Pixel-BERT: Deep Multi-Modal Transformer를 이용한 이미지 픽셀과 텍스트 정렬
Pixel-BERT는 기존의 객체 탐지 기반의 region-based visual feature의 한계를 극복하기 위해, 이미지 픽셀과 텍스트를 직접적으로 정렬하는 end-to-end multi-modal Transformer 모델입니다. 이 모델은 CNN 기반 visual encoder를 사용하여 이미지 픽셀에서 직접 시각적 임베딩을 학습하고, 이를 텍스트 임베딩과 결합하여 심층적인 상호작용을 학습합니다. Pre-training 단계에서는 Masked Language Model (MLM)과 Image-Text Matching (ITM) task를 사용하며, 시각적 표현의 강인함을 높이기 위해 random pixel sampling 메커니즘을 제안합니다. 이를 통해 VQA, image-text retrieval 등 다양한 downstream task에서 뛰어난 성능을 보여줍니다. 논문 제목: Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers
논문 요약: Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers
- 논문 링크: https://arxiv.org/abs/2004.00849
- 저자: Zhicheng Huang (University of Science and Technology Beijing), Zhaoyang Zeng (Sun Yat-sen University), Bei Liu (Microsoft Research), Dongmei Fu (University of Science and Technology Beijing), Jianlong Fu (Microsoft Research)
- 발표 시기: 2020년 (arXiv 프리프린트)
- 주요 키워드: Vision and Language, Multi-modal, Transformer, Representation Learning, Self-supervised Learning
1. 연구 배경 및 문제 정의
- 문제 정의:
기존의 대부분의 Vision-Language (V+L) 연구들은 객체 탐지 모델(예: Faster R-CNN)에서 추출된 '영역 기반(region-based) 시각 특징'을 활용한다. 그러나 이러한 방식은 다음과 같은 한계를 가진다:- 정보 간극: 특정 시각 태스크(객체 탐지)에 맞춰 설계되어 언어 이해와의 정보 간극이 발생한다.
- 정보 손실: 객체의 모양, 겹치는 객체 간의 공간 관계, 장면, 감정 등 중요한 시각 정보가 손실될 수 있다.
- 제한된 표현 능력: 특징 표현 능력이 탐지 모델의 미리 정의된 카테고리에 의해 제한된다.
- 높은 비용: 바운딩 박스(bounding box) 어노테이션에 높은 비용이 발생한다. 이 논문은 이러한 한계를 극복하고 이미지 픽셀과 언어 의미론 간의 보다 정확하고 철저한 연결을 직접 구축하고자 한다.
- 기존 접근 방식:
기존 V+L 모델들은 BERT 기반의 언어 특징과 객체 탐지 모델에서 추출된 영역 기반 시각 특징을 입력으로 받아 공동 임베딩 학습을 수행했다. 이는 시각 특징이 표현하는 시각적 의미에 제한을 받았다.
2. 주요 기여 및 제안 방법
-
논문의 주요 기여:
- 픽셀-텍스트 직접 정렬: CNN 기반 Visual Encoder와 Deep Multi-Modal Transformer로 구성된 Pixel-BERT를 제안하여, 이미지 픽셀과 텍스트를 직접 정렬하고 시각 및 언어 임베딩을 공동으로 학습하는 end-to-end 프레임워크를 구축했다. 픽셀 및 텍스트 수준에서 Vision과 Language 의미를 정렬하는 self-supervised learning을 처음으로 고려했다.
- 견고한 시각 표현 학습: 시각 표현 학습의 견고성(robustness)을 향상시키기 위해 '무작위 픽셀 샘플링(random pixel sampling)' 메커니즘을 제안했다.
- SOTA 성능 달성: VQA, Image-Text Retrieval, NLVR를 포함한 다양한 다운스트림 태스크에서 State-of-the-Art (SOTA) 성능을 달성했다. 특히 VQA 태스크에서 단일 모델 성능을 기존 SOTA 대비 2.17점 향상시켰다.
-
제안 방법:
Pixel-BERT는 세 가지 주요 부분으로 구성된다:- Image Feature Embedding: 기존의 영역 기반 특징 추출 대신, ResNet 또는 ResNeXt와 같은 CNN 기반 Visual Backbone을 사용하여 이미지 픽셀에서 직접 시각적 임베딩을 학습한다. 이를 통해 원본 이미지의 시각 정보를 완전히 활용한다.
- Sentence Feature Embedding: BERT를 따라 WordPiece 토크나이저를 사용하여 문장을 토큰화하고, 각 토큰을 벡터로 임베딩한다. 위치 임베딩을 추가하여 언어 정보를 인코딩한다.
- Cross-Modality Module: 학습된 시각 임베딩과 언어 임베딩을 결합하여 단일 시퀀스로 구성한 후, BERT 기반의 Multi-Modal Transformer에 입력한다. 이 Transformer는 이미지-이미지, 문장-문장 간의 '도메인 내(intra-domain)' 연결과 이미지-문장 간의 '도메인 간(inter-domain)' 연결을 모두 학습한다. 이 전체 네트워크는 end-to-end 학습이 가능하다.
사전학습(Pre-training) 절차: Pixel-BERT는 대규모 이미지-문장 쌍 데이터셋(MS-COCO, Visual Genome)으로 사전학습된다.
- Masked Language Modeling (MLM): 언어 토큰의 15%를 무작위로 마스킹하고, 모델이 다른 마스킹되지 않은 토큰과 이미지 픽셀을 기반으로 마스킹된 토큰을 예측하도록 학습한다. 이는 언어와 시각 모달리티 간의 매핑을 구축하는 데 도움을 준다.
- Image-Text Matching (ITM): 이미지와 문장 쌍이 서로 일치하는지 여부를 분류하도록 학습한다. 긍정 샘플(일치하는 쌍)과 부정 샘플(일치하지 않는 쌍)을 동일하게 사용하여 학습 편향을 방지한다.
- Pixel Random Sampling: 사전학습 단계에서만 적용되는 메커니즘으로, 각 이미지의 특징 맵에서 고정된 수(예: 100개)의 픽셀을 무작위로 샘플링하여 Transformer에 입력한다. 이는 불완전한 시각 입력으로부터 의미론적 지식을 학습하게 하여 모델의 견고성을 향상시키고 과적합을 방지하며, 계산 비용을 절감한다.
3. 실험 결과
- 데이터셋:
- 사전학습: MS-COCO 2014, Visual Genome (VG)
- 다운스트림 태스크:
- Visual Question Answering (VQA): VQA 2.0
- Natural Language for Visual Reasoning for Real (NLVR): NLVR
- Image-Text Retrieval: Flickr30K, MS-COCO
- Visual Backbone: ResNet-50 (r50) 및 ResNeXt-152 (x152) 사용.
- 주요 결과:
- VQA: ResNeXt-152 백본 사용 시 VQA test-dev에서 74.45점, test-std에서 74.55점을 달성하여 기존 모든 연구들을 크게 능가했다. 특히 24-Layer Transformer를 사용한 UNITER (Large)보다도 높은 성능을 보였다.
- NLVR: ResNeXt-152 백본 사용 시 dev 76.5%, test-P 77.2%의 정확도를 달성하여 LXMERT 및 UNITER의 "Pair" 설정을 능가했다.
- Image-Text Retrieval: Flickr30K 및 MS-COCO 데이터셋에서 image-to-text retrieval (TR) 및 text-to-image retrieval (IR) 모두에서 SOTA 성능을 달성했다. 특히 text-to-image retrieval에서 기존 모델 대비 큰 폭의 성능 향상을 보였다.
- Ablation Study: MLM, ITM 사전학습 태스크가 모두 다운스트림 태스크 성능을 크게 향상시켰음을 입증했다. 제안된 '무작위 픽셀 샘플링' 방법 또한 VQA, Retrieval, NLVR에서 성능 향상에 기여함을 확인했다. 강력한 Visual Backbone (ResNeXt-152) 사용 시 성능이 크게 가속화되었다.
- Attention Map 시각화: Bounding box 어노테이션 없이도, Pixel-BERT가 특정 토큰(예: "dog", "cutting", "room")에 대해 이미지 내의 정확한 시각적 영역에 어텐션이 집중됨을 시각화로 보여주며, 픽셀 수준에서 의미 있는 시각적 표현을 학습함을 입증했다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 기존의 객체 탐지 기반 시각 특징의 한계를 극복하고, 이미지 픽셀과 텍스트를 직접 정렬함으로써 더 풍부하고 정확한 시각-언어 의미론적 연결을 학습할 수 있다는 점이 가장 인상 깊다. 이는 바운딩 박스 어노테이션의 높은 비용과 정보 손실 문제를 해결하는 중요한 진전이다.
- '무작위 픽셀 샘플링' 메커니즘을 통해 시각 표현 학습의 견고성을 높이고 과적합을 방지하며, 계산 효율성까지 고려했다는 점이 뛰어나다.
- VQA, 이미지-텍스트 검색 등 다양한 멀티모달 태스크에서 SOTA 성능을 달성하며 모델의 범용성과 강력함을 입증했다. 특히 VQA에서 큰 폭의 성능 개선은 실제 응용 가능성을 높인다.
- 어텐션 맵 시각화를 통해 모델이 명시적인 공간적 감독 없이도 픽셀 수준에서 의미 있는 시각적 영역에 집중함을 보여준 것은 모델의 해석 가능성 측면에서도 큰 장점이다.
- 단점/한계:
- 픽셀 재구성의 어려움 때문에 'Masked Visual Prediction' 대신 '무작위 픽셀 샘플링'을 사용했다는 점은 시각 콘텐츠를 위한 더 진보된 self-supervised 태스크 설계에 대한 추가 연구가 필요함을 시사한다.
- ResNeXt-152와 같은 강력한 백본 사용 시 GPU 메모리 사용량 때문에 입력 이미지 크기(짧은 변 600, 긴 변 1000 미만)에 제약이 있었다. 이는 매우 고해상도 이미지 처리 시 한계가 될 수 있다.
- CNN Visual Backbone과 Transformer에 서로 다른 종류의 옵티마이저 설정을 사용해야 하는 점은 구현의 복잡성을 증가시킬 수 있다.
- 응용 가능성:
- 멀티모달 AI 시스템: VQA, 이미지 캡셔닝, 시각적 추론 등 이미지와 텍스트를 동시에 이해하고 상호작용해야 하는 다양한 멀티모달 AI 시스템의 핵심 구성 요소로 활용될 수 있다.
- 콘텐츠 기반 검색: 이미지-텍스트 검색 성능 향상을 통해 대규모 이미지/비디오 데이터베이스에서 자연어 쿼리를 이용한 효율적인 콘텐츠 검색 시스템 구축에 기여할 수 있다.
- 자율주행 및 로봇 공학: 시각 정보와 언어 명령을 동시에 이해하고 처리해야 하는 자율주행 차량이나 로봇 시스템에서 환경 이해 및 명령 수행 능력을 향상시킬 수 있다.
- 접근성 기술: 시각 장애인을 위한 이미지 설명 생성, 복잡한 시각 정보를 언어로 변환하는 등 접근성 향상 기술에 적용될 잠재력이 크다.
Huang, Zhicheng, et al. "Pixel-bert: Aligning image pixels with text by deep multi-modal transformers." arXiv preprint arXiv:2004.00849 (2020).
Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers
Zhicheng Huang , Zhaoyang Zeng , Bei Liu , Dongmei Fu , and Jianlong <br> University of Science and Technology Beijing<br>zhicheng.huang@xs.ustb.edu.cn, fdm_ustb@ustb.edu.cn<br> Sun Yat-sen University<br>zengzhy5@mail2.sysu.edu.cn<br> Microsoft Research<br>{bei.liu, jianf}@microsoft.com
Abstract
우리는 Pixel-BERT를 제안한다. 이는 통합된 end-to-end 프레임워크 내에서 시각 및 언어 임베딩을 공동으로 학습하는 딥 멀티모달 Transformer를 통해 **이미지 픽셀과 텍스트를 정렬(align)**한다. 우리의 목표는 최근의 대부분의 vision-language task에서 사용되는 영역 기반(region-based) 이미지 feature 대신, 이미지 픽셀과 언어 의미론 간의 보다 정확하고 철저한 연결을 이미지-문장 쌍으로부터 직접 구축하는 것이다. 픽셀 및 텍스트 수준에서 의미론적 연결을 정렬하는 우리의 Pixel-BERT는 vision-language task를 위한 task-specific 시각 표현의 한계를 해결한다. 또한 bounding box 어노테이션 비용을 절감하고, 시각 task의 의미론적 레이블과 언어 의미론 간의 불균형을 극복한다. 다운스트림 task를 위한 더 나은 표현을 제공하기 위해, 우리는 Visual Genome 데이터셋과 MS-COCO 데이터셋의 이미지-문장 쌍을 사용하여 범용적인 end-to-end 모델을 사전학습한다. 우리는 시각 표현의 견고성을 향상시키기 위해 무작위 픽셀 샘플링 메커니즘을 사용하고, 사전학습 task로 Masked Language Model과 Image-Text Matching을 적용할 것을 제안한다. 사전학습된 모델을 사용한 다운스트림 task에 대한 광범위한 실험 결과, 우리의 접근 방식은 **Visual Question Answering (VQA), image-text retrieval, Natural Language for Visual Reasoning for Real (NLVR)**을 포함한 다운스트림 task에서 state-of-the-art 결과를 달성한다. 특히, VQA task에서 단일 모델의 성능을 공정한 비교 하에 SOTA 대비 2.17점 향상시켰다.
키워드: Vision and Language, Representation Learning
1 Introduction
자연어 처리 분야에서 **표현 학습(representation learning)**에 적용된 self-supervised learning의 성공에 힘입어 [349], 최근 연구들은 유사한 self-supervised learning 방식으로 cross-modality learning, 특히 vision과 language 분야 [6, 18, 19, 21, 22, 29, 33, 41]의 task를 다루고 있다. 이러한 연구들에서는 pre-training이 cross-modality 도메인에서 vision과 language 모두에 강력한 표현을 제공하기 위해 널리 사용된다. 대부분의 모델은 BERT 기반의 language feature와 region-based visual feature를 pre-trained 모델에서 joint embedding learning을 위한 입력으로 활용한다.
 Fig. 1. VQA2.0 데이터셋의 이미지, 질문(Q), 답변(A) 예시. 이 경우, region-based visual feature는 질문을 잘 처리하지 못한다.
Fig. 1. VQA2.0 데이터셋의 이미지, 질문(Q), 답변(A) 예시. 이 경우, region-based visual feature는 질문을 잘 처리하지 못한다.
서로 다른 modality 간의 **의미론적 간극(semantic gap)**은 cross-modality 연구에서 항상 가장 중요한 도전 과제 중 하나로 다루어져 왔다. Visual Question Answering (VQA) [3] 및 image captioning [35]과 같은 초기 vision-language 연구들은 이미지 분류 task에서 사전학습된 모델로부터 직접 추출된 CNN feature를 활용했다. 이후 Visual Genome Dataset [16]의 도입과 Bottom-Up and Top-Down Attention model [2]의 제안과 함께, 위에서 언급된 pre-trained 모델을 포함한 대부분의 최신 vision-language 방법들은 더 나은 성능을 위해 객체 탐지 모델(예: Faster R-CNN)에서 추출된 region-based visual feature를 활용한다. 그러나 region-based visual feature extractor는 특정 시각 task(예: 객체 탐지)를 위해 설계되었으며, 이는 언어 이해와의 정보 간극을 유발한다. 객체의 모양, 겹치는 객체 간의 공간 관계 등과 같은 중요한 시각 정보 요소들이 손실된다. 더욱이, feature 표현 능력은 해당 task-specific 모델의 주어진 카테고리로 제한되며, 장면(scene)이나 감정(sentiment)과 같이 훨씬 더 넓은 의미의 시각 정보는 객체 탐지 모델에서 손실된다. Figure 1에서 region-based visual feature가 잘 처리하지 못하는 몇 가지 예시를 보여준다. 예시 (A)에서 객체 탐지 모델이 비행기의 상태를 파악하기는 어렵다. 예시 (B)에서 "girl"과 "ground"를 탐지할 수 있더라도, 영역 간에 겹침이 있기 때문에, bounding box만으로는 실제 공간 관계를 판단하기가 더욱 어려워진다. 유사하게 예시 (C)에서 "giraffe"의 시각 feature만으로는 동물의 상태를 추론하기 어렵다.
Transformer를 사용하여 cross-modality joint learning을 위해 region-based visual feature와 language embedding을 입력으로 사용하는 기존 방법들은 visual feature가 표현하는 시각적 의미에 제한된다. 따라서 우리는 bounding box의 한계를 넘어 이미지 내 시각 정보의 모든 잠재력을 vision-language learning에 활용하고자 한다. 우리는 이미지 픽셀과 텍스트를 정렬하여 시각 및 텍스트 정보 간에 보다 철저한 의미론적 embedding을 구축하는 Pixel-BERT를 제안한다. Pixel-BERT는 세 부분으로 구성된다:
- 이미지 픽셀을 입력으로 받아 visual embedding learning을 수행하는 fully convolutional neural network (CNN),
- BERT 기반의 word-level token embedding,
- visual 및 language embedding의 joint learning을 위한 multi-modal Transformer.
대부분의 vision-language task를 위한 범용적인 표현(universal representation)을 학습하기 위해, 우리는 먼저 다른 cross-modality pre-training 방법들 [6, 18, 19, 21, 22, 29, 33, 41]과 유사하게 이미지-문장 쌍 데이터셋으로 모델을 pre-train한다. 우리의 pre-training 절차에서는 두 가지 pre-training task와 한 가지 pre-training mechanism이 사용된다. 언어의 경우, 우리는 다른 pre-training 연구들 [6, 29, 33]을 따라 **Masked Language Modeling (MLM)**을 사용하여 주변 텍스트와 이미지를 통해 마스킹된 토큰을 예측한다. 비전의 경우, 픽셀 수준 feature 예측의 어려움을 보완하기 위해 random pixel sampling mechanism을 제안한다. random pixel sampling mechanism은 시각 feature 학습의 견고성(robustness)을 향상시키고 과적합(overfitting) 문제를 극복한다. vision-language 상호작용을 위해, 우리는 [6]을 따라 **Image-Text Matching (ITM)**을 적용하여 이미지와 문장 쌍이 일치하는지 여부를 분류한다.
본 논문의 기여는 다음과 같이 요약된다:
- 우리는 CNN 기반 visual encoder와 deep multi-modal Transformer로 구성된 Pixel-BERT를 제안하여 visual 및 language embedding을 공동으로 학습한다. 우리는 self-supervised learning을 사용하여 픽셀 및 텍스트 수준에서 vision과 language 의미를 정렬하는 것을 처음으로 고려한다.
- 우리는 모델을 pre-training 방식으로 사용하고, 시각 표현 학습의 견고성을 향상시키기 위해 random pixel sampling mechanism을 제안한다.
- 광범위한 실험을 통해 VQA, Image-Text Retrieval 및 NLVR를 포함한 다양한 task에서 state-of-the-art 성능을 달성함으로써 우리 접근 방식의 효과를 입증한다. 특히, 우리 접근 방식은 VQA의 단일 모델 성능을 공정한 비교에서 이전 SOTA [6]보다 2.17점 향상시켰으며, 심지어 더 큰 모델보다도 높은 성능을 보인다.
2 Related Works
2.1 Pre-training Mechanism
Vision-language task에서 더 나은 joint representation을 얻기 위해서는 의미론(semantics)에 대한 더 깊은 이해가 중요하다. 시각 콘텐츠 이해를 위해, 순수한 시각 이해를 위한 여러 backbone 모델 [13, 32, 38]이 제안되었으며, 이들은 대규모 데이터셋에서 그 효과를 입증했다 [8]. 선구적인 연구 [24]는 사전학습된 backbone 모델을 다양한 다운스트림 task에 fine-tuning함으로써 **일반화 능력(generalizability)**을 보여주기도 한다. 언어 이해 측면에서는 최근 몇 년간 대규모 contextualized pre-training을 통해 범용적인 backbone 모델을 구축하는 데 급속한 발전이 있었다 [7, 9, 23]. 이들은 다양한 task에서 성능을 크게 향상시켰다.
Cross-modality 연구를 위해 최근 많은 방법들 [6, 18, 19, 21, 22, 29, 31, 33, 41]이 제안되었다. 이들은 서로 다른 modality 간의 시각 및 문장 dense connection을 학습하는 데 중점을 둔다. 기존 방법들은 네트워크 구조에 따라 크게 두 그룹으로 나눌 수 있다. 일부 연구 [2, 13, 33]는 Transformer [34] 기반의 two-stream neural network를 활용한다. 이 two-stream neural network는 시각 및 언어 정보를 각각 처리한 후, **다른 Transformer layer를 통해 이들을 융합(fuse)**한다. 반면에, single-stream neural network를 적용하는 방법들 [1, 6, 18, 22, 29]도 있다. 이들은 BERT [9]를 사용하여 detection bounding box feature와 sentence embedding feature 간의 bi-directional joint distribution을 학습한다. 이들 간의 차이점은 학습 방법, 손실 함수, 그리고 데이터셋에 있다. Pixel-BERT는 두 번째 그룹에 속하지만, 우리의 visual embedding 방식은 이 모든 방법들과 다르다.
2.2 Visual Feature Embedding in Vision and Language Tasks
VQA [11], 이미지 캡셔닝 [39]과 같은 교차 모달리티(cross-modality) task는 문장과 시각적 의미론(semantics)을 모두 이해해야 한다. 초기 방법 [5]은 사전학습된 분류 모델에서 추출한 CNN feature를 시각적 표현으로 직접 사용했다. 이후 Visual Genome Dataset [16]의 도입과 Bottom-Up and Top-Down Attention 모델 [2]의 제안과 함께, 최근의 비전 및 언어 관련 연구들은 더 나은 성능을 위해 객체 탐지 모델(예: Faster R-CNN [24])에서 추출한 region-based visual feature를 활용한다 [6, 15, 22, 33].
이러한 방법들은 Visual Genome 탐지 카테고리에 의해 시각적 feature의 의미론이 제한된다는 한계가 있다. 반면 언어 도메인은 훨씬 더 많은 의미론적 정보를 포함한다. 우리 모델과 다른 방법들 간의 주요 차이점 중 하나는 시각적 의미론 임베딩(visual semantic embedding) 방법이다. 우리는 탐지 바운딩 박스 feature를 시각 및 언어 임베딩 학습을 위한 시각적 의미론 표현으로 사용하는 대신, visual encoder 표현 학습 네트워크를 하나의 프레임워크로 통합하고 원본 이미지를 시각 입력으로 사용한다. 우리는 이 모델을 더 풍부한 시각적 의미론 학습을 위한 교차 모달리티 사전학습(cross-modality pre-training)에 활용한다.
3 Approach
전체 구조는 Fig. 2에 나타난 것처럼, CNN 기반 visual encoder와 cross-modal Transformer를 사용하여 visual 및 language embedding 학습을 수행하는 end-to-end 프레임워크인 Pixel-BERT이다. Image-sentence pair를 입력으로 받아 joint embedding feature를 생성한다. 전체 네트워크는 MLM과 ITM task로 end-to-end pre-training이 가능하며, downstream task에 적용하기 적합하다.
이 절에서는 먼저 3.1절에서 Transformer 모델을 다시 살펴보고, 3.2절에서 Pixel-BERT의 모델 구조를 자세히 설명하며, 3.3절에서 pre-training 절차를 설명한다.
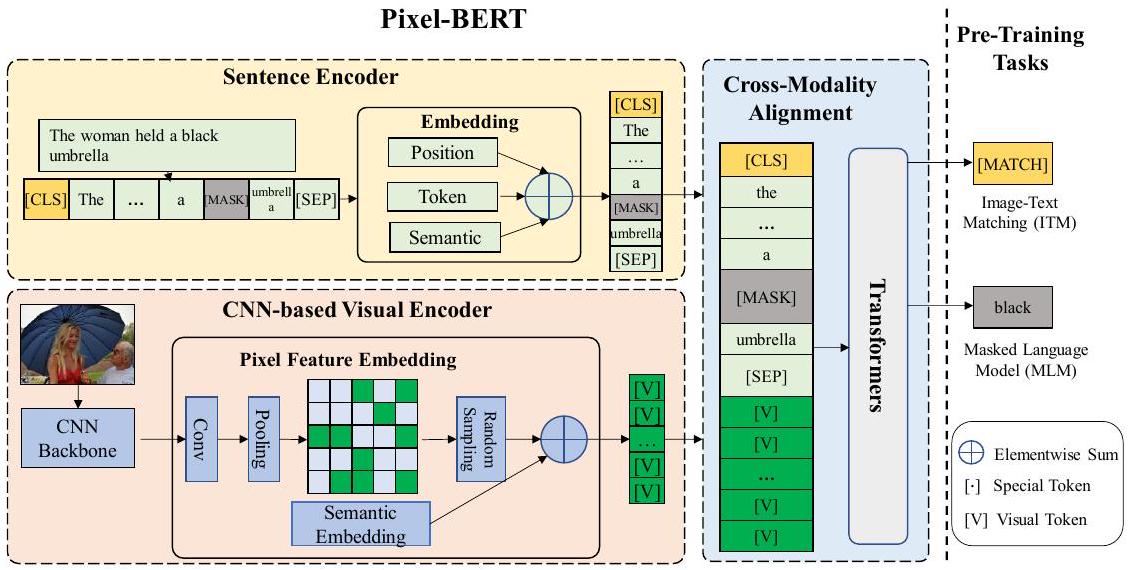
그림 2. Pixel-BERT: 모델은 visual feature embedding 모듈, sentence feature embedding 모듈, 그리고 cross-modality alignment 모듈로 구성된다. Pixel-BERT는 image-sentence pair를 입력으로 받아 각 입력 요소의 attention feature를 출력한다. 이미지는 pixel 단위로 pixel feature embedding 모듈에 전달되고, 문장은 token 단위로 sentence feature embedding 모듈에 전달된다. 모델은 MLM과 ITM task로 pre-training할 수 있으며, VQA, retrieval 등 다양한 downstream task에 유연하게 적용될 수 있다.
3.1 Revisit Transformer
Pixel-BERT는 BERT [9]를 cross-modality alignment module로 채택한다. BERT는 다층 양방향 Transformer encoder로, 모든 입력 요소의 의존성을 모델링할 수 있다. Pixel-BERT를 소개하기 전에, 먼저 Transformer의 아키텍처를 다시 살펴본다.
기본 Transformer 모듈의 두 가지 핵심 연산은 self-attention과 feed-forward이다. 입력 가 주어졌을 때 (은 요소의 개수, 는 feature 차원), 우리는 먼저 다음 식을 통해 입력으로부터 **query , key , value **를 얻는다:
여기서 는 각각 해당 가중치 행렬이다. 우리는 다음 식을 통해 **attention 출력 **를 계산한다:
여기서 는 각 입력 요소의 self-attention 가중치를 나타낸다. 출력은 다음과 같이 feed-forward network에 의해 계산된다:
여기서 FFN은 [34]에서와 같이 ReLU 활성화 함수를 가진 완전 연결(fully-connected) layer 그룹으로 구성된다. 위 연산들은 각 요소 자신을 포함하여 모든 입력 요소들 사이에 dense connection을 구축한다.
cross-modality task에서 입력 요소들은 시각(visual) 및 언어(language) 도메인에서 온다. 우리는 Transformer를 통해 intra-domain (즉, 이미지-이미지, 문장-문장) 및 inter-domain (즉, 이미지-문장) 모두에서 dense connection을 구축할 것을 제안하며, 이는 Sec. 3.2에서 자세히 설명될 것이다.
3.2 Model Architecture
vision-language task의 경우, 우리는 서로 다른 modality로부터 두 가지 유형의 입력을 받는다. 자연어는 일반적으로 문장 형태로, 단어 시퀀스로 분할될 수 있다. 우리는 [6, 18, 21, 22, 29, 33, 41]을 따라 먼저 문장의 각 단어를 tokenize하고, 각 token을 벡터로 embedding한다. 시각 도메인의 입력은 일반적으로 이미지이다. 대부분의 최신 방법들은 Faster R-CNN [2]과 같은 object detection 모델로 region-based feature를 추출하여 시각 입력을 표현한다. 그러나 이러한 region-based visual feature extractor는 특정 시각 task(즉, object detection)를 위해 설계되었기 때문에, 언어 이해와의 정보 격차를 초래할 수 있다. 구체적으로, bounding box는 직사각형 형태이므로 노이즈가 많은 배경을 포함할 수 있고, 형태 및 공간 관계 정보를 놓칠 수 있다. 게다가, feature 표현 능력은 이러한 task-specific 모델이 제공하는 카테고리에 의해 제한된다. 또한, 장면이나 감정과 같은 더 넓은 의미의 시각 정보도 object detection 모델에서는 손실된다. 원본 이미지의 시각 정보를 완전히 활용하기 위해, 우리는 픽셀로부터 visual embedding을 학습하는 vision-language task를 위한 end-to-end 프레임워크인 Pixel-BERT를 제안한다.
Sentence Feature Embedding
우리는 BERT [9]를 따라 문장의 언어 정보를 인코딩한다. 문장이 입력으로 주어지면, 먼저 이를 단어 시퀀스로 분할하고, WordPiece를 사용하여 각 단어를 token으로 tokenize한다. 그런 다음 embedding matrix를 사용하여 각 token을 벡터로 embedding한다. 여기서 우리는 embedded sequence를 로 표현하며, 은 시퀀스 길이, 는 embedding 차원을 나타낸다. 우리는 다른 BERT 기반 언어 방법들을 따라 위치 정보를 인코딩하기 위해 positional embedding을 추가한다. 문장의 최종 언어 표현은 이다. 위치 에서의 각 표현은 다음과 같이 계산된다:
여기서 는 위치 에서의 embedding vector를 나타내고, 는 semantic embedding vector이며, LayerNorm은 [4]에 설명된 정규화 함수이다. 위치 embedding과 semantic embedding의 합은 하나의 embedding과 수학적으로 동등하므로, 구현에서는 항을 생략할 것이다.
Image Feature Embedding
대부분의 최신 vision-language 방법들은 Bottom-Up and Top-Down Attention [2]을 따라 Visual Genome 데이터셋으로 학습된 Faster R-CNN [24]을 통해 시각 feature를 추출한다. 이 detector는 미리 정의된 카테고리 아래에서 영역을 먼저 감지한 다음, 최종 classifier 이전의 feature를 출력으로 사용함으로써 영역 feature를 추출한다. 이렇게 추출된 feature의 표현 능력은 감지 카테고리에 제한될 것이다.
task-specific 카테고리, 형태 및 경계의 한계를 극복하기 위해, 우리는 bounding box를 사용하는 대신 픽셀로부터 이미지를 표현하는 방식을 학습한다. 픽셀 feature는 ResNet [13]과 같은 CNN visual backbone에 의해 학습된다. 입력 이미지 가 주어지면, 먼저 CNN backbone을 사용하여 feature를 추출한 다음, 공간 차원을 따라 feature를 평탄화한다. 평탄화된 feature를 로 표기하며, 여기서 는 feature 픽셀의 수를 나타낸다. visual embedding feature 는 다음과 같이 계산될 수 있다:
여기서 는 언어 embedding과의 차이를 구별하기 위한 semantic embedding vector이다. 모든 픽셀이 동일한 를 공유하므로, 이 embedding vector는 CNN backbone과 결합될 bias 항으로 간주될 수 있다. 우리의 구현에서는 ResNet 또는 ResNeXt를 backbone으로 채택하고, visual feature map의 공간 차원을 줄이기 위해 max pooling layer를 추가한다. 입력 이미지 의 공간 크기는 총 64배로 down-sample될 것이다.
Cross-Modality Module
우리는 이미지 픽셀과 언어 token 간의 cross-modality attention을 학습하기 위해 Transformer를 채택한다. sentence embedding vector와 픽셀 feature를 얻은 후, 모든 벡터를 결합하여 입력 시퀀스를 구성한다. 또한 joint classification feature 학습 및 token 길이 지정을 위해 두 개의 특수 token인 [CLS]와 [SEP]를 추가한다. joint-learning Transformer의 최종 입력 시퀀스는 다음과 같이 공식화된다:
시각 표현 학습을 위한 CNN backbone과 언어 표현 학습을 위한 Transformer는 단일 모델로 결합되어 end-to-end 학습이 가능하다. Transformer의 출력에 학습 supervision을 적용할 때, gradient는 CNN backbone으로 역전파될 수 있으며, 따라서 학습된 visual feature는 시각 도메인과 문장 도메인 간의 domain gap을 줄여 target task 학습에 더 적합하게 될 것이다.
3.3 Pre-Training
비전 및 언어 관련 task를 위한 범용적인 시각 및 문장 표현(representation)을 학습하기 위해, 우리는 자기 지도 학습(self-supervised method) 방식을 적용하여 대규모 통합 데이터셋에서 모델을 사전학습한다. 우리는 [6, 18, 21, 22, 29, 33, 41]의 연구를 따라 **Masked Language Modeling (MLM)**과 **Image-Text Matching (ITM)**의 두 가지 사전학습 task를 수행한다. 영역 기반(region-based) 시각 feature를 추출하기 위해 detection model에 의존하는 기존 방법들과 달리, 우리 모델은 원본 이미지를 입력으로 사용하여 사전학습 task를 수행한다.
Masked Language Modeling
모델을 사전학습하고 언어 token과 시각적 내용 간의 매핑(mapping)을 구축하기 위해, 우리는 cross-modality 도메인에서 Masked Language Model (MLM) task를 수행한다. 구체적으로, 우리는 언어 token을 0.15의 확률로 무작위로 마스킹하고, 모델이 다른 마스킹되지 않은 token과 시각 token을 기반으로 마스킹된 token을 예측하도록 요구한다. 학습 목표 은 다음과 같이 공식화될 수 있다:
여기서 은 마스킹된 token을 나타내고, 는 모델 파라미터이며, 는 생성된 likelihood 함수를 나타낸다.
BERT를 사용한 단일 모달리티(single-modality) task에서는 마스킹된 token이 언어 도메인 내의 주변 마스킹되지 않은 token으로부터만 예측되는 것과 달리, 우리 모델은 언어 모달리티만으로는 모호성이 발생할 수 있는 cross-modality 시나리오를 처리할 수 있다. MLM task는 모델이 언어 token과 시각 token 모두로부터 마스킹된 token을 추론하도록 유도하여, 언어 모달리티와 시각 모달리티 간의 매핑을 구축하는 데 도움을 줄 수 있다.
Image-Text Matching
**이미지-텍스트 검색(retrieval)**과 같은 일부 다운스트림 task는 모델이 문장이 이미지를 잘 설명하는지, 즉 서로 일치하는지 여부를 구별하도록 요구한다. cross-modality 매칭을 강화하기 위해, 우리는 이전 연구 [6]와 같이 사전학습을 위한 Image-Text Matching (ITM) task를 채택한다. 학습 중에는 데이터셋에서 제공하는 모든 이미지-문장 쌍을 샘플링하여 긍정 샘플(positive samples)로 간주한다. 또한 데이터셋을 무작위로 섞어 일치하지 않는 이미지-문장 쌍을 부정 샘플(negative samples)로 간주한다. 학습 편향을 방지하기 위해 긍정 샘플과 부정 샘플의 수를 동일하게 채택한다.
우리는 [CLS] token의 joint embedding feature에 이진 분류기(binary classifier)를 적용하여 입력 이미지와 문장이 일치하는지 여부를 분류한다. ITM task는 다음 손실 함수에 의해 구동된다:
여기서 는 이미지와 문장이 일치하는지 여부를 나타내고, 는 생성된 분류 점수 함수를 나타낸다.
Pixel Random Sampling
feature 학습의 견고성(robustness)을 향상시키고 overfitting을 방지하기 위해, dropout [28]에서 영감을 받아 사전학습 중에 feature 픽셀을 무작위로 샘플링하는 방식을 제안한다. 각 iteration에서 픽셀 feature를 추출한 후, 우리는 그 중 일부를 무작위로 샘플링하여 Transformer에 입력한다. 이러한 **픽셀 무작위 샘플링(pixel random sampling)**은 두 가지 방식으로 모델 학습에 이점을 제공할 수 있다. 첫째, 불완전한 시각 입력으로부터 모델이 의미론적 지식을 학습하도록 유도하여 견고성을 향상시킬 수 있다. 둘째, 입력 요소의 수를 줄여 계산 비용을 절감하고 학습 속도를 가속화할 수 있다. 우리 실험에서는 각 입력 이미지에 대해 feature map에서 고정된 수의 100개 픽셀을 무작위로 샘플링할 것이다. 이러한 픽셀 무작위 샘플링 전략은 사전학습 단계에서만 적용된다는 점에 유의해야 한다. 첫 번째 이유는 fine-tuning 단계가 몇 epoch 동안만 지속되므로 다운스트림 task에서 무작위 샘플링이 정보 손실을 초래할 수 있기 때문이며, 또 다른 이유는 다운스트림 task의 학습 및 테스트 입력이 일관되도록 보장해야 하기 때문이다.
| Task | Dataset | #Imgs | #Text | Training | Testing | Metric |
|---|---|---|---|---|---|---|
| Pretrain | VG | 101 K | 5.06 M | train+val | - | - |
| COCO | 106 K | 533 K | train+restval | - | - | |
| VQA | VQA2.0 | 204 K | 1.1 M | train+val | test-dev/test-std | VQA-score |
| NLVR | NLVR | 214 K | 107 K | train | dev/test | Accuracy |
| IR & TR | COCO | 92 K | 460 K | train+restval | test | Recall@1,5,10 |
| Flickr30K | 32 K | 160 K | train+restval | test |
Table 1. 사전학습 및 다운스트림 task에 사용된 다양한 데이터셋, 데이터 분할 및 평가 지표 통계.
4 Experiments
4.1 Pre-training
데이터셋
우리는 Pixel-BERT를 두 개의 대규모 이미지-문장 데이터셋인 MS-COCO 20과 **Visual Genome [16]**으로 사전학습한다.
MS-COCO의 이미지 수준 캡션 어노테이션과 Visual Genome의 영역 수준 캡션 어노테이션을 사전학습을 위한 학습 데이터로 활용한다. Visual Genome 데이터셋의 경우, 학습을 위해 train 및 val 데이터를 모두 사용한다. MS-COCO의 경우, [14]를 따라 전체 데이터셋을 train, restval, val, test로 분할한다. 우리의 다운스트림 task 중 하나인 이미지-텍스트 검색이 MS-COCO 데이터셋에서 수행되므로, 데이터 유출을 피하기 위해 train 및 restval 분할을 학습에 사용한다. 학습 샘플의 통계는 Table 1의 첫 두 행에서 확인할 수 있다.
구현 세부 사항
사전학습 동안, Pixel-BERT는 각 iteration에서 이미지-문장 쌍의 batch를 입력으로 받는다. 우리는 먼저 BERT에서 사용된 **WordPiece tokenizer [37]**를 사용하여 각 문장을 language token으로 분할한다.
ablation 분석을 위해 ResNet-50을 visual backbone으로 사용하며, 더 나은 성능을 얻기 위해 [27, 29]를 따라 더 강력한 ResNeXt-152를 채택한다. 우리는 ImageNet [8]에서 공개적으로 접근 가능한 사전학습된 모델을 사용하여 visual backbone의 파라미터를 초기화한다.
ResNet-50을 visual backbone으로 사용할 때는 입력 이미지의 짧은 변을 800으로, 긴 변은 1333 미만으로 제한한다. ResNeXt-152를 사용할 때는 GPU 메모리 사용량을 고려하여 짧은 변과 긴 변의 제한을 각각 600과 1000으로 조정한다.
[40]에서 주장했듯이, CNN visual backbone과 Transformer는 서로 다른 종류의 optimizer를 선호할 수 있으므로, 우리는 visual backbone과 Transformer에 대해 다른 optimizer 설정을 채택한다. 구체적으로, CNN backbone을 최적화하기 위해 learning rate 1e-2, weight decay 5e-4의 SGD를 사용하고, Transformer optimizer로는 learning rate 1e-4, weight decay 1e-2의 AdamW를 사용한다. 우리는 64개의 NVIDIA Tesla V100 GPU에서 batch size 4096 샘플로 40 epoch 동안 Pixel-BERT를 사전학습한다. learning rate는 25번째와 35번째 epoch에서 10배 감소시킨다.
| Model | test-dev | test-std |
|---|---|---|
| MUTAN[5] | 60.17 | - |
| BUTD[2] | 65.32 | 65.67 |
| ViLBERT[21] | 70.55 | 70.92 |
| VisualBERT[19] | 70.80 | 71.00 |
| VLBERT[29] | 71.79 | 72.22 |
| LXMERT[33] | 72.42 | 72.54 |
| UNITER[6] | 72.27 | 72.46 |
| Pixel-BERT (r50) | 71.35 | 71.42 |
| Pixel-BERT (x152) | 74.45 | 74.55 |
Table 2. VQA에서 Pixel-BERT와 다른 방법들의 평가.
| Model | dev | test-P |
|---|---|---|
| Image Only [30] | 51.6 | 51.9 |
| CNN+RNN [30] | 53.5 | 52.4 |
| MaxEnt [30] | 54.1 | 54.8 |
| VisualBERT [19] | 67.4 | 67.0 |
| LXMERT [33] | 74.9 | 74.5 |
| UNITER [6] | 75.4 | 76.0 |
| UNITER [6] | 77.1 | 77.9 |
| Pixel-BERT | 71.7 | 72.4 |
| Pixel-BERT | 76.5 | 77.2 |
Table 3. NLVR task 평가. 는 paired method 사용을 나타낸다. 는 pair-biatt method 사용을 나타낸다.
4.2 Downstream Tasks
우리는 Visual Question Answering (VQA) 및 Natural Language for Visual Reasoning for Real (NLVR )를 포함한 여러 다운스트림 vision-language task에서 모델을 평가하였다. 각각 VQA 2.0 [12] 및 NLVR [30] 데이터셋을 사용하였다. 또한 Flickr30K [38] 및 MS-COCO [20] 데이터셋에서 image-to-text 및 text-to-image retrieval task에 대한 실험도 수행하였다. 데이터셋 분할, 학습/검증/테스트 데이터 수, 평가 지표를 포함한 모든 사용된 데이터셋의 상세 통계는 Table 1에서 확인할 수 있다. 이후 표에서는 두 가지 다른 visual backbone 설정(r50은 ResNet-50, x152는 ResNeXt-152를 나타냄)에서 Pixel-BERT의 성능을 보고한다. 우리 모델은 12-Layer Transformer를 언어 모듈로 채택하므로, 주로 동일한 Transformer 설정을 사용하는 다른 접근 방식과 실험 결과를 비교한다.
Visual Question Answering
Visual Question Answering (VQA) task에서 Pixel-BERT는 이미지와 질문을 입력으로 받아 답변을 예측한다. 우리는 이를 [CLS] token으로부터 multi-layer perception을 학습하여 이진 cross-entropy loss를 통해 분류 문제로 모델링한다. 사전학습과 동일한 optimizer 설정을 따른다. 모델은 16개의 NVIDIA Tesla V100 GPU에서 batch size 256으로 18 epoch 동안 fine-tuning된다. 초기 learning rate는 사전학습과 동일하며, 12번째와 16번째 epoch에서 learning rate를 10배 감소시킨다.
VQA task에 대한 실험 결과는 Table 2에 보고되어 있다. 우리는 우리의 접근 방식을 최신 state-of-the-art 접근 방식과 비교한다. Table 2에서, ResNet-50을 visual backbone으로 사용하는 우리 접근 방식이 test-dev split에서 71.35점을 달성하여, ResNet-101 또는 ResNeXt-152와 같은 더 강력한 visual backbone을 사용하는 ViLBERT [21] 및 VisualBERT [19]를 이미 능가함을 확인할 수 있다. ResNeXt-152 backbone을 장착했을 때, 우리 모델 Pixel-BERT는
| Model | TR | IR | ||||
|---|---|---|---|---|---|---|
| R@1 R@5 R@10 | R@1 R@5 | R@10 | ||||
| VSE++[10] | 52.9 | 80.5 | 87.2 | 39.6 | 70.1 | 79.5 |
| SCAN[17] | 67.4 | 90.3 | 95.8 | 48.6 | 77.7 | 85.2 |
| SCG[26] | 71.8 | 90.8 | 94.8 | 49.3 | 76.4 | 85.6 |
| PFAN[36] | 70.0 | 91.8 | 95.0 | 50.4 | 78.7 | 86.1 |
| ViLBERT[21] | - | - | - | 58.2 | 84.9 | 91.5 |
| Unicoder-VL[18] | 86.2 | 96.3 | 99.0 | 90.9 | 94.9 | |
| UNITER[6] | 84.7 | 97.1 | 99.0 | 91.2 | 95.2 | |
| ours (R50) | 75.7 | 94.7 | 97.1 | 59.8 | 85.5 | 91.6 |
| ours (X152) |
Table 4. Flickr30K 데이터셋에서 image-to-text retrieval (TR) 및 text-to-image retrieval (IR)에 대한 Pixel-BERT와 다른 방법들의 평가.
test-dev split에서 74.45점, test-std split에서 74.55점을 달성하여 기존의 모든 연구들을 크게 능가한다. 이 결과는 24-Layer Transformer를 언어 모듈로 사용하고 VQA test-std split에서 73.40점을 얻은 UNITER (Large)의 성능보다도 높다는 점에 주목할 만하다. 이러한 명확한 개선은 이미지의 픽셀 수준에서 시각 및 언어 attention을 학습하는 것이 visual encoder 표현에 이점을 주고, 이후 시각 및 언어 임베딩 학습을 향상시킬 수 있음을 보여준다.
Natural Language for Visual Reasoning for Real
Natural Language for Visual Reasoning for Real (NLVR ) task는 언어 설명이 주어진 두 이미지 쌍과 관련이 있는지 여부를 모델이 예측하도록 요구한다. 우리 모델에서는 두 개의 이미지-언어 쌍을 Pixel-BERT에 입력하여 [CLS] token으로부터 두 개의 임베딩 벡터를 얻고, 이들의 연결(concatenation)을 사용하여 cross-entropy loss를 통해 "true" 또는 "false"를 분류하는 classifier를 학습한다. optimizer, epoch 수, learning rate 설정은 모두 위에서 설명한 VQA 설정과 동일하다. batch size는 VQA의 절반이다.
우리는 NLVR 를 dev 및 test-P split 모두에서 평가한다. 사전학습 task 및 다른 다운스트림 task와 달리, NLVR 는 한 번에 두 이미지 쌍을 입력으로 받는다. Table 3에 제시된 결과에서 Pixel-BERT가 dev split에서 76.5%의 정확도를, test-P split에서 77.2%의 정확도를 얻었음을 확인할 수 있다. 두 이미지-언어 쌍을 구성하는 우리 설정은 LXMERT 및 UNITER의 "Pair" 설정과 동일하며, Table 3의 비교를 통해 Pixel-BERT가 이들을 능가함을 알 수 있다. 이러한 결과는 Pixel-BERT가 다른 유사한 입력 형식에도 적응할 수 있음을 보여준다.
Image-Text Retrieval
우리는 retrieval task를 다른 연구들 [6, 18, 29]과 유사하게 랭킹 문제로 간주한다. 학습 중에는 이미지-문장 쌍의 각 이미지에 대해, 해당 쌍의 ground-truth caption을 positive sample로 사용하고, 다른 쌍에서 무작위로 20개의 관련 없는 caption을 negative sample로 추출한다. 우리는 모든 [CLS] token의 표현에 대해 fully-connected layer를 통해 쌍이 관련되어 있는지 여부의 점수를 예측하고, positive 이미지-캡션 쌍이 가장 높은 점수를 얻도록 softmax cross-entropy loss를 적용한다. 각 이미지 샘플에 대해 가장 높은 loss를 가진 5개의 negative sample에 대해서만 gradient를 역전파한다. retrieval task는 사전학습의 ITM task와 밀접하게 관련되어 있으므로, Transformer의 파라미터만 fine-tuning한다. optimizer로는 1e-4 learning rate와 1e-2 weight decay를 가진 AdamW를 채택한다. 모델은 GPU당 64개의 샘플 batch size로 8개의 NVIDIA Tesla GPU에서 fine-tuning된다. Flickr30K의 경우 10 epoch를 학습하고 6번째 epoch에서 learning rate를 감소시킨다. MS-COCO의 경우 4 epoch를 학습하고 2번째 epoch에서 learning rate를 감소시킨다.
우리는 text-to-image retrieval (IR) 및 image-to-text retrieval (TR) 하위 task 모두에서 recall@1, 5, 10을 보고하여 우리 접근 방식을 평가한다. Table 4는 Flickr30K의 1K 테스트 결과를 보여주며, Table 5는 MS-COCO의 5-fold 1K 테스트 결과와 5K 테스트 결과를 보여준다. 우리는 주로 12-layer Transformer를 언어 모듈로 채택한 Unicoder-VL 및 UNITER와 Pixel-BERT를 비교한다. image-to-text retrieval 하위 task의 경우, MS-COCO 1K 테스트 세트에서 recall@1에 대해 최소 0.6, MS-COCO 5K 테스트 세트에서 0.3의 성능 향상을 얻는다. 그리고 text-to-image retrieval 하위 task의 경우, Unicoder-VL 및 UNITER와 비교하여 MS-COCO 1K 테스트 세트에서 최소 1.9, MS-COCO 5K 테스트 세트에서 1.7의 향상으로 훨씬 더 중요한 결과를 달성한다. 이는 text-to-image retrieval task가 이미지의 전역적인 설명에 더 중점을 두며, 우리 아키텍처가 모델이 언어와 이미지 픽셀 간의 attention을 학습하도록 장려할 수 있기 때문이다.
| Visual <br> Backbone | Pre-traning <br> Tasks | Sampling <br> Method | VQA <br> test-dev | TR <br> val | IR <br> val | NLVR <br> dev | |
|---|---|---|---|---|---|---|---|
| 1 | ResNet-50 | - | Random | 63.50 | 52.4 | 39.6 | 52.0 |
| 2 | ResNet-50 | ITM | Random | 65.24 | 69.0 | 55.5 | 51.9 |
| 3 | ResNet-50 | MLM | Random | 71.13 | 67.1 | 52.7 | 70.9 |
| 4 | ResNet-50 | MLM+ITM | ALL | 70.84 | 72.0 | 57.7 | 71.3 |
| 5 | ResNet-50 | MLM+ITM | Random | 71.35 | 75.7 | 59.8 | 71.7 |
| 6 | ResNext-152 | MLM+ITM | Random | 74.45 | 87.0 | 71.5 | 76.5 |
Table 6. VQA, Flickr30K retrieval 및 NLVR 다운스트림 task에 대한 ablation study 결과. 사전학습 task 및 제안된 샘플링 방법의 효과를 평가한다. 첫 번째 행은 사전학습 없이 다운스트림 task를 학습하는 것을 나타낸다. VQA task의 경우 VQA 점수를, TR 및 IR의 경우 Recall@1을, NLVR 의 경우 정확도를 보고한다.
4.3 Ablation Study
우리는 Pixel-BERT의 각 구성 요소의 효과를 평가하기 위해 ablation 실험을 수행한다. 사전학습 모델의 성능은 단일 지표로 잘 측정될 수 없으므로, 우리는 다운스트림 task에서 평가된 결과를 사용하여 평가한다. ablation study 결과는 Table 6에서 확인할 수 있다.
먼저, 각 사전학습 task의 효과를 평가한다. 모델 (1)과 모델 (2), (3)의 비교를 통해, MLM과 ITM 모두 거의 모든 다운스트림 task에서 성능을 크게 향상시킬 수 있음을 알 수 있다. 특히 VQA의 경우, MLM은 약 7.6, ITM은 약 1.6의 성능 향상을 가져온다. retrieval task의 경우, ITM이 더 크게 기여하여 TR 및 IR 하위 task 모두에서 최소 13.0의 성능 향상을 가져온다. **NLVR<sup>2</sup>**는 MLM task에 크게 의존하며, MLM 없이는 학습이 수렴조차 할 수 없다. 사전학습의 효과는 다른 연구들 [629]에서 도출된 결론과 일치한다. 그리고 모델 (5)에서 이들을 조합하면 단일 task보다 각 task의 성능을 더욱 향상시킬 수 있다.
모델 (4)와 모델 (5)의 비교를 통해, 우리가 제안한 무작위 픽셀 샘플링(randomly pixel sampling) 방법이 VQA에서 0.5점, retrieval task에서 약 2.0점, NLVR<sup>2</sup>에서 0.4점의 성능 향상에 기여함을 알 수 있다. 이는 우리의 픽셀 무작위 샘플링 메커니즘의 효과를 보여준다. 모델 (6)에서는 [27/29]를 따라 visual backbone을 ResNext-152로 교체했으며, 그 결과 강력한 visual backbone을 가진 우리 모델이 성능을 크게 가속화할 수 있음을 보여준다.
4.4 Visualization
우리의 접근 방식인 Pixel-BERT가 언어와 픽셀 간의 cross-modality attention을 통해 시각적 표현을 잘 학습하는지를 추가로 확인하기 위해, MS-COCO val set의 예시들에 대한 attention map의 중간 결과를 시각화하였다. 시각화 결과는 Fig. 3에서 확인할 수 있다.
- Case (A) 결과에서, "dog", "grass", "frisbee" 토큰의 반응 영역이 실제로 정확한 영역에 분포되어 있음을 알 수 있다.
- **Case (B)**의 경우, "cutting"이 동사임에도 불구하고, 칼로 "cutting" 동작이 수행되는 가장 관련성 높은 영역에 attend할 수 있음을 발견할 수 있다.
- **Case (C)**에서는 "room" 토큰이 이미지 내의 정확한 영역에 attend할 수 있음을 확인했는데, 이 영역은 bounding box로 표현하기 어려운 부분이다.
 Fig. 3. Pixel-BERT의 첫 번째 Transformer layer에서 추출된 attention 영역 시각화.
attention 영역은 특정 토큰을 query로, 픽셀 feature를 key로 사용하여 추출되었다.
강조된 영역은 높은 attention 점수를 가진 영역을 나타낸다.
Fig. 3. Pixel-BERT의 첫 번째 Transformer layer에서 추출된 attention 영역 시각화.
attention 영역은 특정 토큰을 query로, 픽셀 feature를 key로 사용하여 추출되었다.
강조된 영역은 높은 attention 점수를 가진 영역을 나타낸다.
우리는 attention 학습을 유도하기 위해 어떠한 공간적 supervision(예: bounding box annotation)도 적용하지 않았음에도 불구하고, Fig. 3의 결과는 잘 정의된 task를 통해 Pixel-BERT가 cross-modality learning으로 영역 수준의 시각적 표현을 잘 학습할 수 있음을 보여준다. 이 결과는 또한 cross-modality learning이 시각 정보의 의미론적 이해에 역으로 도움을 줄 수 있는지를 연구하는 향후 연구에 많은 가능성을 제시한다.
5 Conclusion and Discussion
사전학습(Pre-training) 메커니즘은 vision 및 language 도메인에서 그 효과를 입증해왔다. 본 논문에서는 기존 연구들에서 흔히 사용되는 visual embedding 방법을 논의하고, region-based visual representation의 한계를 해결하고자 한다. 우리는 CNN 기반의 Visual Encoder를 제안하고, 이를 멀티모달 Transformer와 결합하여 Pixel-BERT를 end-to-end 방식으로 구축한다. 이를 통해 픽셀 및 텍스트 수준에서 시각 및 언어 콘텐츠 간의 더욱 정확하고 철저한 embedding을 구축하고자 한다. 우리는 이미지의 픽셀을 입력으로 사용하고, visual embedding 학습의 견고성(robustness)을 위해 무작위 픽셀 샘플링(random pixel sampling) 메커니즘을 적용한다.
우리는 Visual Genome 데이터셋과 MSCOCO 데이터셋에서 범용적인 시각 및 언어 embedding을 학습하기 위해 Pixel-BERT 기반의 사전학습 모델을 구축한다. Masked language model과 image-text matching은 사전학습을 위해 설계된 두 가지 task이다. 우리는 사전학습된 모델로 다운스트림 vision 및 language task를 수행했으며, VQA, NLVR, image-to-text retrieval, text-to-image retrieval을 포함한 대부분의 task에서 최고 성능을 달성했다.
annotated bounding box의 제약 없이, Pixel-BERT를 사용한 우리의 사전학습 모델은 더 큰 이미지-문장 쌍 데이터셋을 통해 이미지와 문장 모두에 대해 훨씬 강력한 representation을 제공할 수 있다. 우리는 Conceptual Caption Dataset [25]에서 모델을 사전학습하여 visual 및 language embedding을 더욱 최적화할 계획이다.
Masked visual prediction은 일부 연구에서 제안되었다. 예를 들어, [6]은 masked region의 예측을 위해 세 가지 유형의 masked region modeling을 제안했다. 본 논문에서는 region에 비해 픽셀 재구성의 어려움 때문에 이 부분을 무작위 픽셀 샘플링 메커니즘으로 대체한다. 향후에는 현재 접근 방식에서 시각 콘텐츠를 위한 self-supervised task를 설계하고 결합하는 방법에 대해 연구할 것이다.