LATR: 길이를 인지하는 Transformer를 이용한 Temporal Sentence Grounding
Temporal Sentence Grounding (TSG)은 비디오에서 주어진 문장에 해당하는 시간적 구간을 찾는 task입니다. 기존 DETR 기반 모델들은 학습 가능한 query들의 역할이 겹쳐 중복된 예측을 생성하는 문제가 있었습니다. LATR (Length-Aware Transformer)은 각 query가 특정 시간 길이에 전문화되도록 하여 이 문제를 해결합니다. 모델은 query들을 짧은, 중간, 긴 길이를 담당하는 세 그룹으로 나누고, 학습 과정에서 길이 분류 task를 추가하여 각 query가 지정된 역할을 학습하도록 유도합니다. 길이가 맞지 않는 query의 예측은 억제함으로써, 각 query는 특정 길이 범위에 집중하게 되어 모델의 전반적인 성능과 예측 정확도를 향상시킵니다. 논문 제목: Length Matters: Length-Aware Transformer for Temporal Sentence Grounding
논문 요약: Length Matters: Length-Aware Transformer for Temporal Sentence Grounding
- 논문 링크: arXiv:2508.04299
- 저자: Yifan Wang, Ziyi Liu, Xiaolong Sun, Jiawei Wang, Hongmin Liu (University of Science and Technology Beijing, Xi'an Jiaotong University)
- 발표 시기: 2025 (arXiv preprint)
- 주요 키워드: Temporal Sentence Grounding (TSG), Transformer, DETR, 길이 인지, 비디오 이해
1. 연구 배경 및 문제 정의
- 문제 정의:
주어진 자연어 설명에 해당하는 시간적 구간(temporal segment)을 비디오 내에서 찾아내는 Temporal Sentence Grounding (TSG) 태스크는 매우 도전적입니다. 특히, DETR(Detection Transformer) 기반 모델들은 학습 가능한 쿼리(query)를 활용하여 TSG 성능을 크게 향상시켰지만, 쿼리들이 명시적인 지도(supervision) 없이 학습되면서 역할이 중복되어 과도하거나 중복된 예측을 생성하는 문제가 있었습니다. - 기존 접근 방식:
- 초기 방법 (Proposal-based / Proposal-free): 미리 정의된 대량의 제안(proposal) 중에서 선택하거나(proposal-based), 시작 및 끝 경계를 직접 예측하는(proposal-free) 방식이 사용되었으나, 유연성 부족, 중복, 계산 오버헤드, 미성숙한 특징 융합 등의 한계가 있었습니다.
- DETR 기반 방법: Transformer를 TSG에 통합하여 미리 정의된 제안이나 수작업으로 만든 기술의 필요성을 없애는 end-to-end 패러다임을 도입했습니다. 그러나 쿼리들이 명확한 역할 설정에 어려움을 겪어 모호한 전문화, 불안정한 수렴, 성능 저하로 이어졌습니다.
- Anchor 기반 DETR (예: RGTR): 클러스터링을 통해 앵커(anchor)를 도출하고 이를 쿼리에 지침으로 추가하여 최적화를 용이하게 했지만, 쿼리 역할 할당은 여전히 대부분 암묵적이며, 샘플 및 학습 단계에 따라 역할이 달라질 수 있어 일관된 책임 유지가 어려웠습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- Length-Aware Transformer (LATR) 제안: TSG를 위한 간단하면서도 효과적인 LATR을 제안합니다. 이는 추가적인 길이 분류 태스크를 통해 쿼리에 짧은, 중간, 긴 길이 역할을 명시적으로 할당합니다.
- Query-Length Interaction 모듈 제안: 길이 분류 출력을 잔차 억제(residual suppression) 신호로 변환하여, 불일치하는 쿼리의 영향을 효과적으로 줄이는 메커니즘을 제안합니다.
- Low-Quality-Residual Masking 설계: 잘못된 길이 예측을 가진 샘플을 처리하고 모델이 스스로 수정할 수 있도록 돕는 마스킹 기법을 설계합니다.
- SOTA 성능 달성: 제안된 모듈과 전략을 통해 LATR은 특정 길이 역할에 집중하는 쿼리를 학습할 수 있으며, 세 가지 TSG 벤치마크에서 SOTA 성능을 달성합니다.
- 제안 방법:
LATR은 비디오와 자연어 설명으로부터 멀티모달 특징을 추출하고 융합한 후, Query-Length Interaction Module과 Low-Quality-Residual Masking을 통해 최종 모멘트 구간을 예측합니다.- 핵심 아이디어: 비디오-설명 쌍의 "길이 사전 지식(length priors)"을 활용하여 각 쿼리가 특정 시간 길이에 전문화되도록 유도합니다. 모든 쿼리를 짧은, 중간, 긴 길이 세 그룹으로 나눕니다.
- Query-Length Interaction Module:
- Length Perceiver: 융합된 임베딩으로부터 길이 특이성 정보를 Length Token (LT)으로 풀링합니다.
- 길이 예측 (Length Prediction): LT를 세 개의 MLP 분류 헤드에 입력하여 샘플이 긴/중간/짧은 순간을 포함할 확률을 예측합니다.
- 잔차 억제 (Residual Suppression, RS): 길이 예측 결과를 기반으로 RS를 생성합니다. 쿼리의 길이 역할이 예측된 길이 특이성과 일치하지 않을 경우, 해당 쿼리의 콘텐츠 임베딩을 억제하여 불일치하는 쿼리의 간섭을 줄입니다.
- Length Aware Decoder: 기존 디코더 구조를 재검토하여 순간 범위 예측 과정이 길이 특이성 획득을 반영한다고 주장합니다. k-means 클러스터링을 통해 앵커를 생성하고 이를 쿼리의 초기 길이 역할로 부여하며, RS를 동적으로 정제합니다.
- Low-Quality-Residual Masking: 길이 분류가 불확실하거나 잘못될 경우 발생할 수 있는 성능 저하를 방지합니다. Length Token을 MLP 기반의 품질 평가기(MLPQuality)에 입력하여 품질 점수(Qs)를 얻고, 이를 기반으로 잔차 억제를 마스킹하여 복잡하거나 오분류된 샘플에 대한 억제를 비활성화합니다. 또한, 가중 교차 엔트로피 손실을 사용하여 분류 모듈을 학습시키고,
TopK-Save전략을 통해 모델이 스스로 수정할 수 있도록 합니다.
3. 실험 결과
- 데이터셋:
QVHighlights, Charades-STA, TACoS (세 가지 Temporal Sentence Grounding 벤치마크) - 주요 결과:
- State-of-the-Art (SOTA) 성능 달성: QVHighlights, Charades-STA, TACoS 세 가지 데이터셋 모두에서 기존 SOTA 모델들을 능가하는 성능을 달성했습니다. 특히 QVHighlights validation 및 test split에서 거의 모든 지표에서 새로운 SOTA를 기록했습니다.
- 효율성: LATR은 기존 baseline 모델 대비 단 2M개의 파라미터만 추가하고 약 13%의 GFLOPs 증가만을 유발하여, 최소한의 오버헤드로 주목할 만한 성능 향상을 달성했습니다. 이는 제안 방법의 간단하면서도 효과적인 특성을 입증합니다.
- 구성 요소의 기여도 입증: Ablation 연구를 통해 Length Prediction and Residual Suppression (LP&RS), Length Aware Decoder (LAD), Low-Quality Suppression Masking (LQM), TopK-Save (T-S) 등 각 구성 요소가 성능 향상에 기여함을 확인했습니다.
- 길이 정보의 중요성 재확인: LATR에 의해 정확하게 분류된 샘플로 구성된 Length Evaluation Dataset에서 LATR이 RGTR을 크게 능가하는 Oracle 실험을 통해, 길이 정보의 통합이 TSG에서 모델 성능을 향상시킨다는 핵심 주장을 뒷받침했습니다.
- 쿼리 집중도 시각화: LATR에 의해 예측된 모멘트 구간이 특정 길이 범위 내에 더 집중되어 있음을 시각적으로 확인하여, 학습된 쿼리가 실제로 길이 역할을 수행함을 보여주었습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- DETR 기반 모델의 고질적인 문제인 쿼리 역할 중복 및 모호성을 "길이 인지"라는 직관적이고 효과적인 아이디어로 해결했습니다.
- 추가되는 파라미터와 연산량이 매우 적음에도 불구하고 모든 벤치마크에서 SOTA 성능을 달성하여, 실용적인 가치가 매우 높습니다.
- 잘못된 길이 예측에 대한
Low-Quality-Residual Masking과TopK-Save와 같은 견고성 확보 메커니즘을 도입하여 모델의 안정성을 높였습니다. - 길이 분할 방식(2, 3, 4 분할)이 성능에 큰 영향을 미치지 않는다는 점을 보여주어, 특정 임계값 설정에 대한 부담을 줄이고 일반적인 적용 가능성을 높였습니다.
- 단점/한계:
- 길이 분류 기준(예: 0-10초 짧음, 10-30초 중간 등)이 데이터셋마다 경험적으로 설정되어 있어, 새로운 데이터셋에 적용 시 초기 분석 및 설정이 필요할 수 있습니다. 논문에서는 "인간의 직관에 기반하여 세 범주로 나누는 것을 제안"한다고 언급했지만, 여전히 수동적인 개입이 필요합니다.
Low-Quality-Residual Masking이 오분류를 '처리'하는 방식이지, 완벽하게 '해결'하는 것은 아닙니다. 복잡한 샘플에 대한 분류 정확도 자체를 높이는 추가 연구가 필요할 수 있습니다.
- 응용 가능성:
- LATR은 기존 DETR 기반 TSG 모델에 "플러그인" 형태로 쉽게 통합될 수 있어, 다른 연구자들이 자신의 모델에 길이 인지 기능을 추가하는 데 활용될 수 있습니다.
- TSG 외에도 비디오 요약, 액션 인식, 비디오 질의 응답(VideoQA) 등 비디오-언어 상호작용을 다루는 다른 멀티모달 태스크에서 "길이 사전 지식"을 활용하는 아이디어를 확장 적용할 수 있습니다.
- 실제 산업 응용에서는 특정 길이의 이벤트(예: 짧은 스포츠 하이라이트, 긴 강의 구간)를 비디오에서 정확하게 찾아내는 데 활용될 수 있습니다.
Wang, Yifan, et al. "Length Matters: Length-Aware Transformer for Temporal Sentence Grounding." arXiv preprint arXiv:2508.04299 (2025).
Length Matters: Length-Aware Transformer for Temporal Sentence Grounding
Yifan Wang , Ziyi Liu , Xiaolong Sun , Jiawei Wang , Hongmin Liu <br> School of Intelligence Science and Technology, University of Science and Technology Beijing<br> National Key Laboratory of Human-Machine Hybrid Augmented Intelligence, National Engineering Research Center for Visual Information and Applications, and Institute of Artificial Intelligence and Robotics, Xi'an Jiaotong University<br>yifanwanglingf@google.com, liuziyi@ustb.edu.cn, sunxiaolong@stu.xjtu.edu.cn, m202420939@xs.ustb.edu.cn, hmliu_82@163.com
Abstract
**Temporal Sentence Grounding (TSG)**은 주어진 자연어 설명에 해당하는 temporal segment를 untrimmed video 내에서 찾아내는 매우 도전적인 task이다. 학습 가능한 query 설계의 이점을 활용하여, DETR 기반 모델들은 TSG task에서 상당한 발전을 이루었다. 그러나 명시적인 supervision의 부재는 학습된 query들이 역할에서 중복되게 만들고, 이는 과도한(redundant) 예측으로 이어진다.
따라서 우리는 각 query가 지정된 역할을 수행하도록 유도함으로써 TSG 성능을 향상시키고자 한다. 이를 위해 **비디오-설명 쌍의 길이 사전 지식(length priors)**을 활용한다. 본 논문에서는 TSG를 위한 **Length-Aware Transformer (LATR)**를 소개한다. LATR은 다양한 temporal length에 기반하여 예측을 처리하도록 각기 다른 query를 할당한다. 구체적으로, 우리는 모든 query를 세 그룹으로 나누어 각각 짧은(short), 중간(middle), 긴(long) temporal duration을 가진 segment를 담당하게 한다.
학습 과정에서는 추가적인 길이 분류(length classification) task를 도입한다. **길이가 일치하지 않는 query로부터의 예측은 억제(suppress)**되어, 각 query가 지정된 기능에 특화되도록 유도한다. 광범위한 실험을 통해 LATR의 효과를 입증했으며, 세 가지 공개 벤치마크에서 state-of-the-art 성능을 달성하였다. 또한, ablation study는 우리 방법의 각 구성 요소의 기여와 TSG task에 길이 사전 지식을 통합하는 것의 중요성을 검증한다.
1 Introduction
Temporal Sentence Grounding (TSG) task는 주어진 자연어 설명에 해당하는 untrimmed video 내의 temporal segment를 지역화하는 것을 목표로 하는 중요한 연구 분야로 부상했다. 선구적인 연구들은 주로 미리 정의된 dense proposal들 중에서 선택하여 (Gao et al. 2017; Zhang et al. 2020) 목표 temporal segment를 얻는 방식에 의존했다. 최근 detection Transformer (DETR) (Carion et al. 2020)의 등장과 성공은 TSG task를 위한 DETR 기반 접근 방식의 탐구를 이끌었다. 여러 학습 가능한 query의 이점을 활용하여, DETR 기반 접근 방식은 성능과 효율성 면에서 큰 발전을 이루며 새로운 벤치마크를 설정했다 (Moon et al. 2023b; Xiao et al. 2024).
그러나 명시적인 지침의 부재는 학습된 query들이 역할에서 중복되게 하여, 중복된 예측을 초래하는 경우가 많다. 우리는 각 query가 지정된 역할을 수행하도록 하는 것이 이러한 한계를 해결하는 핵심이라고 주장한다. 이를 달성하기 위해, 우리는 학습 가능한 query에 추가적인 supervision을 제공하기 위해 video-description 쌍의 **길이 사전 지식(length priors)**을 활용한다. 직관적으로, segment의 지속 시간은 액션 유형과 같은 내용과 밀접하게 관련되어 있다. 우리는 모델이 짧은/중간/긴 길이에서 해당 query로의 매핑을 학습하도록 간단히 유도하여, 각 query가 특정 역할을 수행하고 중복 예측을 줄이도록 한다. 우리는 길이 사전 지식이 각 query가 지정된 역할을 수행하도록 안내함으로써 TSG task에 유익하다고 가정한다.
Oracle Experiment and Comparison on RGTR
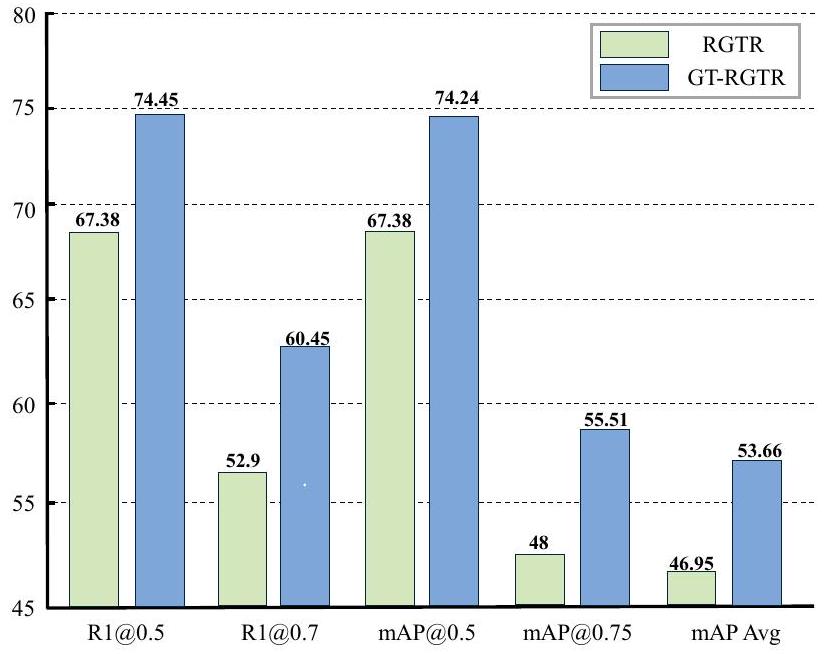
Figure 1: QVHighlights validation split에서 RGTR과 모든 길이 특이성(length specificity)을 적용한 RGTR의 비교. 단순히 길이 특이성을 통합하는 것만으로도 모델 성능이 크게 향상된다. 따라서 길이는 중요하다.
우리의 가정을 증명하기 위해, Fig. 1에 나타난 바와 같이 oracle experiment를 수행했다. 우리는 길이 사전 지식 활용의 이론적 상한을 검증하기 위해 모델에 길이 레이블을 직접 제공했으며, 이는 현재 SOTA 성능을 크게 능가한다. 이에 동기를 받아, 우리는 다양한 temporal length에 기반하여 예측을 처리하도록 다른 query를 할당하는 TSG를 위한 **Length-Aware Transformer (LATR)**를 제안한다. 또한, 이어지는 decoder는 query의 anchor 부분에 대한 초기 길이 역할을 위해 클러스터링 기법을 사용하여 Length Aware Decoder로 accordingly 조정된다. 그러나 이러한 억제(suppression) 전용 파이프라인은 입력 쌍이 잘못 분류되면 잘못된 예측을 할 수 있다. 이를 보완하기 위해, 우리는 이러한 오분류를 처리하기 위해 Low-Quality-Residual Masking을 제안했다. 길이 token은 분류 전에 평가되며, 샘플이 길이 분류에 적합한지 여부를 나타내는 품질 점수가 얻어진다. 저품질 샘플의 잔차(residual)는 필터링되어 억제를 비활성화한다.
 Figure 2: Single Decoder query에 의해 예측된 길이의 집중도. 우리는 Decoder Query를 선택하고 이를 사용하여 무작위로 선택된 50개 샘플에 대한 길이를 예측한다. 그런 다음, 이 예측된 길이의 빈도 분포를 보여주는 히스토그램을 생성한다. x축은 정규화된 moment span 길이를 나타내고, y축은 길이의 빈도를 나타낸다. 비교적으로, RGTR query에 의해 예측된 길이는 상대적으로 분산되어 있는 반면, LATR query에 의해 예측된 길이는 더 집중되어 있다.
Figure 2: Single Decoder query에 의해 예측된 길이의 집중도. 우리는 Decoder Query를 선택하고 이를 사용하여 무작위로 선택된 50개 샘플에 대한 길이를 예측한다. 그런 다음, 이 예측된 길이의 빈도 분포를 보여주는 히스토그램을 생성한다. x축은 정규화된 moment span 길이를 나타내고, y축은 길이의 빈도를 나타낸다. 비교적으로, RGTR query에 의해 예측된 길이는 상대적으로 분산되어 있는 반면, LATR query에 의해 예측된 길이는 더 집중되어 있다.
세 가지 TSG 벤치마크에 대한 광범위한 실험은 LATR 프레임워크의 효과를 입증한다. Fig. 2에 나타난 바와 같이, 이전 연구들과 비교하여 우리 LATR의 학습된 query는 특정 길이 범위에 집중하며, 이는 우리 학습된 query가 실제로 길이 역할을 수행함을 나타낸다. 또한, oracle experiment는 길이 사전 지식이 TSG task에 중요하며, 아직 완전히 탐구되지 않았음을 보여준다. 우리의 기여는 다음과 같이 요약된다: (1) 우리는 TSG를 위한 간단하면서도 효과적인 **Length-Aware Transformer (LATR)**를 제안한다. 여기서 추가적인 길이 분류 task는 query에 짧은, 중간 또는 긴 길이 역할을 할당한다. (2) 우리는 길이 분류 출력을 잔차 억제 신호로 변환하여 불일치하는 query의 영향을 효과적으로 줄이는 Query-Length Interaction 모듈을 제안한다. (3) 우리는 잘못된 길이 예측을 가진 샘플을 처리하기 위해 Low-Quality-Residual Masking을 설계한다. (4) 제안된 모듈과 전략에 의해 촉진되어, 우리 LATR은 특정 길이 역할에 집중하는 query를 학습할 수 있으며, 세 가지 TSG 벤치마크에서 SOTA 성능을 달성한다.
2 Related Work
**Temporal Sentence Grounding (TSG)**는 주어진 자연어 설명에 해당하는 비디오 내의 시간적 구간을 찾아내는 것을 목표로 한다. 이 task는 Gao et al. (Gao et al. 2017)에 의해 처음 제안되었다. VideoQA (Jiang, Liu, and Zheng 2023, 2024; Jiang et al. 2021)나 localization (Liu et al. 2022c; Zhu et al. 2022; Liu and Liu 2025)과 같은 일반적인 비디오 이해 task와 비교할 때, TSG는 거친 의미론적 추론보다는 정밀한 시간적 localization을 요구하므로 본질적으로 더 어렵다.
초기 방법들은 proposal-based 및 proposal-free 접근 방식에 의존했지만, 어느 쪽도 모델 성능을 크게 향상시키지 못했다.
- Proposal-based methods (Liu et al. 2018; Wang et al. 2022b; Zhang et al. 2020; Sun et al. 2022)는 미리 대량의 dense proposal을 생성하고, 이를 설명과의 유사도를 기반으로 순위를 매긴다. 이 접근 방식은 유연성이 부족하고 상당한 중복 및 계산 오버헤드를 초래한다.
- Proposal-free methods (Lu et al. 2019; Chen et al. 2020; Yang and Wu 2022)는 미리 정의된 다수의 proposal에 의존하는 것을 피하기 위해 대상 순간의 시작 및 끝 경계를 직접 예측한다. 그러나 미성숙한 feature fusion 기술과 경계 디코딩 전략으로 인해 성능이 최적화되지 못했다.
Detection Transformer (DETR) (Carion et al. 2020)의 최근 성공은 연구자들이 Transformer를 TSG 프레임워크에 통합하도록 영감을 주었다 (Lei, Berg, and Bansal 2021; Liu, Qu, and Hu 2022; Sun et al. 2025; Lee and Byun 2024). DETR 기반 방법은 미리 정의된 proposal과 수작업으로 만든 기술의 필요성을 없애는 end-to-end 패러다임을 도입한다. 이들은 Transformer encoder를 고품질 멀티모달 feature fusion을 위한 강력한 도구로 활용하고, 학습된 query를 대상 순간 localization을 위한 효율적인 decoder로 사용한다. 이는 proposal-based 및 proposal-free 방법의 한계를 효과적으로 해결하여 모델 성능을 크게 향상시키고, 빠른 반복을 통해 강력한 적응성과 추진력을 보여준다.
Anchor-based DETR
DETR은 강력한 학습 가능한 query 세트를 제공하여 feature로부터 예측된 콘텐츠(예: 공간 범위, 비디오 순간의 시간적 중심 위치, 순간 길이 등)를 디코딩한다. 그러나 명시적인 지침 없이는 이러한 query가 자신의 역할을 명확하게 설정하는 데 어려움을 겪어, 모호한 전문화, 불안정한 수렴, 그리고 성능 저하로 이어진다. 특히 역할 명확성(예: 중심 대 길이)이 중요한 TSG에서는 더욱 그렇다.
이를 해결하기 위해, 일련의 연구들은 query에 사전 지식(prior)과 강력한 inductive bias를 부여하기 위해 DETR에 anchor를 주입하여 역할을 할당하고 학습을 더 효과적으로 안내한다 (Zhu et al. 2020; Shi et al. 2022; Wang et al. 2022a; Liu et al. 2022a; Zhang et al. 2022). 실제로 이러한 anchor는 탐색 공간을 축소하고 초기 디코딩을 안정화하는 참조점 역할을 한다.
TSG에 anchor 기반 설계를 처음 채택한 것은 RGTR (Sun et al. 2024b)로, 이는 클러스터링을 통해 anchor를 도출하고 이를 query에 지침으로 추가한다. 이는 최적화를 용이하게 하지만, 역할 할당은 여전히 대부분 암묵적으로 남아 있다. 그럼에도 불구하고, 우리는 단순히 anchor를 추가하는 것만으로는 약한 supervision만 제공한다는 것을 관찰했다. 즉, query의 역할이 샘플 및 학습 단계에 따라 달라질 수 있어, 실제로 명확한 책임을 일관되게 유지하기 어렵다. 이러한 한계를 극복하기 위해, 우리는 역할 식별을 명시적으로 강제하고 학습 및 추론 전반에 걸쳐 이를 유지하여, query가 전문화되고 안정적으로 유지될 수 있도록 하는 데이터 기반 query 제약을 제안한다.
3 Method
3.1 Overview
주어진 untrimmed video (L개의 프레임)와 자연어 설명 (N개의 단어)에 대해, TSG는 모멘트 구간(moment span) 을 지역화(localize)하는 것을 목표로 한다. 여기서 는 모멘트 구간의 중심 시간(center time)을, 는 모멘트 구간의 지속 시간(duration length)을 나타낸다.
LATR의 전체 아키텍처는 Fig. 3에 나타나 있다. 일반적으로 LATR은 세 가지 부분으로 구성된다:
- Multimodal Feature Extraction and Feature Fusion
- Query-Length Interaction Module
- Low-Quality-Residual Masking
첫째, 비디오와 설명은 Multimodal Feature Extraction and Fusion Module에 의해 처리되어 feature 추출, 정렬(alignment), 그리고 융합(fusion)이 이루어진다. 둘째, 융합된 embedding은 Query-Length Interaction Module로 들어가 query 제약(constraint)을 적용하고 모멘트 구간 및 카테고리를 예측한다. 구체적으로, **Length Token (LT)**은 길이별 정보(length-specific information)를 포착하고 분류를 수행하며, **Residual Suppression (RS)**을 생성한다. 이 RS는 Length Aware Decoder에 의해 query를 안내하고 최종 예측을 수행하는 데 사용된다. 마지막으로, Low-Quality-Residual Masking은 residual suppression의 생성과 그 상호작용을 정제하여 residual의 일부를 선택적으로 억제한다.
3.2 Features Extraction and Fusion
이전 방법들(Moon et al. 2023b; Li et al. 2024)에 따라, 입력 비디오와 설명은 사전학습된 모델에 입력되어 **비디오 feature **와 **텍스트 feature **를 추출한다. 여기서 은 클립의 수, 는 시각 feature의 차원을 나타내며, 은 단어의 수, 는 텍스트 feature의 차원을 나타낸다.
비디오 feature 와 텍스트 feature 는 **다층 퍼셉트론(MLP)**을 사용하여 공통의 멀티모달 공간으로 투영되어 **해당 feature 와 **를 얻는다. 여기서 는 Transformer embedding 차원이다.
이후 이 feature들은 Local&Global Regulator(Li et al. 2021; Sun et al. 2024a)에 입력되어 정렬(align)된다. 비디오와 텍스트 설명 간의 정렬을 용이하게 하기 위해 **추가적인 정렬 손실 **이 사용된다.
이러한 과정을 거친 후, 비디오 feature와 텍스트 feature는 Cross Modal Encoder에 입력되어 feature 융합을 수행하고 최종적으로 **Fusion Embedding **를 얻는다. 이전 방법들과 마찬가지로, Cross Modal Encoder에는 saliency score 제약 (Moon et al. 2023b)이 적용된다.
3.3 Query-Length Interaction Module
데이터 중심 설계는 우리 접근 방식의 핵심이다. 우리는 모델이 각 샘플로부터 **타겟 순간의 길이 특이성(length specificity)**을 적극적으로 학습하고, 이를 활용하여 후속 처리를 안내해야 한다고 주장한다. 이를 달성하기 위해 Length Perceiver는 길이 특이성을 포착하고 길이 예측을 생성하며, 이는 Residual Suppression Generator에 의해 잔여 억제(residual suppression)로 변환된다. 또한, 우리는 decoder 구조를 재검토하고 새로운 관점을 제시한다: 순간 범위 예측(moment span prediction)은 길이 특이성을 학습하는 과정이며, 이는 더욱 명시적인 방식으로 이루어진다. 이 두 유사한 과정은 서로를 보완하고 강화할 수 있다. 이를 위해 우리는 이러한 상호작용을 실현하기 위해 Length Aware Decoder를 도입한다.
길이 예측 (Length Prediction). Length Perceiver와 Residual Suppression Generator의 구조는 Fig. 4에 나타나 있다. Vision Transformer의 class embedding (Dosovitskiy et al. 2020)에서 영감을 받아, 우리는 self-attention을 활용하여 **Fusion Embeddings 로부터 길이 특이성 정보를 length token (LT)으로 풀링(pool)**한다. 이는 다음과 같이 공식화된다:
여기서 length token 는 타겟 순간의 길이 특이성을 학습한다. 그런 다음, LT'에 대해 분류 task가 수행된다. LT'를 세 개의 MLP 분류 head에 입력함으로써, 우리는 길이 특이성을 세 가지 확률 점수(Length Prediction)로 디코딩할 수 있다. 구체적으로, **Length Prediction **는 샘플이 긴/중간/짧은 순간을 포함할 가능성을 반영한다.
잔여 억제 (Residual Suppression). Length Prediction이 얻어지면, 다음 단계는 이를 제약 안내 정보(constraint guidance information)로 변환하여, 샘플의 길이 특이성과 decoder 내 쿼리 간의 일치를 가능하게 하고 길이 특이성을 기반으로 안내를 제공하는 것이다. 따라서 Length Prediction은 Residual Suppression Generator에 입력되어 Residual Suppression (RS)으로 변환되며, 이는 쿼리와 직접 상호작용하여 제약 기반 안내를 부과한다. 구체적으로, RS의 생성 과정은 다음과 같이 공식화된다:
여기서 는 **분류 신뢰도 임계값(classification confidence threshold)**을 나타내는 하이퍼파라미터로, 확률이 이 신뢰도 임계값을 초과하면 샘플이 해당 길이의 타겟 순간을 포함하는 것으로 간주된다. L, M, S는 모두 스칼라 값이다.
잔여 억제(RS)가 생성되면, 이를 쿼리에 적용하여 제약을 부과할 수 있다. 길이 역할이 예측된 길이 특이성과 일치하지 않는 쿼리의 경우, RS는 해당 쿼리의 콘텐츠 임베딩(content embedding)을 억제한다. 반대로, 길이 역할이 일치하는 쿼리의 경우, 억제는 최소화되거나 우회된다. 이러한 선택적 억제 메커니즘은 불일치하는 쿼리로부터의 간섭을 줄임으로써 일치하는 쿼리의 유용성을 간접적으로 향상시킨다.
구체적으로, 인간의 직관에 따라 우리는 쿼리를 Long, Middle, Short 카테고리로 나누고 이 쿼리들의 콘텐츠 임베딩을 추출하며, 이를 로 표기한다. 잔여 억제는 다음과 같은 공식으로 콘텐츠 임베딩에 적용된다:
잔여 억제를 통해 샘플의 길이 특이성과 일치하는 쿼리는 콘텐츠 임베딩을 유지하는 반면, 불일치하는 쿼리는 억제된다.
 Figure 3: LATR의 전체 아키텍처. 이는 세 가지 주요 구성 요소로 이루어져 있다: Feature Extraction and Fusion (Sec 3.2), Query-Length Interaction Module (Sec 3.3), Low-Quality-Residual Masking (Sec 3.4).
Figure 3: LATR의 전체 아키텍처. 이는 세 가지 주요 구성 요소로 이루어져 있다: Feature Extraction and Fusion (Sec 3.2), Query-Length Interaction Module (Sec 3.3), Low-Quality-Residual Masking (Sec 3.4).
 Figure 4: (a) Length Perceiver의 구조. self-attention을 사용하여 샘플로부터 타겟 순간의 길이 특이성을 Length Token으로 풀링한다. (b) Residual Suppression Generator의 구조. 세 개의 MLP를 통해 분류 task를 수행하여 length token에 인코딩된 길이 특이성을 길이 예측으로 디코딩하고, 이를 잔여 억제로 변환한다.
Figure 4: (a) Length Perceiver의 구조. self-attention을 사용하여 샘플로부터 타겟 순간의 길이 특이성을 Length Token으로 풀링한다. (b) Residual Suppression Generator의 구조. 세 개의 MLP를 통해 분류 task를 수행하여 length token에 인코딩된 길이 특이성을 길이 예측으로 디코딩하고, 이를 잔여 억제로 변환한다.
Length Aware Decoder. Fusion Embedding 와 잔여 억제 RS가 준비되면, 이들은 decoder에 입력되어 순간 범위(moment span)를 예측한다. 우리는 decoder 아키텍처와 순간 범위 예측 과정을 길이 특이성이라는 새로운 관점에서 재검토하여, 샘플의 길이 특성이 디코딩에 어떻게 영향을 미치는지를 관찰하고자 한다. 이 분석은 몇 가지 흥미로운 발견을 제시한다.
실제로 TSG task에서 decoder가 예측하는 순간 범위는 길이 특이성을 포함하며, 이는 정확한 수치적 길이를 반영한다. 더욱이, 예측된 길이에 대한 **전경 신뢰도 점수(foreground confidence scores)**는 이전에 논의된 짧은, 중간, 긴 순간에 대한 확률적 출력과 매우 유사하다. 이는 decoder layer가 대안적인 Length Perception 모듈 역할을 할 수 있으며, 잔여 억제의 변형을 생성할 수 있음을 시사한다. 이 변형은 length token (LT)으로부터의 잔여 억제를 동적으로 정제한다.
Length Aware Decoder의 구조는 Fig. 5에 나타나 있다. 이전 방법들(Sun et al. 2024b)을 따라, 우리는 k-means clustering을 사용하여 앵커(anchor)를 생성하고, 이 앵커들은 MLP를 통해 투영되고 위치 인코딩되어 쿼리의 위치 임베딩(positional embeddings)을 형성한다. 본질적으로, 이 초기화는 쿼리에 초기 길이 역할(initial length role)을 부여한다. 쿼리의 콘텐츠 임베딩은 0으로 초기화된다.
3.4 Low-Quality-Residual Masking
Sec 3.3에서 논의했듯이, LATR은 본질적으로 **데이터 기반(data-driven)**이므로, 정확한 길이 분류(length classification)와 residual suppression이 필수적이다. 이 방법은 residual suppression에 의존하기 때문에, 지나치게 공격적이고 취약해진다. 즉, 잘못된 suppression은 성능을 크게 저하시킬 수 있다. 이를 해결하기 위해 우리는 residual suppression을 개선하기보다는 더 잘 활용하는 데 초점을 맞춘 Low-Quality-Residual Masking을 제안한다.
이러한 복잡한 샘플로 인해 발생하는 오분류(misclassification) 및 잘못된 residual suppression을 해결하기 위해, 우리는 length token을 MLP 기반의 quality evaluator인 MLPQuality에 입력하여 품질 점수 를 얻는다. 이 점수는 샘플이 복잡한지 여부를 결정하는 데 사용된다. 그런 다음 를 기반으로 Suppression Maskings 를 생성하여 복잡한 샘플에 의해 생성된 residual suppression을 마스킹함으로써, 이러한 샘플들이 더 이상 residual suppression에 의해 조절되지 않도록 한다. Figure 6은 이 전략의 상세 구조를 보여준다. 제안된 전략은 또한 데이터셋 내의 길이 어노테이션 노이즈를 처리하는 데 효과적임이 입증되었는데,
 Figure 5: (a) Length Aware Decoder의 구조. 우리는 moment span을 예측하는 과정이 본질적으로 타겟 moment의 길이 특이성(length specificity) 획득을 반영한다고 주장한다. (b) RS Allocation의 구조. RS는 해당 query에 할당된다. (c) Top Select의 구조. 업데이트에 사용될 RS가 여기서 생성된다. (d) RS Update의 구조. 새로운 RS는 이전 RS와 업데이트된 RS 사이에서 더 작은 값을 선택하여 생성된다.
Figure 5: (a) Length Aware Decoder의 구조. 우리는 moment span을 예측하는 과정이 본질적으로 타겟 moment의 길이 특이성(length specificity) 획득을 반영한다고 주장한다. (b) RS Allocation의 구조. RS는 해당 query에 할당된다. (c) Top Select의 구조. 업데이트에 사용될 RS가 여기서 생성된다. (d) RS Update의 구조. 새로운 RS는 이전 RS와 업데이트된 RS 사이에서 더 작은 값을 선택하여 생성된다.
여기서 Low-Quality-Suppression Masking은 이상치 샘플(anomalous samples)을 선택적으로 억제하여 학습을 방해하지 않도록 한다.
더 나아가, 오분류된 샘플은 잘못된 residual suppression을 야기할 뿐만 아니라, 분류 손실(classification loss)에도 간섭하여 최적화에 영향을 미친다. 이 문제를 완화하기 위해 우리는 가중 교차 엔트로피 손실(weighted cross-entropy loss) 계산을 채택하며, 여기서 가 가중치 요소로 사용된다.
모델이 trivial solution으로 수렴하는 것을 방지하기 위해 (예: 한 샘플에 매우 높은 를 할당하고 다른 샘플에는 매우 낮은 를 할당하는 경우), 우리는 표준 평균 손실 mean, 가중 손실 weight, 그리고 중앙값 손실 median의 조합을 채택하여 분류 모듈을 학습시킨다.
 Figure 6: Low-Quality-Residual Masking 과정. 고품질 Length Token에 대해서는 Ones Masking이 생성되어 해당 RS가 유지되고 계속 작동한다. 이에 따라 Zero Masking이 생성되어 해당 RS가 마스킹되고 더 이상 작동하지 않는다.
Figure 6: Low-Quality-Residual Masking 과정. 고품질 Length Token에 대해서는 Ones Masking이 생성되어 해당 RS가 유지되고 계속 작동한다. 이에 따라 Zero Masking이 생성되어 해당 RS가 마스킹되고 더 이상 작동하지 않는다.
**중앙값 차이 손실(median-difference loss)**은 의 중앙값과 최솟값 사이의 절대 차이로 정의되며, 이는 trivial prediction 문제의 심각성을 반영한다. 총 분류 손실은 다음과 같이 정의된다:
또한, 우리는 Length Aware Decoder와 상호작용하는 TopK-Save 전략을 제안한다. 이 전략은 억제될 수 있는 소수의 고신뢰도 Decoder Query를 단순히 유지함으로써, 모델이 Length Aware Decoder를 통해 자체 수정(self-correction)을 수행할 수 있도록 한다.
3.5 Training Objectives
LATR은 네 가지 목적 함수(objective loss)로 구성된다: moment loss , saliency loss , alignment loss , 그리고 추가적인 **length classification loss **이다. 전체 목적 함수는 다음과 같이 정의된다:
여기서 는 균형(balancing) 파라미터이다. 과 의 값은 TSG 커뮤니티의 광범위한 실험을 통해 최적의 값으로 결정되었으므로, 추가적인 논의가 필요 없다는 점을 강조한다. 또한, 우리는 Sec 4.4의 ablation study를 통해 의 다양한 값이 모델 성능에 미치는 영향을 조사한다.
4 Experiment
4.1 Datasets and Metrics
데이터셋 (Datasets)
우리는 QVHighlights (Lei, Berg, and Bansal 2021), Charades-STA (Gao et al. 2017), TACoS (Regneri et al. 2013)를 포함한 세 가지 temporal sentence grounding 벤치마크에서 LATR을 평가한다.
- QVHighlights는 다양한 주제를 다루며, 일반적으로 단일 비디오-설명 쿼리 쌍 내에 길이가 다양한 여러 개의 target moment가 존재한다.
- Charades-STA는 복잡한 일상 인간 활동으로 구성되어 있으며,
- TACoS는 주로 요리 활동에 초점을 맞춘 긴 형식의 비디오를 보여준다.
이 두 데이터셋(Charades-STA, TACoS)의 경우, 각 비디오-쿼리 쌍 내에 단 하나의 target moment만 존재한다.
평가 지표 (Metrics)
우리는 IoU 임계값 0.3, 0.5, 0.7에서 **Recall@1 (R1)**을 채택한다. QVHighlights는 문장당 여러 개의 ground-truth moment를 포함하므로, IoU 임계값 0.5, 0.75에서의 mAP와 IoU 임계값 [0.5: 0.05: 0.95] 세트에 대한 평균 mAP도 보고한다. Charades-STA 및 TACoS의 경우, top-1 예측의 평균 IoU를 계산한다.
Table 1: QVHighlights val 및 test split에서의 성능 비교
| Method | val | test | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| R1 | mAP | R1 | mAP | |||||||
| @0.5 | @0.7 | @0.5 | @0.75 | Avg. | @0.5 | @0.7 | @0.5 | @0.75 | Avg. | |
| M-DETR (Lei, Berg, and Bansal 2021) | 53.94 | 34.84 | - | - | 32.20 | 52.89 | 33.02 | 54.82 | 29.40 | 30.73 |
| UMT (Liu et al. 2022b) | 60.26 | 44.26 | - | - | 38.59 | 56.23 | 41.18 | 53.83 | 37.01 | 36.12 |
| QD-DETR (Moon et al. 2023b) | 62.68 | 46.66 | 62.23 | 41.82 | 41.22 | 62.40 | 44.98 | 62.52 | 39.88 | 39.86 |
| UniVTG (Lin et al. 2023) | 59.74 | - | - | - | 36.13 | 58.86 | 40.86 | 57.60 | 35.59 | 35.47 |
| TR-DETR (Sun et al. 2024a) | 67.10 | 51.48 | 66.27 | 46.42 | 45.09 | 64.66 | 48.96 | 63.98 | 43.73 | 42.62 |
| TaskWeave (Yang et al. 2024) | 64.26 | 50.06 | 65.39 | 46.47 | 45.38 | - | - | - | - | - |
| UVCOM (Xiao et al. 2024) | 65.10 | 51.81 | - | - | 45.79 | 63.55 | 47.47 | 63.37 | 42.67 | 43.18 |
| CG-DETR (Moon et al. 2023a) | 67.35 | 52.06 | 65.57 | 45.73 | 44.93 | 48.38 | 64.51 | 42.77 | 42.86 | |
| RGTR (Sun et al. 2024b) | 65.50 | |||||||||
| LATR (Ours) | 67.74 | 53.16 | 68.03 | 49.10 | 48.16 | 65.30 | 49.35 | 67.33 | 46.12 | 46.07 |
Table 2: TACoS 및 Charades-STA에서의 성능 비교
| Method | Charades-STA | TACoS | ||||
|---|---|---|---|---|---|---|
| R1@0.5 | R1@0.7 | mIoU | R1@0.5 | R1@0.7 | mIoU | |
| M-DETR (Lei, Berg, and Bansal 2021) | 52.07 | 30.59 | 45.54 | 24.67 | 11.97 | 25.49 |
| UMT (Liu et al. 2022) | 48.31 | 29.25 | - | - | - | - |
| QD-DETR (Moon et al. 2023b) | 57.31 | 32.55 | - | - | - | - |
| UniVTG (Lin et al. 2023) | 58.01 | 35.65 | 50.10 | 34.97 | 17.35 | 33.60 |
| TR-DETR (Sun et al. 2024a) | 57.61 | 33.52 | - | - | - | - |
| CG-DETR (Moon et al. 2023a) | 58.44 | 50.13 | 39.61 | 22.23 | 70.43 | |
| RGTR (Sun et al. 2024b) | 57.93 | 35.16 | ||||
| LATR (Ours) | 59.54 | 37.33 | 50.88 | 40.62 | 25.37 | 37.68 |
4.2 Implementation Details
타겟 모멘트 길이의 분류를 위해, QVHighlights에서는 이전 연구(Diwan, Peng, and Mooney 2023)에서 제공된 경험적 통찰을 따라 모멘트의 절대 길이를 분류 기준으로 사용한다:
- 0-10초 지속되는 모멘트는 **짧은 모멘트(short moments)**로,
- 10-30초는 **중간 모멘트(middle moments)**로,
- 30-150초는 **긴 모멘트(long moments)**로 분류된다.
Charades-STA의 경우, 모멘트의 정규화된 길이를 분류 기준으로 사용한다:
- 0-0.2는 짧은 모멘트,
- 0.2-0.302는 중간 모멘트,
- 0.302-1은 긴 모멘트로 분류된다.
동일한 분류 규칙이 TACoS에도 적용되며, 여기서는:
- 0-0.045가 짧은 모멘트,
- 0.045-0.1이 중간 모멘트,
- 0.1-1이 긴 모멘트에 해당한다.
Tab. 8에 나타난 바와 같이, 우리의 ablation study는 균등 분할 원칙 하에서 길이 분할의 특정 방식이 모델 성능에 크게 영향을 미치지 않음을 보여준다. 따라서 중요한 것은 정확한 분할 방법보다는 길이 분할 자체를 수행하는 것이다. 이러한 관찰을 바탕으로, 우리는 새로운 데이터셋에 대한 길이 분할의 일반적인 가이드라인을 제안한다: 인간의 직관에 기반하여 모멘트 길이를 짧음, 중간, 김의 세 가지 범주로 나누는 것을 제안한다. 다양한 비디오 길이를 고려하기 위해 정규화된 길이를 사용하는 것을 권장한다. 분할은 학습 샘플을 균형 잡힌 수량으로 세 그룹으로 대략적으로 나누는 방식으로 달성할 수 있다.
이전 방법들(Moon et al. 2023b)을 따라, 우리는 SlowFast (Feichtenhofer et al. 2019)와 CLIP (Radford et al. 2021)을 사용하여 시각적 feature를 추출하고, CLIP을 사용하여 텍스트 feature를 추출한다. 임베딩 차원 D는 256으로 설정한다. 쿼리 및 앵커 쌍의 수는 QVHighlights의 경우 20개, Charades-STA 및 TACoS의 경우 10개로 설정한다. 균형 매개변수는 다음과 같이 설정한다: , 은 QVHighlights의 경우 1, Charades-STA 및 TACoS의 경우 4로 설정하며, 는 QVHighlights의 경우 1, Charades-STA 및 TACoS의 경우 3으로 설정한다. Top-Select는 QVHighlights 및 Charades-STA의 경우 4, TACoS의 경우 3으로 설정한다. TopK-Save는 QVHighlights의 경우 3, Charades-STA 및 TACoS의 경우 1로 설정한다. 는 0.5로 설정한다. 모든 모델은 배치 크기 32로 학습하며, weight decay 를 사용하는 AdamW optimizer를 사용한다. 학습률은 로 설정한다.
4.3 Performance Comparison
Tab. 1에서 보여주듯이, 우리는 QVHighlights validation 및 test split에서 LATR을 이전 방법들과 비교하였다. 우리 방법은 validation split과 test split의 거의 모든 metric에서 새로운 state-of-the-art 성능을 달성하였다. 이러한 우수한 성능은 명확하고 일관된 길이 역할(length roles)을 가진 query의 효과를 입증한다. Tab. 2는 TACoS 및 Charades-STA test split에서의 비교 결과를 보여준다. 우리 방법은 TACoS와 Charades-STA에서 최고의 성능을 달성하였다.
Table 3: RGTR과 LATR의 GFLOPs, Parameters, 비교.
| Method | GFLOPs | Parameters | |
|---|---|---|---|
| RGTR | 153.07 | 9.22 M | 36.95 |
| LATR | 174.47 | 11.65 M | 38.16 |
Table 4: 다양한 Length Token (LT) Initialization Strategies, Classification Strategies, 및 Suppression Strategies의 영향에 대한 Ablation study.
| Method | Changes | R1@ 0.5 | . | |
|---|---|---|---|---|
| LT Initialization | random | 67.10 | 67.32 | 47.43 |
| zero | ||||
| Classification | -way | 67.68 | 67.43 | 47.31 |
| 3 binary | ||||
| Suppression | fixed factor | 67.48 | 67.54 | 47.49 |
| residual |
Table 5: LATR에 의해 정확하고 완벽하게 분류된 QVHighlights validation 샘플로 구성된 Length Evaluation Dataset에서의 RGTR과 LATR 비교.
| Method | R1 | mAP | ||||
|---|---|---|---|---|---|---|
| Avg. | ||||||
| RGTR | 70.33 | 54.07 | 55.84 | 33.67 | 33.54 | |
| LATR | 74.64 | 55.98 | 60.64 | 33.89 | 35.89 |
Tab. 3은 LATR이 baseline에 비해 추가적으로 도입하는 파라미터 수와 연산 오버헤드를 보여준다. LATR은 단 2M개의 파라미터만 추가하고 약 13%의 GFLOPs 증가만을 유발하여, 최소한의 파라미터 및 연산 오버헤드로 주목할 만한 성능 향상을 달성한다. 이는 우리가 제안하는 방법이 간단하면서도 효과적임을 입증한다.
4.4 Ablation Study
주요 Ablation 연구. 우리는 LATR의 각 구성 요소의 효과를 조사한다. Tab. 6에서 Length Prediction and Residual Suppression (LP&RS), Length Aware Decoder (LAD), Low-Quality Suppression Masking (LQM), 그리고 **TopK-Save (T-S)**에 따른 영향을 보고한다. 결과는 각 구성 요소가 성능 향상에 기여하며, 설정 (f)의 전체 모델이 mAPavg를 1.21 향상시켜 최고의 성능을 달성함을 보여준다.
핵심 구성 요소의 구현 변형. 우리는 세 가지 핵심 구성 요소인 LT Initialization Strategy, Classification Strategy, 그리고 Suppression Strategy의 다양한 구현 변형을 평가한다. 구체적으로, Length Token을 zero initialization 대신 random initialization으로 초기화하는 실험을 수행했다. 또한, 세 개의 이진 분류 MLP를 단일 3-way 분류 MLP로 대체하는 실험, 그리고 residual suppression 대신 고정된 스케일링 팩터 쌍을 사용하는 실험을 진행했다. 여기서 는 prominence를 강화하고 는 suppression을 위해 설계되었다. Tab. 4에서 보듯이, 이러한 모든 대안 설계는 성능 저하를 초래하며, 이는 우리가 선택한 구현이 가장 효과적임을 입증한다. 더 중요한 것은, 고정된 스케일링 팩터를 사용하는 것이 현저한 성능 저하를 가져온다는 점인데, 이는 쿼리의 prominence를 향상시키는 것이 본질적으로 어렵고 효과적인 직접적인 해결책이 없음을 추가적으로 시사한다.
Table 6: LATR의 구성 요소에 대한 Ablation study. 여기에는 Length Prediction and Residual Suppression (LP&RS), Length Aware Decoder (LAD), Low-Quality Residual Masking (LQM), 그리고 **TopK-Save (T-S)**가 포함된다.
| Setting LP&RS LAD LQM T-S R1 @ 0.5 mAP@ 0.5 mAP | ||||||
|---|---|---|---|---|---|---|
| (a) | 67.68 | 67.38 | ||||
| (b) | 67.29 | 67.41 | ||||
| (c) | 67.26 | 67.51 | ||||
| (d) | 67.35 | 67.79 | ||||
| (e) | 67.61 | 47.72 | ||||
| (f) |
Table 7: Length classification loss의 구성 요소에 대한 Ablation study.
| Setting | mean | weight | median | R1@ 0.5 | mAP@ 0.5 | mAP |
|---|---|---|---|---|---|---|
| (a) | 67.23 | 67.41 | 47.48 | |||
| (b) | 67.35 | 67.58 | 47.56 | |||
| (c) | 67.64 | 67.76 | 47.66 | |||
| (d) | 67.29 | 67.56 | 47.44 | |||
| (e) |
Table 8: Length split method에 대한 Ablation study.
| Method | R1 | mAP | ||||
|---|---|---|---|---|---|---|
| Avg. | ||||||
| 2 Split | 67.42 | 52.78 | 68.00 | 48.73 | 47.98 | |
| 3 Split | 67.74 | 53.16 | 68.03 | 49.10 | 48.16 | |
| 4 Split | 67.08 | 52.32 | 68.01 | 48.47 | 47.93 |
Length Classification Loss Function. 우리는 length classification loss function (Eq. 4)에서 각 loss 구성 요소의 기여도를 평가한다. Tab. 7에서 보듯이, 기본 mean cross-entropy loss만 사용하는 것은 모델 성능 저하로 이어지지만, Length Token의 quality score를 기반으로 추가 loss term을 통합하면 결과가 향상되며, 이는 각 구성 요소가 전체 최적화에 효과적으로 기여함을 보여준다.
Length 중요성에 대한 추가 Oracle 실험. Temporal Sentence Grounding에서 length 정보의 효과를 추가적으로 조사하기 위해, 우리는 LATR에 의해 정확하고 완벽하게 분류된 QVHighlights validation split의 모든 샘플을 추출하여 추가적인 Length Evaluation Dataset을 구성했다. Tab. 5에서 보듯이, LATR은 이 큐레이션된 데이터셋에서 RGTR을 크게 능가하며, 이는 length 정보의 통합이 TSG에서 모델 성능을 향상시킨다는 것을 명확하게 나타낸다. 이는 우리의 핵심 주장인 **"length matters"**를 더욱 뒷받침한다.
 Figure 7: RGTR과 LATR(본 연구)에서 50개의 무작위로 선택된 샘플에 대한 단일 Decoder 쿼리의 moment span 예측 시각화 비교 두 그룹 (Fig. 2에 언급된 방법을 따름). x축은 샘플 인덱스를 나타내고, y축은 정규화된 moment span 길이를 나타낸다.
Figure 7: RGTR과 LATR(본 연구)에서 50개의 무작위로 선택된 샘플에 대한 단일 Decoder 쿼리의 moment span 예측 시각화 비교 두 그룹 (Fig. 2에 언급된 방법을 따름). x축은 샘플 인덱스를 나타내고, y축은 정규화된 moment span 길이를 나타낸다.
 Figure 8: 하이퍼파라미터에 대한 Ablation study
Figure 8: 하이퍼파라미터에 대한 Ablation study
Length Split Method 및 Length Split Thresholds. 동일 비율 분할 원칙에 따라, 우리는 2, 3, 4개의 length split이 모델 성능에 미치는 영향을 비교한다. Tab. 8에서 보듯이, 이러한 분할 방법들 간의 성능 차이는 상대적으로 작다. 이는 length splitting이 중요하지만, 특정 분할 방식이 특별히 중요하지는 않음을 나타낸다. 우리는 또한 다른 length division threshold가 모델 성능에 거의 영향을 미치지 않는다는 ablation study를 수행한다.
하이퍼파라미터 분석. 우리는 하이퍼파라미터의 다른 값들이 미치는 영향을 평가한다. Fig. 8에서 보듯이, 모델 성능은 하이퍼파라미터의 다른 값들 간에 최소한의 변화를 보이며, 이는 우리가 제안한 방법의 효과가 특정 하이퍼파라미터 선택에 크게 의존하지 않음을 보여준다.
4.5 Visualization Result
Fig. 7은 Fig. 2에서 언급된 방법을 따라, RGTR과 LATR 두 가지 설정에서 두 쿼리에 대한 예측된 moment span을 시각화한다. LATR에 의해 예측된 moment span은 특정 길이 범위 내에 더 집중되어 있는 반면, RGTR에 의해 예측된 span은 더 넓게 분포되어 있어 집중도가 떨어짐이 명확하게 관찰된다.
Fig. 9에서는 QVHighlights validation split에 대한 예시를 제시한다. 타겟 moment가 짧을 때, baseline인 RGTR은 이를 길게 예측하는 반면, LATR은 짧게 식별하고 예측한다. 이는 LATR이 타겟 moment의 길이를 추정하는 데 있어 강력한 length-awareness를 가지고 있음을 보여준다.
 Figure 9: 정성적 예시 (qualitative example) 시각화
Figure 9: 정성적 예시 (qualitative example) 시각화
5 Conclusion
본 논문에서 우리는 DETR-style 모델의 핵심 약점인 "쿼리가 길이 역할(length roles)을 인식하지 못하거나 일관되게 유지하지 못하는 문제"를 해결하는 TSG(Temporal Sentence Grounding)를 위한 Length-Aware Transformer인 LATR을 제안한다. LATR은 **샘플별 길이 특이성(per-sample length specificity)을 포착하여 이를 잔차 억제(residual suppression)로 변환함으로써 디코딩 전반에 걸쳐 쿼리를 안내하는 데이터 기반 쿼리 제약(data-driven query constraint)**을 도입한다. 길이 예측이 불확실할 때 신뢰성을 향상시키기 위해, 우리는 Low-Quality-Residual Masking과 TopK-Save를 설계하여 모델이 과도하게 억제하기보다는 스스로 수정할 수 있도록 했다. 세 가지 공개 벤치마크에서 LATR은 **최소한의 오버헤드(적은 파라미터 및 GFLOP 증가)**로 state-of-the-art 결과를 달성했으며, ablation 연구를 통해 각 구성 요소의 기여와 TSG에 길이 사전 지식(length priors)을 주입하는 것의 중요성을 검증했다. 정성적 분석 결과, LATR 하의 쿼리들은 전문화되고 안정적으로 유지되어 집중된 길이 예측을 생성함을 보여준다.
앞으로 LATR은 다른 DETR 기반 TSG 모델 및 관련 비디오-언어 task에 통합될 수 있는 일반적인 플러그인이다. 우리의 oracle 실험은 길이 사전 지식을 명시적으로 만드는 것이 높은 활용도를 가진 방향임을 강조하며, 이 연구의 가치와 잠재력을 모두 보여준다. 우리가 아는 한, LATR은 TSG를 위해 길이 사전 지식을 구조적으로 인코딩하고 작동화한 최초의 모델이다. 이 접근 방식은 단 2M개의 파라미터와 약 13%의 GFLOPs만을 추가하면서도 일관된 SOTA 성능 향상을 제공하여, temporal sentence grounding의 추가 발전을 위한 실용적인 경로를 제시한다. 실제로 동일한 residual-suppression 메커니즘은 최소한의 변경으로 기존 decoder에 적용될 수 있다.