략은 audio target slot과 입력 이미지 feature 간의 cross-modal attention map이, 본질적으로 잘 정렬된 image target slot과 입력 이미지 feature 간의 intra-modal attention map을 근사하도록 유도한다. 다시 말해, 동일한 modality의 query와 key로 생성되어 target을 더 잘 localize하는 intra-modal attention map을 사용하여 SSL 예측(즉, cross-modal attention map)에 대한 pseudo-supervision을 제공한다. cross-modal alignment를 더욱 촉진하기 위해, 우리는 이 전략을 audio modality에도 적용한다.
우리 모델은 FlickrSoundNet [4]과 VGG-Sound [5] 두 가지 데이터셋으로 학습되었으며, Flickr-SoundNet-Test [4], VGG-SS [5], AVSBench [36] 세 가지 벤치마크에서 평가되었다. 이 모델은 세 가지 평가 벤치마크의 거의 모든 설정에서 state of the art를 달성했다. 또한, 우리 모델은 cross-modal retrieval에서 이전의 모든 연구보다 큰 차이로 우수한 성능을 보였는데, 이는 우리 모델이 단순한 saliency detector가 아니라 SSL을 위해 이미지와 오디오를 적절하게 연결하는 방법을 학습했음을 시사한다 [31]. 요약하자면, 우리 방법의 기여는 세 가지이다:
- 우리는 slot attention을 통해 이미지 및 오디오 modality에서 음원과 관련된 feature를 공동으로 식별하고 추출하는 새로운 SSL 모델을 제안한다.
- 우리는 또한 개별 입력 feature에 대한 효과적인 cross-modal alignment를 가능하게 하여 localization 성능을 향상시키는 cross-modal attention matching을 제안한다.
- 우리 모델은 세 가지 SSL 벤치마크의 거의 모든 설정에서 state of the art를 달성했으며, cross-modal retrieval 성능을 크게 향상시켰다.
2. Related Work
**음원 위치 파악(Sound source localization)**은 오디오 입력에서 들리는 소리의 출처에 해당하는 이미지 내 특정 영역을 식별하는 것을 목표로 한다. 오디오-시각 데이터셋 구축은 비용이 많이 들기 때문에, 음원 위치 파악 연구는 contrastive learning을 위해 이미지-오디오 쌍만을 사용하는 self-supervised learning 접근 방식으로 발전해 왔다 [1, 6, 12, 14, 16, 21, 22, 26, 29-31, 33].
초기 연구인 [29]는 audio-aware image feature와 global audio feature 간의 contrastive learning을 통해 이 task를 다룬다. audio-aware image feature는 global audio feature와 image feature map 간의 정규화된 내적을 통해 **대응 맵(correspondence map)**을 계산하여 얻어진다. Chen et al. [6]은 대응 맵에 미분 가능한 임계값(differentiable threshold)을 적용하여 audio-aware feature와 다른 image feature를 분리하고, 후자를 contrastive learning에서 hard negative로 취급하여 위치 파악 성능을 향상시키는 방법을 제안한다.
최근 연구들은 global audio feature와 image feature map에서 선택된 가장 관련성 높은 feature 간의 contrastive learning을 통해 **세분화된 음원 위치 파악(fine-grained sound source localization)**에 초점을 맞추고 있다 [21, 22, 31, 33]. Mo와 Morgado [21]는 사전학습된 시각 모델을 활용하는 **후처리 기법(post-processing technique)**을 통해 오디오-시각 대응 맵(audio-visual correspondence map)을 정제하는 방법을 제안한다. Sun et al. [33]은 inter-modal 및 intra-modality 유사도 행렬에 평균 절대 오차(mean absolute error) 정규화를 적용하여 false negative에 대한 인식을 높이는 regularizer를 도입한다. Senocak et al. [31]은 multi-view augmentation과 nearest neighbor search를 활용하여 contrastive learning을 위한 여러 positive 쌍을 구축함으로써 위치 파악 성능을 유지하고 cross-modal retrieval을 향상시키는 cross-modal alignment 방법을 제안한다. 이러한 방법들은 가장 관련성 높은 이미지 feature와 contrastive learning을 사용하여 음원을 대략적으로 식별하는 데 도움을 주지만, 포괄적인 표현을 포착하는 데는 종종 부족하여 위치 파악 능력을 저해한다. 또한, global audio feature에만 의존하는 것은 노이즈가 존재할 때 contrastive learning을 오도하여 잘못된 이미지 feature를 강조할 수 있다.
보완적인 방향으로, 몇몇 연구들은 **외부 사전 지식(external prior knowledge)**을 사용하거나 심지어 기성(off-the-shelf) segmentation 모듈을 활용하여 고품질 위치 파악 결과를 달성한다 [25, 26]. 또한, 몇몇 연구들은 optical flow [9], 텍스트 입력 [19] 또는 ground truth category [23]와 같은 추가 정보를 사용하여 음원 위치 파악을 수행한다. 이러한 연구들과 달리, 우리의 방법은 외부 사전 지식이나 기성 모델에 의존하지 않고도 음원 위치 파악을 효과적으로 수행할 수 있다.
위에서 언급된 문제들을 해결하기 위해, 우리는 slot attention 메커니즘에 기반한 음원 위치 파악 프레임워크를 제안한다. Slot attention [17]은 **비지도 객체 중심 학습(unsupervised object-centric learning)**을 위해 제안되었으며, 반복적인 attention과 slot 간의 경쟁을 통해 입력 feature를 명확하고 상호 배타적인 구성 요소로 효과적으로 분해한다. 이에 영감을 받아, 우리는 이미지 및 오디오 feature 모두에 slot attention을 적용하여 감독 없이 음원과 관련된 feature와 관련 없는 feature로 분해한다.
3. Proposed Method
Figure 2에서 보여주듯이, 우리 모델은 크게 두 부분으로 구성된다:
- feature 추출을 위한 이미지 및 오디오 인코더,
- joint slot attention 메커니즘을 포함하는 joint feature decomposition 모듈.
먼저, 이미지와 오디오 쌍이 각 인코더에 입력되어 이미지 및 오디오 feature를 추출한다 (Sec. 3.1). 각 모달리티의 feature는 joint slot attention을 사용하여 두 개의 개별적인 slot representation으로 분해된다: 하나는 **타겟(target)**을 위한 slot이고, 다른 하나는 **나머지(rest)**를 위한 slot이다 (Sec. 3.2). 이 slot representation은 contrastive learning 및 cross-modal attention matching의 입력으로 사용되어 학습되며 (Sec. 3.3), 이 과정에서 false negative를 효과적으로 처리한다 (Sec. 3.4). 마지막으로, 오디오의 타겟 slot representation을 사용하여 이미지 feature map에 대한 attention을 계산하여 음원의 위치를 파악한다 (Sec. 3.5).
3.1. Feature Extraction
를 이미지-오디오 쌍의 학습 데이터셋이라고 하자. 여기서 는 크기의 이미지이고, 는 주파수 해상도 와 시간 길이 를 갖는 해당 오디오 스펙트로그램이며, 은 데이터셋 내의 총 쌍의 개수를 나타낸다.
Feature 추출을 위해 별도의 **이미지 인코더 와 오디오 인코더 **가 사용된다.
- 이미지 인코더는 에 대한 **이미지 feature **를 추출한다.
- 오디오 인코더는 에 대한 **오디오 feature **를 추출한다.
여기서 와 는 각각 이미지 feature map의 높이와 너비이고, 는 오디오 feature의 길이이며, 는 이미지 및 오디오 feature의 차원이다.
3.2. Joint Feature Decomposition
Slot attention [17]은 각 slot이 입력 feature를 점진적으로 집계하기 위해 경쟁하여, 입력 feature를 **서로 구별되고 배타적인 표현(distinct and exclusive representations)**으로 분해하는 attention 메커니즘이다. 이 아이디어를 바탕으로, **공동 feature 분해(joint feature decomposition)**를 위해 우리는 **joint slot attention (JSA)**을 제안한다. JSA는 이미지 및 오디오 feature를 각 modality에 대해 두 개의 구별되는 slot 표현으로 공동 분해한다. 이를 달성하기 위해, 우리는 두 modality에서 공유되는 두 개의 초기 slot 을 가진 slot attention을 사용한다. 또한, 첫 번째 slot은 음원(sound source)과 관련된 feature를 포착하는 target slot으로 지정하고, 다른 하나는 나머지 feature를 포착하는 off-target slot으로 지정한다. JSA의 전체 파이프라인은 두 modality에서 동일하므로, 간결성을 위해 이미지에 대해서만 모듈을 설명한다.
JSA는 먼저 입력 이미지 feature 를 투영하여 다음 연산을 적용함으로써 해당 key 와 value 를 도출한다:
여기서 는 -차원 임베딩을 얻기 위한 선형 투영(linear projection) layer이다. 각 반복 에 대해, query 는 초기 slot 를 가진 slot에 선형 투영을 적용하여 도출되며, 이는 다음과 같다:
여기서 는 모든 반복에 대해 공유되는 선형 투영 layer이다. slot attention 행렬 는 주어진 query 와 key 의 내적을 취하고, 차원 의 제곱근으로 스케일링하여 다음과 같이 계산된다:
여기서 는 key 인덱스이고, 는 slot 인덱스이다. 이어서, slot attention 행렬 에 가중 평균이 활용된다:
그런 다음, 업데이트된 slot 은 Gated Recurrent Unit (GRU) [7]을 사용하여 계산되며, 을 hidden state로, 를 입력으로 하여 다음과 같이 계산된다:
마지막으로, slot은 residual connection에 의해 업데이트된다:
전체 과정은 입력 feature가 특정 slot에 바인딩되도록 유도하여, 각 slot이 **상호 배타적인 표현(mutually exclusive representation)**을 형성하도록 보장한다. JSA의 최종 출력은 이미지 slot 및 이미지 query 이며, 여기서 는 target slot이고 는 off-target slot이다. 동일한 과정이 오디오 feature 를 사용하여 오디오 modality에 적용되어, 오디오 slot 및 오디오 query 를 생성한다. 이 과정은 공유된 초기 slot에서 시작하므로, 초기 slot은 두 modality 간의 **공동 feature(joint features)**를 효과적으로 학습할 수 있다. 간결성을 위해 최종 query에 대한 아래첨자 은 생략하여, 및 로 표기한다.
3.3. Learning Objectives
Target Slot을 활용한 Contrastive Learning.
우리는 InfoNCE loss [24, 27]를 사용하여 target slot 기반의 contrastive learning을 수행한다. 이는 target slot이 이미지와 오디오로부터 사운드 소스에 관련된 feature를 공동으로 식별하도록 유도한다.
를 유사도 함수라고 할 때, 로 정의되며, 여기서 는 temperature hyperparameter이다.
**contrastive learning loss **는 다음과 같다:
여기서 는 미니배치 내 데이터의 개수를 나타내며, negative pair는 미니배치 내에서 동일한 원본 쌍에 속하지 않는 시각 및 오디오 feature의 조합을 의미한다.
이미지 target slot은 타겟 영역의 전체 feature를 포착하므로, 이미지의 특정 discriminative 부분에만 집중하는 것을 방지한다. 또한, 오디오 target slot은 소스와 관련된 사운드만 포착하므로, 소스와 관련 없는 사운드를 학습하는 문제를 방지한다.
Cross-modal Attention Matching.
Sec. 3.5에서 설명하듯이, localization 결과는 오디오 target slot과 이미지 feature 간의 cross-modal attention을 활용하여 도출된다. 정확한 사운드 소스 localization을 위해서는 오디오 target slot이 관련 이미지 feature로부터 계산된 key와 적절하게 정렬(align)되어야 한다.
contrastive learning은 서로 다른 modality 간의 target slot representation 정렬을 장려하지만, 오디오 target slot과 이미지 feature 간의 정렬은 보장하지 않아 localization 정확도를 저해할 수 있다.
우리는 cross-modal attention matching을 통해 이 문제를 해결한다. 이는 cross-modal attention map이 intra-modal attention map과 유사하도록 유도하여 두 modality 간의 feature-level 정렬을 개선한다.
이를 위해 먼저 cross-modal 및 intra-modal attention matrix를 계산한다. 구체적으로, 오디오 쿼리 와 시각 키 를 사용하여 Eq. (3) 및 Eq. (4)와 동일한 방식으로 오디오 및 시각 modality 간의 cross-modal attention matrix를 계산한다. 이 cross-modal attention matrix를 로 표기하며, 여기서 는 의 길이다.
이후, 오디오 target query와 시각 key 간의 attention 가중치를 나타내는 cross-modal attention을 얻기 위해 의 첫 번째 열만 활용한다. 이 cross-modal attention은 다음과 같이 정의된다:
마찬가지로, 시각 modality 내의 intra-modal attention matrix의 경우, 와 를 사용하여 intra-attention matrix 를 계산한다. 그런 다음, 이미지 target query와 시각 key 간의 attention 가중치를 나타내는 intra-modal attention은 다음과 같이 정의된다:
cross-modal 정렬을 더욱 촉진하기 위해, 이 전략을 오디오 modality에도 대칭적으로 적용한다.
최종적으로 cross-modal attention matching loss는 다음과 같이 공식화된다:
여기서 는 stop-gradient 연산을 나타낸다. 는 cross-modal 및 intra-modal attention 간의 불일치를 최소화하여, 정확한 localization을 위한 두 modality 간의 강력한 feature-level 정렬을 촉진한다.
Slot Divergence.
slot attention에서 target slot과 off-target slot 간의 다양성(diversity)은 각 slot이 서로 배타적인(mutually exclusive) 영역을 효과적으로 포착하도록 충분히 커야 한다. 따라서 우리는 slot 간의 더 큰 다양성을 장려하는 slot divergence loss를 도입한다.
**slot divergence loss **는 다음과 같다:
이는 서로 다른 slot embedding이 충분히 비유사하도록 보장하여, target slot이 사운드 소스를 더욱 효과적으로 localization할 수 있도록 한다.
Slot Reconstruction.
slot attention에서 성공적인 feature reconstruction은 각 slot이 입력 데이터의 고유하고 독립적인 부분을 성공적으로 포착했음을 의미하며, 이는 slot attention 메커니즘이 입력을 개별 slot representation으로 효과적으로 분해했음을 뜻한다. 이는 각 slot이 입력 내의 특정 객체 또는 영역을 정확하게 나타낸다는 것을 나타낸다.
이러한 조건을 장려하기 위해, 우리는 다음과 같이 **slot reconstruction loss **를 적용한다:
여기서 와 는 각각 이미지 및 오디오 feature를 위한 decoder이다. 이 decoder들은 ReLU 활성화 함수를 가진 소수의 MLP layer로 구성된다.
이 decoder들은 학습 시에만 사용되는 보조 모듈이며, 추론(inference)에는 필요하지 않다는 점에 유의해야 한다.
전체 loss는 , 및 의 조합이며, 다음과 같이 주어진다:
여기서 , 및 는 loss 항들의 가중치를 조절하는 hyperparameter이다.
3.4. Mitigating False Negatives
일반적으로, 쌍을 이루지 않는(unpaired) 이미지와 오디오는 모두 contrastive training에서 negative 샘플로 간주된다. 그러나 이들 중 일부는 의미적으로 잘 매칭되는 false negative이므로, 이들을 negative로 처리하면 부정적인 영향을 초래한다 [33]. 따라서 우리는 타겟 slot의 -reciprocal nearest neighbors를 활용한 false negative 완화 전략을 제안한다.
로부터 파생된 이미지 타겟 slot 에 대해, 우리는 **-reciprocal nearest neighbors 집합 **를 다음과 같이 정의한다:
여기서 는 cosine similarity를 사용하여 계산된 의 -nearest neighbors이다. 마찬가지로, 오디오 타겟 slot 간의 -reciprocal nearest neighbors 집합, 즉 도 유도될 수 있다. **예측된 false negative 집합 **는 다음과 같이 정의된다:
에 있는 샘플들은 와 유사한 이미지 및 오디오 타겟 slot을 모두 가지고 있기 때문에, false negative에 속할 가능성이 높다. 우리는 이러한 예측된 false negative들을 Eq. (7)의 contrastive learning에서 제외한다.
3.5. Inference
추론 시에는 **오디오 타겟 슬롯과 입력 이미지 feature 간의 attention을 나타내는 **가 활용된다. 구체적으로, 이 attention은 **원본 이미지 크기로 보간(interpolate)**되며, 점수가 하이퍼파라미터 를 초과하는 픽셀들이 선택되어 localization 결과를 생성한다.
또한, object-guided localization [21]과 달리, 우리는 외부 사전 지식에 의존하지 않고 localization 결과를 개선하기 위한 **새로운 localization refinement 전략인 Image-Query based Refinement (IQR)**을 제안한다. IQR은 이미지 타겟 슬롯과 입력 이미지 feature 간의 attention을 사용하여 타겟을 포함할 가능성이 있는 영역을 추정한다. 이는 해당 영역이 실제로 소리의 근원지인지 여부와 관계없이, 타겟에 유리한 이미지 내의 사전 영역을 식별하는 데 사용될 수 있다. IQR에 의해 도출된 정제된 결과는 로 표기되며, 다음과 같이 주어진다:
여기서 는 음원 localization 결과와 잠재적 음원 영역 간의 균형을 조절하는 역할을 한다.
4. Experiment
4.1. Experiment Setup
데이터셋 (Datasets)
학습에는 **Flickr-SoundNet [4]과 VGG-Sound [5]**가 사용된다.
Flickr-SoundNet은 약 2백만 개의 제약 없는 Flickr 비디오를 포함하며, VGG-Sound는 약 20만 개의 비디오 클립을 포함한다.
학습을 위해 각 데이터셋에서 1만 개와 14만 4천 개의 서브셋을 각각 사용한다.
평가에는 이전 연구들 [6, 21, 31, 33]에 따라 **Flickr-SoundNet-Test [4], VGG-SS [5], AVSBench [36]**가 사용된다.
Flickr-SoundNet-Test는 수동으로 레이블링된 bounding box를 가진 250개의 오디오-시각 쌍을 포함한다.
VGG-SS는 220개 카테고리에 걸쳐 약 5천 개의 오디오-시각 쌍을 포함한다. VGG-SS는 카테고리 ground truth를 제공하므로, cross-modal retrieval 성능 평가에도 사용된다.
AVSBench는 픽셀 단위의 이진 분할 맵을 가진 약 5천 개의 비디오를 포함한다.
이전 연구 [6]에 따라, 비디오 클립의 중간 프레임이 이미지로 사용된다.
오디오의 경우, 중간 5초가 추출되어 16kHz 샘플링 레이트에서 257개의 주파수 bin을 가진 log spectrogram으로 변환된다.
네트워크 아키텍처 (Network Architecture)
**이미지 인코더와 오디오 인코더 모두 ResNet-18 [11]**이 채택되었다.
이미지 인코더는 ImageNet [8]으로 사전학습된 모델을 fine-tuning한 것이며, 오디오 인코더는 scratch부터 학습되었다.
두 인코더 모두 projection을 위한 추가적인 convolutional layer를 포함하며, 오디오 인코더는 주파수 축을 따라 pooling을 위한 MaxPooling layer도 포함한다.
하이퍼파라미터 설정 (Hyperparameter Settings)
우리는 **AdamW optimizer [18]**를 사용하며, **learning rate는 , weight decay는 **로 설정한다.
학습 중 mini-batch size는 256으로 설정되며, **이미지 및 오디오 feature의 크기 및 **는 각각 다음과 같다:
| Trainset | Method | OGL | VGG-SS | Flickr-SoudNet | ||
|---|---|---|---|---|---|---|
| cIoU | AUC | cIoU | AUC | |||
| Flickr SoundNet 10k | Attention10k [29] | - | - | 43.60 | 44.90 | |
| CoursetoFine [26] | - | - | 52.20 | 49.60 | ||
| AVObject [1] | - | - | 54.60 | 50.40 | ||
| LVS [6] | - | - | 58.20 | 52.50 | ||
| EZ-VSL [21] | 19.86 | 30.96 | 62.24 | 54.74 | ||
| FNAC [33] | 35.27 | |||||
| Ours | 38.66 | 85.20 | 65.26 | |||
| EZ-VSL [21] | 37.61 | 39.21 | 81.93 | 62.58 | ||
| FNAC [33] | 40.97 | 84.73 | 64.34 | |||
| Ours | 39.16 | 40.51 | 87.60 | 66.50 | ||
| Flickr SoundNet 144 k | Attention10k [29] | - | - | 66.00 | 55.80 | |
| DMC [12] | - | - | 67.10 | 56.80 | ||
| LVS [6] | - | - | 69.90 | 57.30 | ||
| HardPos [30] | - | - | 75.20 | 59.70 | ||
| EZ-VSL [21] | 30.27 | 35.92 | 72.69 | 58.70 | ||
| FNAC [33] | 33.93 | 37.29 | 78.71 | 59.33 | ||
| Alignment [31] | - | - | ||||
| Ours | 37.01 | 39.42 | 86.00 | 65.16 | ||
| EZ-VSL [21] | 40.23 | 83.13 | 63.06 | |||
| FNAC [33] | 41.10 | 83.93 | 63.06 | |||
| Alignment [31] | - | - | ||||
| Ours | 40.15 | 40.75 | 89.20 | 64.50 |
| Trainset | Method | OGL | VGG-SS | Flickr-SoudNet | ||
|---|---|---|---|---|---|---|
| cIoU | AUC | cIoU | AUC | |||
| VGGSound 10k | LVS [6] | - | - | 61.80 | 53.60 | |
| EZ-VSL [21] | 25.84 | 33.68 | 63.85 | 54.44 | ||
| FNAC [33] | ||||||
| Ours | 37.84 | 39.82 | 86.00 | 64.90 | ||
| EZ-VSL [21] | 38.71 | 39.80 | 78.71 | 61.53 | ||
| FNAC [33] | 82.13 | |||||
| Ours | 41.02 | 41.29 | 87.60 | 65.42 | ||
| VGGSound 144 k | Attention10k [29] | 18.50 | 30.20 | - | - | |
| DMC [12] | 29.10 | 34.80 | - | - | ||
| AVObject [1] | 29.70 | 35.70 | - | - | ||
| LVS [6] | 34.40 | 38.20 | 73.50 | 59.00 | ||
| HardPos [30] | 34.60 | 38.00 | 76.80 | 59.20 | ||
| EZ-VSL [21] | 34.38 | 37.70 | 79.51 | 61.17 | ||
| SLAVC [22] | 37.22 | - | 83.20 | - | ||
| FNAC [33] | 39.50 | 39.66 | 84.73 | |||
| Alignment [31] | 39.94 | 40.02 | 79.60 | 63.44 | ||
| NoPrior [14] | 41.4 | - | - | |||
| Ours | 40.62 | 41.66 | 83.60 | 64.68 | ||
| EZ-VSL [21] | 38.85 | 39.54 | 83.94 | 63.60 | ||
| SLAVC [22] | 39.67 | - | 86.40 | - | ||
| FNAC [33] | 41.85 | 40.80 | 64.30 | |||
| Alignment [31] | 42.64 | 82.40 | 64.60 | |||
| Ours | 42.56 | 42.46 | 84.80 | 64.82 |
Table 1. Flickr-SoundNet-10k, 144k 및 VGGSound-10k, 144k 데이터셋으로 학습된 모델의 정량적 결과. 이전 연구 결과는 [14, 31, 33]에서 가져왔다. 우리 방법의 결과는 **ImageQuery 기반 Refinement (IQR)**를 적용한 후의 성능을 나타낸다. OGL이 표시된 결과는 object-guided localization [21]을 적용한 후의 성능을 나타낸다.
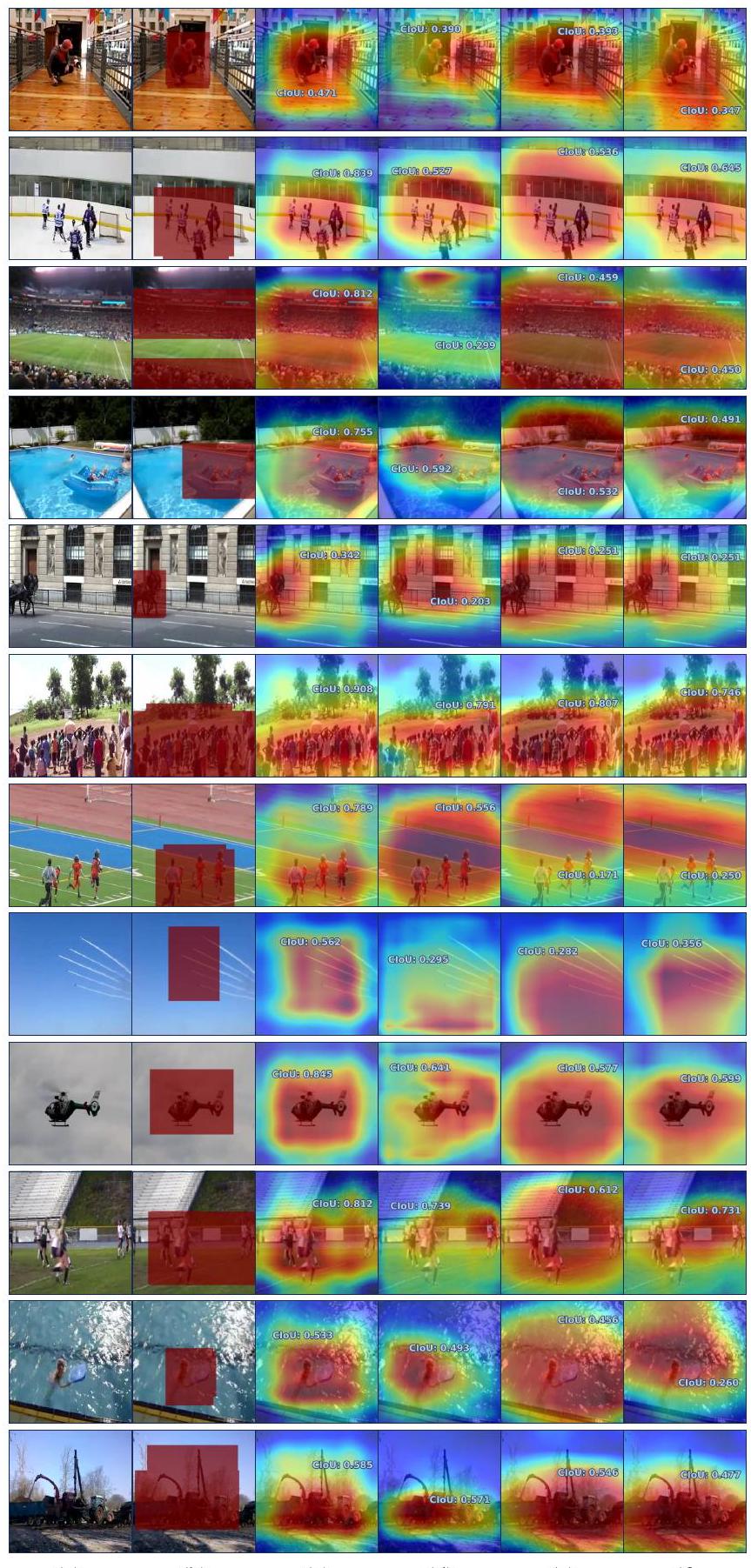
 Figure 3. Flickr-SoundNet-Test [4] 및 VGG-SS [5]에서의 사운드 localization 결과. (a) 입력 이미지. (b) Ground-Truth. (c) Ours. (d) Alignment [31]. (e) FNAC [33]. (f) EZ-VSL [21]. 정성적 결과는 각각 Flickr-144k 및 VGGSound-144k로 학습된 모델에서 얻었다. 모든 시각화는 refinement 없이 얻은 결과이다.
Figure 3. Flickr-SoundNet-Test [4] 및 VGG-SS [5]에서의 사운드 localization 결과. (a) 입력 이미지. (b) Ground-Truth. (c) Ours. (d) Alignment [31]. (e) FNAC [33]. (f) EZ-VSL [21]. 정성적 결과는 각각 Flickr-144k 및 VGGSound-144k로 학습된 모델에서 얻었다. 모든 시각화는 refinement 없이 얻은 결과이다.
****로 설정된다. Eq. (7)의 는 0.03으로 설정된다. Eq. (11)의 는 각각 ****로 설정된다. Eq. (14)의 는 0.6으로 설정된다. Eq. (13)의 값은 20으로 설정된다. slot attention mechanism의 반복 횟수 은 5로 설정된다.
평가 지표 (Evaluation metric)
우리는 localization 정확도를 평가하기 위해 **Consensus Intersection over Union (cIoU) 임계값 0.5에서의 평균 정밀도(average precision)**를 측정한다.
또한, AUC 점수는 다양한 임계값에 걸친 전반적인 성능 측정치를 제공하는 데 사용된다.
4.2. Quantitative Results
Flickr-SoundNet 및 VGGSound. 이 섹션에서는 우리의 방법을 이전의 self-supervised SSL 접근 방식과 비교한다. 우리는 Flickr-SoundNet 및 VGGSound의 하위 데이터셋(각각 10k 및 144k 크기)으로 모델을 학습시켰고, Flickr-SoundNetTest 및 VGG-SS에서 성능을 평가했다. Table 1에서 볼 수 있듯이, 우리 모델은 대부분의 설정에서 state-of-the-art 성능을 달성한다. 특히, 우리 방법은 평가된 모든 설정에서 AUC 개선을 가져온다. 더욱이, Object-Guided Localization (OGL)을 사용하지 않고도 우리 모델은 이전 방법들과 비교하여 경쟁력 있거나 더 나은 성능을 보여주며, 추가적인 정제 단계 없이도 음원에 집중하는 우리 아키텍처의 견고함을 입증한다.
Heard 110 및 Unheard 110. SSL의 일반화 능력을 평가하기 위해 Heard 110 및 Unheard 110으로 성능을 평가한다. Heard 110 및 Unheard 110은 VGG-SS의 하위 데이터셋으로, 각각 110개의 중복되지 않는 카테고리를 포함한다. 학습 중에는 모델이 한 그룹의 카테고리 세트에 대해서만 학습된다. 학습 중에 본 카테고리로 구성된 하위 데이터셋을 Heard 110이라고 하며, 보지 못한 카테고리로 구성된 하위 데이터셋을 Unheard 110이라고 한다. Table 2에서 볼 수 있듯이, 우리 모델은 추가적인 정제 없이도, 그리고 OGL을 적용한 경우에도 Unheard 110에서 state-of-the-art 성능을 달성한다. 이러한 결과는 우리 모델이 이전 모델들에 비해 우수한 일반화 능력을 가지고 있음을 보여준다.
| Method | OGL | Heard 110 | Unheard 110 | ||
|---|---|---|---|---|---|
| cIoU | AUC | cIoU | AUC | ||
| LVS [6] | 28.90 | 36.20 | 26.30 | 34.70 | |
| EZ-VSL [21] | 31.86 | 36.19 | 32.66 | 36.72 | |
| SLAVC [22] | 35.84 | - | 36.50 | - | |
| Alignment [31] | |||||
| Ours | 38.46 | 40.15 | 40.35 | 41.25 | |
| EZ-VSL [21] | 37.25 | 38.97 | 39.57 | 39.60 | |
| SLAVC [22] | 38.22 | - | 38.87 | - | |
| FNAC [33] | 39.54 | 39.83 | 42.91 | 41.17 | |
| Alignment [31] | 41.85 | ||||
| Ours | 41.60 | 43.11 | 42.04 |
Table 2. Heard 110 및 Unheard 110에 대한 정량적 결과. 이전 연구 결과는 [31, 33]에서 가져왔다. 우리 방법의 결과는 Image-Query based Refinement (IQR) 적용 후의 성능을 나타낸다. OGL이 있는 결과는 object-guided localization 적용 후의 성능을 나타낸다.
| Testset | Method | mIoU | F-score |
|---|---|---|---|
| S4 | LVS [6] | 26.9 | 33.6 |
| EZ-VSL [21] | 27.6 | 34.2 | |
| SLAVC [22] | 28.1 | 34.6 | |
| FNAC [33] | 27.15 | 31.4 | |
| Alignment [31] | |||
| Alignment | 29.3 | 35.6 | |
| Ours |
Table 3. AVSBench에 대한 정량적 결과. 이전 연구 결과는 [31, 33]에서 가져왔다. 는 self-supervised 사전학습된 encoder가 해당 연구에 활용되었음을 나타낸다.
| Method | Audio Image | Image Audio | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| LVS [6] | 3.87 | 12.35 | 20.73 | 4.90 | 14.29 | 21.37 |
| EZ-VSL [21] | 5.01 | 15.73 | 24.81 | 14.20 | 33.51 | 45.18 |
| SSL-TIE [16] | 10.29 | 30.68 | 43.76 | 12.76 | 29.58 | 39.72 |
| SLAVC [22] | 4.77 | 13.08 | 19.10 | 6.12 | 21.16 | 32.12 |
| Alignment [31] | 36.99 | 49.00 | 42.38 | 53.66 | ||
| Alignment | 14.31 | 18.00 | 38.39 | 49.02 | ||
| Ours | 30.61 | 57.87 | 69.37 | 31.70 | 58.43 | 69.81 |
Table 4. VGG-SS에 대한 cross-modal retrieval 결과. 모든 모델은 VGGSound-144K로 학습되었다. 이전 연구 결과는 [31]에서 가져왔다. 는 self-supervised 사전학습된 encoder가 해당 연구에 활용되었음을 나타낸다.
| Trainset | FN Mitigate | VGG-SS | |||
|---|---|---|---|---|---|
| cIoU | AUC | ||||
| VGGSound 144k | 14.95 | 27.02 | |||
| 36.23 | 39.13 | ||||
| 18.69 | 30.03 | ||||
| 15.03 | 28.18 | ||||
| 40.56 | 41.35 | ||||
| 36.14 | 39.31 | ||||
| 20.37 | 30.81 | ||||
| 40.71 | 41.62 |
Table 5. 손실 함수에 대한 상세 ablation study.
| Trainset | Shared | VGG-SS | Flickr | ||
|---|---|---|---|---|---|
| Initial Slots | cIoU | AUC | cIoU | AUC | |
| Flickr-144k | 34.80 | 38.72 | 84.00 | 61.70 | |
| VGGSound-144k | 33.11 | 37.92 | 81.20 | 64.36 | |
Table 6. 공유된 initial slot에 대한 ablation study.
 Figure 4. Flickr-SoundNet에서 의 영향을 보여주는 정성적 결과. (a) 입력 이미지. (b) Ground-Truth. (c) cross-modal attention matching이 없는 결과. (d) cross-modal attention matching이 있는 결과.
Figure 4. Flickr-SoundNet에서 의 영향을 보여주는 정성적 결과. (a) 입력 이미지. (b) Ground-Truth. (c) cross-modal attention matching이 없는 결과. (d) cross-modal attention matching이 있는 결과.
AVSBench. localization mask의 성능을 보다 정확하게 평가하기 위해 segmentation mask를 제공하는 AVSBench에서 성능을 측정했다. 우리 모델은 VGGSound-144k로 학습되었고 AVSBench에서 zero-shot 방식으로 평가되었다. Table 3에서 볼 수 있듯이, 우리는 state-of-the-art 결과를 달성했으며, 특히 mIoU에서 2.03%p, F-score에서 8.7%p의 개선을 보였다.
Cross-modal Retrieval. 이전 연구 [31]에서 논의된 바와 같이, 벤치마크 평가 지표인 cIoU 및 AUC는 더 나은 오디오-시각 의미 이해를 보장하지 않는다. 따라서 우리는 VGG-SS에서 cross-modal retrieval 성능도 평가한다. 우리는 이미지 및 오디오 target slot representation을 추출하고 그들 간의 코사인 유사도를 계산한다. 유사도는 내림차순으로 순위가 매겨지며, 상위 K개의 검색된 오디오 또는 이미지에서 카테고리 레이블을 사용하여 Recall@K 성능을 계산한다. Table 4에서 우리 모델은 cross-modal retrieval에서 이전 state-of-the-art에 비해 상당한 성능 향상을 보여준다. 특히, 우리 모델은 오디오-이미지 검색에서 Recall@1을 16.3%p, 이미지-오디오 검색에서 13.7%p 향상시킨다. 이 결과는 우리 모델이 단순히 이미지 내에서 소리를 낼 가능성이 있는 salient object를 감지하는 것이 아니라, 오디오 입력으로 지정된 target을 효과적으로 찾아낸다는 것을 나타낸다.
 Figure 5. VGG-SS에 대한 cross-modal retrieval의 정성적 결과.
Figure 5. VGG-SS에 대한 cross-modal retrieval의 정성적 결과.
4.3. Ablation Study
Sec. 3.4의 Loss 및 False Negative 완화 전략의 영향
Table 5에서 우리는 각 loss function과 Sec. 3.4에 설명된 전략의 효과를 검증하기 위한 ablation study를 수행하였다. 전반적인 결과는 설계된 loss들과 false negative 완화 전략이 각각 성능 향상에 기여한다는 것을 보여준다. 특히, 를 사용한 실험에서 성능이 크게 향상되었는데, 이는 cross-modality attention matching의 중요성을 강조한다. 또한, 에 대한 ablation study는 slot들을 명시적으로 분리하는 것이 각 slot이 지정된 역할을 더 효과적으로 수행하도록 돕는다는 것을 보여준다.
Shared Initial Slots의 영향
우리는 각 modality에 대해 다른 initial slot을 사용하여 shared initial slot의 영향을 조사하기 위한 ablation study를 수행하였다. Table 6에서 볼 수 있듯이, initial slot을 공유하는 것이 더 나은 성능을 가져왔으며, 이는 이러한 설계 선택이 서로 다른 modality에 걸쳐 음원 관련 정보를 공동으로 포착하는 능력을 촉진한다는 것을 나타낸다.
4.4. Qualitative Results
SSL 결과의 질적 분석
Fig. 3은 Flickr-SoundNet [4] 및 VGG-SS [5] 테스트 세트에서 우리 모델과 이전 연구들의 질적 결과를 시각화한 것이다. 이 결과들은 우리 모델이 음원 객체를 효과적으로 localize하는 능력을 가지고 있음을 보여준다. 특히, 작은 새, 총, 그리고 거리 장면에서 다른 객체들에 둘러싸인 자동차와 같이 다른 모델들이 어려움을 겪는 까다로운 샘플에 대해서도 compact한 localization 결과를 생성한다.
의 질적 분석
Fig. 4는 Flickr-SoundNetTest에서 가 미치는 영향을 보여주는 질적 결과이다. attention map은 audio target slot의 audio query와 이미지 feature에서 파생된 image key 사이에 생성된다. 가 없으면 둘 사이의 정렬(alignment)이 compact한 localization에 불충분하지만, 를 사용하면 정렬이 개선되어 음원의 보다 정확한 localization으로 이어진다.
Cross-modal Retrieval
Fig. 5는 cross-modal retrieval에 대한 우리 모델의 질적 결과를 보여준다. Table 4에서 보여준 인상적인 성능과 일관되게, 우리 모델은 음원 target에 해당하는 semantically 유사한 샘플을 modality 간에 검색하는 강력한 능력을 보여준다.
5. Conclusion
본 논문은 joint slot attention을 활용하여 이미지 및 오디오 feature를 정렬하는 새로운 self-supervised 음원 위치 파악(sound source localization) 방법을 제시한다. 우리의 접근 방식은 이러한 feature들을 target slot과 off-target slot으로 분해하며, 음원 관련 feature를 포착하기 위해 target slot만을 contrastive learning에 사용한다. 또한, 우리는 cross-modal attention matching과 slot divergence loss를 도입하여 위치 파악 정확도를 크게 향상시켰으며, 포괄적인 분석을 통해 우리 모델의 효과를 입증하였다. 향후 연구에서는 우리의 프레임워크를 **다중 음원 위치 파악(multisource sound source localization)**으로 확장하는 것을 목표로 한다.
감사의 글 (Acknowledgement). 본 연구는 한국 과학기술정보통신부의 NRF 과제(RS-2021-NR059830-40%) 및 IITP 과제(RS-2024-00509258-40%, RS-2021-II212068-10%, RS-2019-II191906-10%)의 지원을 받아 수행되었습니다.
Appendix
A. Model Size
이전 연구들과 달리, 우리는 보조 decoder를 포함하는 joint slot attention 모듈을 추가로 사용한다. joint slot attention 모듈은 6.84M 개의 파라미터로 구성되며, 이미지 decoder와 오디오 decoder는 각각 1.05M 개의 파라미터를 가진다. 두 개의 ResNet-18 [11]만을 사용하는 EZ-VSL [21]과 비교했을 때, 우리 모델은 학습 시 39% 더 많은 파라미터를 필요로 한다. 추론 시에는 decoder가 사용되지 않으므로 30% 더 많은 파라미터를 사용한다.
| Method | # of parameters (M) |
|---|---|
| EZ-VSL [21] | 22.87 |
| Ours | 31.82 |
| Ours | 29.71 |
Table 7. 모델 크기. 는 추론 시 사용되는 파라미터 수를 나타낸다.
B. Experiments on Multi-Source Dataset
multisource 데이터셋의 성능을 보다 정확하게 평가하기 위해, 우리는 VGGSound-144k로 모델을 학습시키고 AVSBench MS3에서 zero-shot 방식으로 평가를 수행했다. Table 8에서 볼 수 있듯이, 우리의 방법은 multi-source 데이터셋에서 강력한 성능을 보였으며, 두 개의 target slot을 사용했을 때 서로 다른 객체들을 효과적으로 포착했다. 그러나 학습 데이터셋인 VGGSound-144k가 single-source 데이터셋이기 때문에 target slot을 늘리는 것의 영향은 제한적이었다.
C. Additional Ablation Studies
이 섹션에서는 slot attention 반복 횟수 , 예측된 false negatives , masking ratio, 각 slot의 개수에 대한 ablation study를 수행한다. 모든 실험은 VGGSound-144k [5]로 학습되었고, VGG-SS [5]로 테스트되었다.
Slot Attention 반복 횟수 (Slot Attention Iteration)
우리는 slot attention 반복 횟수 을 변화시키면서 그 효과를 분석한다. Table 9는 5번의 반복이 음원 위치 파악(sound source localization)과 cross-modal retrieval 모두에서 최고의 성능을 달성함을 보여준다. 원래 slot attention [17]의 결과와 유사하게, 반복 횟수가 너무 적거나 너무 많으면 성능이 저하된다.
예측된 False Negatives (Predicted False Negatives)
우리는 개의 reciprocal nearest neighbors가 false negative 완화에 미치는 영향을 를 변화시키면서 측정한다. Table 10은 적절한 값이 false negative를 제외함으로써 성능을 향상시킨다는 것을 보여준다. 그러나 값이 너무 크면 true negative까지 제외할 수 있으며, 이는 contrastive learning에 사용할 수 있는 샘플 수를 줄여 성능 저하로 이어진다. 우리는 음원 위치 파악에서 최고의 결과를 위해 으로 설정하였다.
Masking Ratio
학습 중에 우리는 과적합을 방지하고 성능을 향상시키기 위해 입력 feature의 10%를 학습 가능한 mask token으로 무작위로 대체한다.
| Testset | Method | mIoU | F-Score |
|---|---|---|---|
| LVS [6] | 18.54 | 17.4 | |
| EZ-VSL [21] | 21.36 | 21.6 | |
| MS3 | FNAC [33] | 21.98 | 22.5 |
| SLAVC [22] | 24.37 | 25.56 | |
| Ours | |||
| Ours |
Table 8. MS3 결과. 아래 첨자는 각각 target slot과 off-target slot의 개수를 나타낸다.
| cIoU | AUC | Audio Image | Image Audio | |||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| 1 | 16.36 | 27.81 | 1.12 | 5.78 | 9.89 | 3.47 | 11.65 | 17.82 |
| 3 | 39.59 | 40.78 | 16.17 | 36.27 | 47.91 | 19.45 | 41.55 | 53.88 |
| 5 | ||||||||
| 7 | 39.74 | 41.21 | 23.03 | 46.88 | 58.14 | 24.97 | 49.17 | 61.25 |
| 10 | 34.24 | 38.60 | 7.12 | 19.58 | 28.44 | 7.43 | 24.37 | 35.69 |
Table 9. 반복 횟수 에 대한 ablation study. 회색 행은 본 논문에서 사용된 설정을 나타낸다.
| cIoU | AUC | Audio Image | Image Audio | |||||
|---|---|---|---|---|---|---|---|---|
| R@ 1 | R@5 | R@ 10 | R@ 1 | R@5 | R@ 10 | |||
| 10 | 40.29 | 41.16 | 71.42 | 33.00 | ||||
| 20 | 30.61 | 57.87 | 69.37 | 31.70 | 58.43 | 69.81 | ||
| 30 | 40.15 | 41.14 | 31.87 | 60.06 | 59.78 | 71.23 | ||
| 50 | 40.44 | 41.56 | 28.13 | 55.58 | 67.29 | 29.47 | 56.65 | 68.77 |
Table 10. -reciprocal nearest neighbors에 대한 ablation study. 회색 행은 본 논문에서 사용된 설정을 나타낸다.
| Ratio | cIoU | AUC | Audio Image | Image Audio | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| 0.0 | 37.46 | 40.26 | 8.90 | 24.72 | 34.45 | 10.08 | 29.35 | 42.52 |
| 0.05 | 40.07 | 40.96 | 17.39 | 37.53 | 48.64 | 20.24 | 44.65 | 56.34 |
| 0.1 | 40.71 | 41.62 | 30.61 | 57.87 | 69.37 | 31.70 | 58.43 | 69.81 |
| 0.2 | 33.50 | 38.34 | 9.25 | 23.23 | 32.92 | 9.52 | 27.82 | 39.47 |
| 0.3 | 31.72 | 37.48 | 9.13 | 22.55 | 31.72 | 9.13 | 27.05 | 39.20 |
| 0.5 | 16.56 | 29.22 | 12.54 | 30.46 | 40.29 | 15.08 | 36.51 | 48.31 |
Table 11. Masking ratio에 대한 ablation study. 회색 행은 본 논문에서 사용된 설정을 나타낸다.
우리는 masking ratio를 변화시키면서 이 접근 방식의 영향을 조사한다. Table 11은 학습 가능한 mask를 적은 비율로 사용하는 것이 mask를 전혀 사용하지 않는 것보다 더 나은 성능을 보인다는 것을 보여준다. 그러나 입력 feature를 과도하게 대체하면 정보 손실로 이어져 성능 저하를 초래한다.
각 Slot의 개수 (The Number of Each Slot)
우리는 target slot과 off-target slot의 개수를 변경하여 slot의 효과를 분석한다. Table 12는 slot의 개수가 증가함에 따라 성능이 하락한다는 것을 보여준다. 이는 주로 slot의 개수가 너무 많이 증가하면 입력 분해(input decomposition)에서 slot 간의 경쟁이 심화되기 때문이다. 예를 들어, Fig. 7에 나타난 것처럼 4개의 slot을 사용하면 target 영역이 종종 조각나서, 어떤 target slot도 target을 명확하게 포착하지 못하고, target 또는 off-target slot이 각각 배경 또는 target 영역을 침범하는 경향이 있다.
D. Failure Cases
Fig. 6은 VGG-SS의 실패 사례를 보여준다. attention의 제한된 해상도로 인해 모델은 때때로 작은 객체를 포착하는 데 어려움을 겪는다. 또한, 강한 co-occurrence bias에도 취약하다. 예를 들어, 학습 데이터에서 악기와 사람이 자주 함께 나타나기 때문에, 악기 소리가 주어지면 때때로 둘 다 동시에 식별하는 경우가 발생한다.
 Figure 6. 실패 사례. (a) 입력 (b) Ground-Truth (c) 예측
Figure 6. 실패 사례. (a) 입력 (b) Ground-Truth (c) 예측
E. More Qualitative Results
이 섹션에서는 추가적인 정성적 결과들을 제시한다. Figure 8은 intra-modal attention 결과를 보여주며, target slot과 off-target slot이 특정 영역에 attend함으로써 입력을 효과적으로 분해함을 나타낸다. 또한, 오디오의 경우 target slot이 spectrogram에서 새 소리와 관련된 시간 간격에 집중하는 것을 정성적으로 확인하였다.
추가적으로, Figure 9에서는 SoundNet-Flickr-Test [4] 및 VGG-SS [5]에 대한 추가적인 정성적 결과를 제시하고, Figure 10에서는 VGG-SS에 대한 추가적인 cross-modal retrieval 결과를 보여준다.
더 나아가, Figure 11에서는 의 효과를 보여주기 위해 오디오 target slot과 이미지 feature 간의 cross-modal attention을 적용 유무에 따라 시각화하였다. Figure 11은 가 attention map이 음원에 집중하도록 유도함을 보여준다.
마지막으로, Figure 12는 배치 내에서 예측된 false negative 예시들을 제시한다. Figure 12는 -reciprocal nearest neighbors가 false negative에 속할 가능성이 높음을 보여준다.
 Figure 7. 노란색 경계는 target slot attention을 나타내고, 검은색 경계는 off-target slot attention을 나타낸다.
Figure 7. 노란색 경계는 target slot attention을 나타내고, 검은색 경계는 off-target slot attention을 나타낸다.
| Target | Off-Target | VGG-SS | |
|---|---|---|---|
| cIoU | AUC | ||
| 1 | 1 | ||
| 1 | 2 | 38.91 | 40.69 |
| 1 | 3 | 34.52 | 38.66 |
| 2 | 1 | 40.36 | 41.17 |
| 3 | 1 | 37.50 | 40.11 |
Table 12. 각 slot 개수에 대한 ablation study. 회색 행은 본 논문에서 사용된 설정을 나타낸다.
 Figure 8. Intra-modal attention. (a) 입력 이미지-오디오 쌍 (b) Target slot attention (c) Off-target slot attention
Figure 8. Intra-modal attention. (a) 입력 이미지-오디오 쌍 (b) Target slot attention (c) Off-target slot attention
Flickr-SoundNet-Test
 (f)
(f)
Figure 9. Flickr-SoundNet-Test [4] 및 VGG-SS [5]에 대한 추가적인 음원 위치 파악(sound localization) 결과. (a) 입력 이미지. (b) Ground-Truth. (c) Ours. (d) Alignment [31]. (e) FNAC [33]. (f) EZ-VSL [21]. 정성적 결과는 각각 Flickr-144k로 학습된 모델과 VGGSound-144k로 학습된 모델을 통해 얻어졌다. 모든 시각화는 refinement 없이 얻어진 결과이다.
| Query Image and audio pair | Retrieved Image by the query audio | Retrieved Audio by the query image | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Top 1 | Top 2 | Top 3 | Top 4 | Top 1 | Top 2 | Top 3 | Top 4 | ||
 |  | 10 |  |  |  |  |  |  | |
 |  |  |  |  |  |  |  |  | |
 |  |  |  |  |  | I |  | ||
 |  |  |  |  |  |  |  | ||
 |  |  |  |  |  |  | GBA | ||
 |  |  |  |  |  |  |  | ||
 |  |  |  |  |  |  | |||
 |  |  |  |  |  |  |  |  | |
 | - |  |  |  |  |  |  |  |  |
| 四川 |  |  |  |  |  |  |  | ||
 |  |  |  | <br> Yeultude thanalitr |  |  |  | ||
 |  |  |  |  |  |  |  |  |
Figure 10. VGG-SS [5]에 대한 cross-modal retrieval의 추가적인 정성적 결과. 오디오 spectrogram은 이해하기 어렵기 때문에, 해당 이미지로 시각화하였다.
 Figure 11. VGG-SS [5]에서 의 영향을 보여주는 추가적인 정성적 결과. (a) 입력 이미지. (b) Ground-Truth. (c) cross-modal attention matching이 없는 크기의 attention map. (d) cross-modal attention matching이 없는 크기의 attention map. (e) cross-modal attention matching이 있는 크기의 attention map. (f) cross-modal attention matching이 있는 크기의 attention map.
Figure 11. VGG-SS [5]에서 의 영향을 보여주는 추가적인 정성적 결과. (a) 입력 이미지. (b) Ground-Truth. (c) cross-modal attention matching이 없는 크기의 attention map. (d) cross-modal attention matching이 없는 크기의 attention map. (e) cross-modal attention matching이 있는 크기의 attention map. (f) cross-modal attention matching이 있는 크기의 attention map.
 Figure 12. VGGSound [5]의 예측된 false negative 샘플에 대한 정성적 결과. 동일한 행의 샘플들은 배치 내에서 -reciprocal nearest neighbors를 사용하여 false negative로 예측되었다. 이들은 유사한 이미지 및 오디오 target slot 표현을 가지므로, contrastive learning을 위한 negative pair로 사용되지 않는다.
Figure 12. VGGSound [5]의 예측된 false negative 샘플에 대한 정성적 결과. 동일한 행의 샘플들은 배치 내에서 -reciprocal nearest neighbors를 사용하여 false negative로 예측되었다. 이들은 유사한 이미지 및 오디오 target slot 표현을 가지므로, contrastive learning을 위한 negative pair로 사용되지 않는다.