S-CLIP: 적은 양의 캡션으로 전문 분야 Vision-Language 모델을 학습시키는 Semi-supervised 방법론
S-CLIP은 CLIP과 같은 Vision-Language 모델이 원격 탐사(remote sensing)와 같은 전문 분야에서 부족한 이미지-텍스트 쌍 데이터로 인해 겪는 성능 저하 문제를 해결합니다. 이 방법론은 소수의 레이블된 데이터와 다수의 레이블 없는 이미지를 활용하는 Semi-supervised learning 접근법을 제안합니다. S-CLIP은 Optimal Transport를 이용한 caption-level pseudo-label과 Partial Label Learning에 기반한 keyword-level pseudo-label이라는 두 가지 새로운 pseudo-labeling 전략을 사용하여, 적은 수의 이미지-텍스트 쌍만으로도 CLIP의 성능을 크게 향상시킵니다. 이를 통해 원격 탐사, 패션, 과학 등 다양한 전문 분야에서 모델의 적용 가능성을 확장합니다. 논문 제목: S-CLIP: Semi-supervised Vision-Language Learning using Few Specialist Captions
Mo, Sangwoo, et al. "S-clip: Semi-supervised vision-language learning using few specialist captions." Advances in Neural Information Processing Systems 36 (2023): 61187-61212.
S-CLIP: Semi-supervised Vision-Language Learning using Few Specialist Captions
Abstract
Vision-language model인 **CLIP(contrastive language-image pre-training)**은 자연 이미지 도메인에서 인상적인 결과를 보여주었다. 그러나 이러한 모델들은 **원격 탐사(remote sensing)**와 같은 특수 도메인에 적용될 때 종종 어려움을 겪으며, 해당 도메인에 적응하는 것은 학습에 사용할 수 있는 이미지-텍스트 쌍의 수가 제한적이기 때문에 더욱 도전적이다.
이러한 문제를 해결하기 위해 우리는 S-CLIP을 제안한다. S-CLIP은 추가적인 unpaired 이미지를 활용하여 CLIP을 학습시키는 semi-supervised learning 방법이다. S-CLIP은 contrastive learning과 language modality에 특화된 두 가지 pseudo-labeling 전략을 사용한다.
- Caption-level pseudo-label: unpaired 이미지와 paired 이미지 간의 optimal transport 문제를 해결하여 얻은, paired 이미지의 caption 조합으로 주어진다.
- Keyword-level pseudo-label: 가장 가까운 paired 이미지의 caption에 있는 keyword로 주어진다. 이는 정확한 label 대신 후보 label 집합을 가정하는 partial label learning을 통해 학습된다.
이러한 objective들을 결합함으로써, S-CLIP은 원격 탐사, 패션, 과학 그림, 만화 등 다양한 전문 도메인에서 입증되었듯이, 소수의 이미지-텍스트 쌍만으로 CLIP의 학습을 크게 향상시킨다. 예를 들어, S-CLIP은 원격 탐사 벤치마크에서 zero-shot classification 성능을 CLIP 대비 10% 향상시키고, image-text retrieval 성능을 4% 향상시킨다. 이는 supervised CLIP과 동일한 성능을 달성하면서도 3배 적은 이미지-텍스트 쌍을 사용한 결과이다.
1 Introduction
사전학습된 vision-language model은 놀라운 성공을 거두었으며, 수많은 다운스트림 task의 기반을 제공하고 있다 [1]. 그러나 이러한 모델들은 **원격 탐사(remote sensing) 또는 의료 영상(medical imaging)**과 같은 특수 도메인에 적용될 때 종종 어려움을 겪는다 [2]. 이는 모델이 웹에서 크롤링된 데이터로 학습되어, 이러한 도메인의 다양성과 복잡성을 완전히 포착하지 못할 수 있기 때문이다 [3,4]. 이 문제를 해결하기 위해 이전 연구들은 각 도메인에 대한 대규모 사전학습 데이터셋 구축에 집중해왔다 [5, 6]. 하지만 각 특수 도메인에 대한 캡션(caption)을 주석(annotate)하는 것은 비용과 시간이 많이 소요되어, 다양한 도메인에 걸친 적용 가능성을 제한한다.
몇몇 연구들은 vision-language 사전학습에 사용되는 이미지-텍스트 쌍의 수를 줄이려고 시도했다. 그러나 이러한 접근 방식은 종종 사전학습된 객체 탐지기(object detector) [7-9] 또는 클래스 주석이 달린 이미지 [10]와 같은 추가 정보에 의존하며, 이는 특수 도메인에는 적용하기 어려울 수 있다. 다른 접근 방식은 self-supervised learning을 활용하여 짝이 없는(unpaired) 데이터를 사용하지만 [11-14], 이미지-텍스트 쌍이 제공하는 정보를 완전히 활용하지 못한다. 소수의 이미지-텍스트 쌍을 활용하여 vision-language 사전학습을 개선하는 연구는 여전히 미개척 분야이다.
머신러닝의 다양한 분야, 특히 이미지 분류에서는 semi-supervised learning [15]이 제한된 주석만으로 모델을 학습시키는 인기 있는 접근 방식이다. 이 기술은 일반적으로 pseudo-labeling [16]에 의존하는데, 이는 레이블이 지정된 데이터로부터 정보를 전파하여 레이블이 없는 데이터에 대한 레이블을 예측하고, 이를 사용하여 모델을 개선한다. 이 접근 방식을 self-supervised learning [17]과 결합하면 소수의 클래스 레이블만으로도 분류기의 성능을 크게 향상시킬 수 있다 [18-22].
 Figure 1: 동기 (Motivation). (a) 원격 탐사 데이터셋인 RSICD의 이미지와 캡션. 클래스 레이블과 달리 캡션은 이미지마다 크게 달라, 가장 가까운 캡션을 할당하는 단순한 pseudo-labeling은 비효율적이다. (b) RSICD-CLS 데이터셋에 대한 zero-shot 정확도. 괄호 안은 원격 탐사 데이터셋으로 fine-tuning된 CLIP, 즉 CLIP-FT와의 격차를 나타낸다. 원본 CLIP은 이 특수 도메인에서 어려움을 겪으며, CLIP-FT는 큰 성능 향상을 보인다. (a)에서 논의된 바와 같이, 단순한 pseudo-labeling (Hard-PL)은 CLIP-FT에 해를 끼치는 반면, 우리의 S-CLIP은 상당한 개선을 제공한다.
Figure 1: 동기 (Motivation). (a) 원격 탐사 데이터셋인 RSICD의 이미지와 캡션. 클래스 레이블과 달리 캡션은 이미지마다 크게 달라, 가장 가까운 캡션을 할당하는 단순한 pseudo-labeling은 비효율적이다. (b) RSICD-CLS 데이터셋에 대한 zero-shot 정확도. 괄호 안은 원격 탐사 데이터셋으로 fine-tuning된 CLIP, 즉 CLIP-FT와의 격차를 나타낸다. 원본 CLIP은 이 특수 도메인에서 어려움을 겪으며, CLIP-FT는 큰 성능 향상을 보인다. (a)에서 논의된 바와 같이, 단순한 pseudo-labeling (Hard-PL)은 CLIP-FT에 해를 끼치는 반면, 우리의 S-CLIP은 상당한 개선을 제공한다.
자연스럽게 드는 질문은 semi-supervised learning, 특히 pseudo-labeling이 vision-language 사전학습을 개선할 수 있는지 여부이다. 그러나 이미지 분류 기술은 캡션이 다양하고 종종 각 이미지와 고유하게 연결되어 있기 때문에 vision-language model에 직접 적용할 수 없다. 따라서 가장 가까운 레이블이 지정된 이미지의 캡션을 할당하는 단순한 pseudo-labeling 접근 방식 (Hard-PL) [16]은 모델을 오도할 수 있다. Figure 1a는 시각적으로 유사한 이미지라도 "테니스 코트"와 같은 키워드를 공유할 수 있지만, 종종 다른 캡션을 가지고 있음을 보여준다. 결과적으로 Figure 1b는 Hard-PL이 CLIP fine-tuning의 성능을 저해함을 보여준다. 이러한 관찰은 캡션을 효과적으로 활용하는 pseudo-labeling 방법의 적절한 설계를 동기 부여한다.
기여 (Contribution)
우리는 vision-language 사전학습, 특히 CLIP [23]을 위한 새로운 semi-supervised learning 방법인 S-CLIP을 제안한다. S-CLIP은 Figure 2에 설명된 바와 같이 contrastive learning 및 언어 양식(language modality)을 위해 특별히 설계된 두 가지 새로운 pseudo-labeling 방법을 도입한다:
- 캡션 수준 pseudo-label (Caption-level pseudo-label). 우리는 레이블이 없는 이미지의 의미가 레이블이 지정된 이미지의 의미 조합으로 표현될 수 있다고 가정한다. 이를 위해 우리는 캡션 수준 pseudo-label을 레이블이 지정된 이미지에 대한 확률 분포로 정의하며, 이는 레이블이 없는 이미지와 해당 캡션 간의 관계를 안내한다. 특히, pseudo-label은 레이블이 없는 이미지와 레이블이 지정된 이미지 간의 optimal transport [24, 25] 문제를 해결하여 얻어진다. 이 접근 방식은 pseudo-label이 소수의 캡션으로 붕괴되는 것을 방지하고, 특히 레이블이 없는 이미지와 레이블이 지정된 이미지 간의 분포 변화(distribution shift)를 다룰 때 견고한 학습을 보장한다.
- 키워드 수준 pseudo-label (Keyword-level pseudo-label). 우리는 레이블이 없는 이미지가 시각적으로 유사한 이미지와 키워드를 공유한다고 가정한다. 비록 전체 캡션이 동일하지 않더라도 말이다. 따라서 우리는 키워드 수준 pseudo-label을 레이블이 없는 이미지에 가장 가까운 레이블이 지정된 이미지의 캡션에 있는 키워드 중 하나로 정의한다. 이 접근 방식은 단일한 정확한 키워드 대신 대상 키워드의 후보 집합을 생성하며, 학습은 partial label learning [26] 문제로 공식화될 수 있다. 이 손실은 모델이 레이블이 없는 이미지의 지역적 구성 요소를 이해하는 데 도움을 주며, 언어의 구조를 활용한다.
우리는 두 pseudo-label이 상호 보완적이라는 점에 주목한다. 캡션 수준 pseudo-label은 모델이 언어의 전역적 구조를 이해하는 데 도움을 주며, 이는 이미지-텍스트 검색에 더 효과적이다. 키워드 수준 pseudo-label은 모델이 지역적 구문(local phrases)을 이해하는 데 도움을 주며, 이는 zero-shot 분류에 더 효과적이다. 이들을 결합하면 두 가지 장점을 모두 얻을 수 있다 (Section 5.5).
우리는 원격 탐사 [27], 패션 [28], 과학 그림 [29], 만화 [30] 도메인을 포함하여 제한된 이미지-텍스트 쌍만 사용 가능한 다양한 특수 도메인에서 우리 방법의 효과를 입증한다. 원격 탐사 도메인에서 S-CLIP은 5개의 zero-shot 분류 및 6개의 이미지-텍스트 검색 task에서 CLIP fine-tuning 및 semi-supervised learning 경쟁자들을 능가한다. 예를 들어, S-CLIP은 WHU-RS19 [31]에서 zero-shot 정확도를 10.4% 향상시키고, UCM [32]에서 이미지-텍스트 검색 R@5를 CLIP fine-tuning 대비 4.4% 향상시킨다. S-CLIP은 레이블이 없는 이미지가 다른 데이터셋에서 추출된 경우에도 견고하게 유지된다. 만화 도메인에서 Simpsons [30] 데이터셋은 800개의 이미지-텍스트 쌍만 포함한다. 따라서 우리는 캡션이 없는 30,000개의 이미지로 구성된 Simpsons Characters [33] 데이터셋을 통합한다. 여기서 S-CLIP은 CLIP의 텍스트 이미지 검색 R@1을 11.8%에서 15.8%로 향상시켜 33%의 상대적 이득을 제공한다.
 Figure 2: 방법 개요 (Method overview). 제안하는 S-CLIP의 개념적 설명으로, (a) 캡션 수준 pseudo-label과 (b) 키워드 수준 pseudo-label을 활용한다. (a)에서 pseudo-label은 레이블이 없는 이미지와 레이블이 지정된 이미지 간의 optimal transport 문제를 해결하여 얻어지는 캡션에 대한 확률 분포로 주어진다. (b)에서 pseudo-label은 레이블이 없는 이미지에 가장 가까운 레이블이 지정된 이미지의 캡션에서 추출된 키워드 후보 집합으로 주어지며, 이는 partial label learning 알고리즘에 의해 학습된다.
Figure 2: 방법 개요 (Method overview). 제안하는 S-CLIP의 개념적 설명으로, (a) 캡션 수준 pseudo-label과 (b) 키워드 수준 pseudo-label을 활용한다. (a)에서 pseudo-label은 레이블이 없는 이미지와 레이블이 지정된 이미지 간의 optimal transport 문제를 해결하여 얻어지는 캡션에 대한 확률 분포로 주어진다. (b)에서 pseudo-label은 레이블이 없는 이미지에 가장 가까운 레이블이 지정된 이미지의 캡션에서 추출된 키워드 후보 집합으로 주어지며, 이는 partial label learning 알고리즘에 의해 학습된다.
2 Related work
Vision-language pre-training (VLP). Vision-language model의 사전학습(pre-training)은 놀라운 성공을 거두었으며, 많은 다운스트림 task의 기반을 제공하고 있다 [1]. 다양한 접근 방식이 제안되었는데, 여기에는 masked input 재구성 [34-38], vision 및 language modality의 joint embedding 학습 [23, 39-42], 이미지 입력으로부터 언어 설명 생성 [43-45], 그리고 사전학습된 unimodal 이미지 및 언어 모델 연결 [46-48] 등이 포함된다. CLIP [23]은 vision과 language modality 간의 joint embedding을 학습하는 대표적인 모델이다. CLIP은 zero-shot classification [23], image-text retrieval [49], open-vocabulary object segmentation [50, 51], out-of-distribution detection [52] 등 다양한 응용 분야에서 효과를 입증했다.
Specialist domain을 위한 VLP. 자연 이미지 도메인에서의 성공에도 불구하고, VLP 모델은 원격 탐사(remote sensing)와 같은 specialist domain에 적용될 때 종종 어려움을 겪는다 [2]. 이는 VLP 모델이 해당 도메인의 다양성과 복잡성을 포착하지 못할 수 있는 웹 크롤링 데이터로 학습되기 때문이다 [3, 4]. 이러한 분야의 데이터는 종종 희소하고, 접근성이 제한적이며, 전문가의 주석을 필요로 하므로, VLP 학습에 필요한 이미지-텍스트 쌍을 얻기 어렵다. 의료 [10, 53-59], 패션 [60-63], 원격 탐사 [64]를 포함한 전문 도메인을 위한 VLP 모델을 학습시키려는 시도가 있었지만, 이전 연구들은 주로 각 도메인에 대한 대규모 사전학습 데이터셋을 구축하는 데 중점을 두었으며 [5, 6], 이는 비용과 시간이 많이 소요될 수 있다.
제한된 쌍 데이터로 VLP 학습. 몇몇 연구들은 제한된 수의 이미지-텍스트 쌍으로 VLP 모델을 학습시켰다. Hsu et al. [65]은 adversarial domain adaptation을 사용하여 쌍이 없는(unpaired) 데이터 임베딩을 쌍이 있는(paired) 데이터와 유사하게 정규화했다. 그러나 이 접근 방식은 unpaired 데이터가 다른 분포에서 추출될 때 문제를 일으킬 수 있다. MedCLIP [10]은 클래스 레이블이 있는 이미지를 활용하여 캡션의 필요성을 줄였다. 그럼에도 불구하고, 여전히 클래스 레이블이 필요하여 대규모 unlabeled 데이터의 사용을 제한한다. 다른 연구들은 이미지 도메인에서 unsupervised 또는 semi-supervised VLP 학습을 탐구했다 [7-9]. 그러나 이들은 사전학습된 object detector에 의존하여 감지된 객체를 캡션의 키워드와 정렬하므로, specialist domain에는 적합하지 않다. 또 다른 연구들은 각 modality에 대한 self-supervised learning을 활용하지만 [11-14], 이미지-텍스트 쌍이 제공하는 정보를 완전히 활용하지 못한다. 이와 대조적으로, 우리의 방법은 이미지-텍스트 쌍을 활용하며 추가 정보 없이 일반적으로 적용 가능하다.
Semi-supervised learning. Semi-supervised learning [15]은 소규모 labeled 데이터셋과 대규모 unlabeled 데이터셋을 사용하여 모델을 학습시키는 것을 목표로 한다. Semi-supervised learning 기술은 두 가지 유형으로 분류할 수 있다:
- pseudo-labeling (또는 label propagation) [16, 66]: 소규모 labeled 데이터셋의 정보를 활용하는 방식.
- self-supervised learning [17]: unlabeled 데이터셋으로부터 representation을 학습하는 방식.
이러한 기술들을 결합하는 것은 semi-supervised learning, 특히 소수의 클래스 레이블로 분류기를 학습시키는 데 놀라운 성공을 거두었다 [18-22]. 강건한 semi-supervised learning에 대한 이전 연구들은 unlabeled 및 labeled 데이터의 분포가 변화하는 시나리오에 중점을 둔다 [67-69]. 이 문제는 각 이미지에 대한 캡션의 고유성으로 인해 vision-language pre-training에서 자연스럽게 발생한다. 우리의 방법은 soft label을 사용하여 이 문제를 해결하며, unlabeled 이미지가 labeled 이미지와 다른 데이터셋에서 온 경우에도 강건하게 작동한다.
3 Background
우리의 semi-supervised vision-language 사전학습 방법을 설명하기 전에, contrastive language-image pre-training과 semi-supervised learning에 대한 간략한 개요를 제공한다.
3.1 Contrastive language-image pre-training
Contrastive Language-Image Pre-training (CLIP) [23]은 이미지 와 텍스트 를 연결하는 **공동 임베딩 공간(joint embedding space)**을 학습하는 인기 있는 vision-language model이다. CLIP은 **대조 학습(contrastive learning)**을 통해 **쌍을 이루는 이미지와 텍스트 배치 **를 사용하여 학습된다. 이때, 동일한 쌍에서 온 샘플은 **긍정(positive)**으로, 다른 쌍에서 온 샘플은 **부정(negative)**으로 간주된다. CLIP의 학습 목표는 두 가지 분류 task를 포함한다:
- 이미지가 주어졌을 때 텍스트를 예측하는
- 텍스트가 주어졌을 때 이미지를 예측하는
배치 내의 개 샘플에는 해당 쌍이 target으로 할당된다. 임베딩은 **단위 노름(unit norm)**을 갖도록 정규화되며, CLIP은 임베딩의 **코사인 유사도(cosine similarity)**에 온도 파라미터 를 적용한 softmax 함수를 사용하여 레이블을 예측한다.
구체적으로, 우리는 softmax classifier 를 입력 및 target 임베딩의 함수로 정의한다. 이를 통해 CLIP의 클래스 확률을 나타내는 와 를 표현할 수 있다. 이 확률들은 다음과 같이 계산된다: . CLIP 모델은 다음 목적 함수를 최소화한다:
여기서 는 cross-entropy loss를 나타내고, 는 -번째 요소가 1인 one-hot 벡터이다. CLIP 모델은 임베딩 공간에서 코사인 유사도를 계산하여 zero-shot 분류 또는 **이미지-텍스트 검색(image-text retrieval)**에 사용될 수 있다. 예를 들어, zero-shot 분류에서는 이미지 임베딩에 가장 가까운 클래스 prompt의 텍스트 임베딩을 식별할 수 있다.
3.2 Semi-supervised learning
Semi-supervised learning (Semi-SL) [15]은 소수의 labeled data 와 대량의 unlabeled data 를 활용하여 모델을 학습하는 것을 목표로 한다. 즉, 인 상황에서 사용된다. 특히 이미지 분류 분야에서 신경망 성능을 향상시키기 위해 다양한 Semi-SL 방법들이 제안되어 왔다 [19-22]. 이러한 방법들은 일반적으로 모델을 사용하여 unlabeled data의 클래스를 예측함으로써 얻어지는 pseudo-label [16]에 의존한다. 이후 모델은 unlabeled data 에 대한 예측 와 pseudo-label 간의 cross-entropy loss 를 최소화함으로써 정제된다. Pseudo-label은 가장 높은 확률을 가진 클래스를 나타내는 one-hot vector 형태의 hard label [16]이거나, 이 hard label을 보정하는 soft label [21] 형태를 취할 수 있다. Pseudo-label은 특정 클래스를 sharpening하여 예측 엔트로피를 최소화한다 [70].
CLIP을 위한 Semi-SL
CLIP에서 pseudo-label을 할당하는 것은 각 이미지에 고유한 caption이 연결되어 있기 때문에 어려움이 따른다. 여기서는 unlabeled data가 labeled data와 동일한 클래스에 속한다는 가정이 성립하지 않는다. 따라서 우리는 CLIP을 위한 새로운 Semi-SL 방법을 제안한다.
4 S-CLIP: Semi-supervised Vision-Language Pre-training
우리는 CLIP의 학습을 확장하여, 이미지-텍스트 쌍 과 함께 unpaired 이미지 를 통합한다. 이를 위해 우리는 S-CLIP을 소개하는데, 이는 contrastive learning과 언어 modality를 고려한 두 가지 새로운 pseudo-labeling 방법을 통합한다. 제안된 pseudo-label과 학습 objective의 개념적 도식은 각각 Figure 2와 Figure 3에 나타나 있다.
 Figure 3: 학습 objective. S-CLIP의 학습 objective에 대한 개념적 도식:
(a)는 **paired 이미지와 텍스트를 사용하는 원래 CLIP loss (Eq. (1))**이다.
(b)와 (c)는 **unpaired 이미지에 적용되는, 우리가 제안하는 caption-level 및 keyword-level pseudo-label loss (각각 Eq. (3) 및 Eq. (4))**이다.
Caption-level pseudo-label은 optimal transport (OT) plan 로부터 얻은 soft label이며,
keyword-level pseudo-label은 후보 키워드 집합 로부터 얻은 sparse soft label이다.
Figure 3: 학습 objective. S-CLIP의 학습 objective에 대한 개념적 도식:
(a)는 **paired 이미지와 텍스트를 사용하는 원래 CLIP loss (Eq. (1))**이다.
(b)와 (c)는 **unpaired 이미지에 적용되는, 우리가 제안하는 caption-level 및 keyword-level pseudo-label loss (각각 Eq. (3) 및 Eq. (4))**이다.
Caption-level pseudo-label은 optimal transport (OT) plan 로부터 얻은 soft label이며,
keyword-level pseudo-label은 후보 키워드 집합 로부터 얻은 sparse soft label이다.
4.1 Caption-level pseudo-label
비록 unlabeled 이미지 의 의미론(semantics)이 어떤 caption 와 정확히 일치하지 않을 수 있지만, 시각적으로 유사한 이미지들은 종종 유사한 의미론을 공유한다. 따라서 unlabeled 이미지 에 대한 caption은 caption들 의 조합으로 표현될 수 있다. 이를 위해 우리는 caption-level pseudo-label을 사용하는데, 이는 caption들에 대한 확률 분포를 나타낸다. 이 pseudo-label은 contrastive learning에서 개의 caption 중 하나를 분류하는 -way classification 문제의 목표(target) 역할을 하며, 이때 batch size는 이다. Figure 2a는 unlabeled 이미지에 대한 caption-level pseudo-label이 어떻게 얻어지는지를 보여준다.
pseudo-label은 unlabeled 이미지와 labeled 이미지 간의 관계로부터 도출되며, 이는 최적 수송(Optimal Transport, OT) [24] 문제로 정식화된다. 우리는 **비용 함수(cost function) **를 정의하는데, 여기서 과 은 각각 unlabeled 이미지와 labeled 이미지의 개수를 나타낸다. 비용은 unlabeled 이미지 와 labeled 이미지 의 정규화된 embedding 간의 음의 코사인 유사도로 주어진다. 즉, 이다. 그런 다음, 우리는 다음의 엔트로피 정규화된 OT [25] 문제를 해결한다:
여기서 는 흐름 제약(flow constraint)을 만족하는 수송 계획(transportation plan)들의 집합을 나타낸다. 소스(sources)로부터의 흐름 합과 싱크(sinks)로의 흐름 합은 각각 벡터 와 와 일치하며, 와 모두 합이 1이 된다. 우리는 이들을 균일 확률(uniform probabilities)로 설정했으며, unlabeled 및 labeled 데이터에 분포 변화(distribution shifts)가 있는 경우에도 실험에서 잘 작동했다. 은 차원 의 모든 원소가 1인 벡터를 나타낸다. **엔트로피 정규화 항 **는 스케일 와 함께 수송 계획을 부드럽게(smooth) 만들며, Sinkhorn-Knopp [25] 알고리즘을 사용하여 효율적인 해를 찾을 수 있게 한다.
수송 계획 를 얻은 후, 우리는 unlabeled 이미지 에 대한 pseudo-label을 해당 계획의 합이 1이 되도록 정규화하여 정의한다. 구체적으로, pseudo-label 의 -번째 요소는 로 계산된다. 이 pseudo-label은 개의 caption에 대한 확률 분포를 유도하는 데 사용되며, 여기서 예측 는 **softmax classifier **에 의해 결정된다. caption-level pseudo-label에 대한 손실 함수는 다음을 최소화하는 것을 목표로 한다:
예측 는 unlabeled 이미지 와 텍스트 embedding 를 연결하는 반면, pseudo-label 는 와 이미지 embedding 를 연결한다. 결과적으로, 제안된 손실 함수는 supervised CLIP [71-73]에서 제안된 바와 같이 이미지와 텍스트 embedding 간의 관계를 정렬한다. 우리 실험에서는 pseudo-label 계산을 위해 텍스트 embedding과 이미지 embedding의 사용을 비교했으며, 이미지 embedding이 새로운 전문 분야(novel specialist domains)에서 더 강건(robust)하기 때문에 텍스트 embedding보다 우수한 성능을 보였다. 우리는 또한 pseudo-embedding [9] 계산도 탐색했지만, pseudo-embedding을 합성하는 것이 pseudo-label을 추론하는 것보다 더 어렵기 때문에 열등한 결과를 얻었다.
OT의 효과
Optimal Transport는 unlabeled 이미지와 labeled 이미지 간의 흐름 균형을 맞춰, 소수의 label에 집중되지 않고 강건한 pseudo-label 할당을 보장한다. vision-language task에서 다양하고 불균형한 caption은 종종 이미지 embedding이 소수의 가장 가까운 caption에 집중하게 하여 embedding의 붕괴(collapse)를 초래한다. 이러한 문제는 분포 변화(distribution shifts)가 있는 준지도 학습(semi-supervised learning)을 사용할 때 더욱 증폭된다 [67]. 우리는 순진한(naive) pseudo-labeling 접근 방식의 해로운 영향을, 특히 분포 변화가 있을 때 경험적으로 검증한다.
**soft-nearest neighbor pseudo-label (Soft-PL) [21]**과 비교할 때, 우리 방법은 Sinkhorn 반복(iterations)을 통해 균형을 달성한다. 구체적으로, 반복 횟수가 0일 때 Soft-PL로 되돌아간다. 우리 실험에서는 10번의 반복을 사용했으며, 반복 횟수를 늘려도 성능에는 미미한 영향만 있었다. 이 과정은 저차원 embedding 공간에서 발생하므로 계산 비용은 무시할 수 있는 수준이다. 우리는 엔트로피 정규화 항의 스케일을 softmax 온도 와 일치하도록 로 설정했다. 이 조정은 비용 함수를 로 스케일링하여 CLIP이 학습한 코사인 유사도 스케일과 정렬시킨다. OT와 Soft-PL 관계에 대한 더 자세한 정보는 Appendix A에 있다.
Vision-language 모델을 위한 OT
여러 연구에서 vision-language 모델을 위해 OT를 활용했지만, 준지도 학습(semi-supervised learning) 이외의 문제에 적용되었다. 이러한 연구들은 Appendix B에서 논의한다.
4.2 Keyword-level pseudo-label
우리는 캡션 내 단어의 의미를 포착하는 데 있어 캡션 수준의 pseudo-label이 가지는 한계를 극복하기 위해 키워드 수준의 pseudo-labeling 접근 방식을 제안한다. 언어의 구성성(compositionality)을 활용하여, 우리는 시각적으로 유사한 이미지들이 전체 캡션이 다르더라도 키워드를 공유할 수 있다고 가정한다. 이를 통해 레이블이 없는 이미지들을 가장 가까운 이웃의 키워드를 사용하여 안내할 수 있다.
중요한 점은 하나의 이미지가 여러 키워드를 가질 수 있으며, 시각적으로 유사한 이미지들은 키워드의 부분 집합만을 공유한다는 것이다. 이는 타겟 레이블은 알 수 없지만, 후보 레이블 집합에 접근할 수 있는 partial label learning (PLL) [26] 문제와 일치한다. 예를 들어, Figure 1a에서 이미지는 가장 가까운 이웃과 "tennis court" 키워드를 공유하지만 "baseball field"는 공유하지 않는다. 결과적으로, 가장 가까운 이웃은 Figure 2b에 나타난 것처럼 키워드 후보 집합을 제공한다.
레이블이 없는 이미지 에 대한 후보 키워드를 식별하기 위해, 우리는 **대응하는 embedding을 가진 사전 정의된 키워드 집합 **을 가정한다. 이러한 키워드는 사용 가능한 경우 클래스 이름에서 얻거나, 캡션에 YAKE [74]와 같은 알고리즘을 적용하여 추출할 수 있다. 레이블이 없는 이미지 가 주어지면, 우리는 이전 섹션의 OT 할당을 사용하여 가장 가까운 레이블이 있는 이미지 를 찾는다. 레이블이 있는 이미지 에 존재하는 키워드의 인덱스를 이라고 하면, 이를 로 나타낸다. 이것이 에 대한 타겟 키워드의 후보 집합을 형성한다. 우리는 단순히 캡션에서 명시적으로 키워드를 사용하지만, 동의어나 관련 개념을 추론하기 위한 추가적인 단계를 취할 수도 있다.
Partial label learning의 맥락에서, 우리는 레이블이 없는 이미지 에 대한 ground-truth 타겟 레이블이 후보 집합 에 속한다고 가정한다. PLL은 단일 타겟 레이블을 지정하는 대신, 후보 레이블 중 최소값을 선택하여 손실을 최소화하는 것을 목표로 한다: . 그러나 단일 최소값에 의존하는 것은 위험할 수 있다. 이전 연구들은 후보에 대해 soft label을 사용하여 이 문제를 해결했다 [75, 76]. 이는 를 최소화하는 것을 포함하며, 여기서 는 후보 집합의 키워드에 대해 양수 값을 가지고 다른 키워드에 대해서는 0인 soft label이다.
유사하게, 우리는 레이블이 없는 이미지 에 대한 pseudo-label 를 의 embedding과 후보 집합 내의 키워드 의 embedding 간의 유사도를 기반으로 정의한다. 구체적으로, pseudo-label 의 -번째 요소는 에 대해 softmax 함수 를 사용하여 계산되며, 그렇지 않은 경우에는 0으로 설정된다. 이 pseudo-label은 개의 키워드에 대한 확률 분포를 안내하는 데 사용되며, 여기서 예측 는 softmax classifier 에 의해 결정된다. 키워드 수준 pseudo-label에 대한 손실 함수는 다음을 최소화하는 것을 목표로 한다:
예측 와 pseudo-label 는 모두 레이블이 없는 이미지와 키워드와 관련이 있다. 그러나 제한된 후보 집합은 PLL을 통해 학습 과정을 효과적으로 안내한다.
학습 목표 (Training objective)
우리는 CLIP loss를 쌍을 이루는 이미지와 텍스트에 적용하고, 제안된 pseudo-label loss를 쌍을 이루지 않는 이미지에 적용한다. pseudo-label loss는 CLIP loss의 이미지 부분 스케일에 맞추기 위해 절반으로 줄인다. 요약하면, **우리의 최종 학습 목표는 **가 된다.
Table 1: 원격 탐사 데이터셋에 대한 zero-shot 분류 결과.
우리는 원본 CLIP, 레이블이 있는 데이터(L)로 fine-tuning된 supervised CLIP, 그리고 레이블이 있는 데이터와 동일한() 또는 다른() 분포에서 샘플링된 레이블이 없는 데이터를 활용하는 semi-supervised 방법들을 비교한다. 괄호 안의 값은 supervised CLIP과의 성능 차이를 나타내며, 녹색으로 강조된 값은 1보다 큰 차이를 의미한다. 굵은 글씨는 동일한 설정 내에서 semi-supervised 방법 중 가장 좋은 결과를 나타낸다. S-CLIP은 레이블이 없는 데이터에 분포 변화가 있더라도 zero-shot 정확도를 일관되게 향상시킨다. 반면, naive pseudo-labeling은 종종 정확도를 저해한다.
| Method | Data | RSICD-CLS | UCM-CLS | WHU-RS19 | RSSCN7 | AID |
|---|---|---|---|---|---|---|
| CLIP (original) | - | 45.3 | 50.5 | 65.5 | 58.9 | 47.8 |
| CLIP (fine-tune) | L | |||||
| Hard-PL [16] | ||||||
| Soft-PL [21] | ||||||
| S-CLIP (ours) | ||||||
| Hard-PL [16] | ||||||
| Soft-PL [21] | ||||||
| S-CLIP (ours) |
5 Experiments
우리는 원격 탐사, 패션, 과학 그림, 만화 등 사용 가능한 이미지-텍스트 쌍이 제한적인 다양한 전문 분야에서 우리 방법의 효과를 입증한다.
Setup.
우리는 자연 이미지로 사전학습된 CLIP 모델 [23]을 사용하며, 이를 **CLIP (original)**이라고 부른다. 하지만 이 모델은 전문 분야에서는 종종 어려움을 겪는다. 따라서 우리는 domain-specific 이미지-텍스트 쌍으로 모델을 fine-tuning하며, 이를 **CLIP (fine-tune)**이라고 명명한다. 우리는 이 supervised 모델을 unpaired 이미지를 사용하는 semi-supervised 방법들과 비교한다.
우리는 GPU당 64의 batch size를 사용하며, 총 4개의 GPU를 활용한다. semi-supervised learning에서 공정한 GPU 메모리 사용을 보장하기 위해, 각 mini-batch에 32개의 이미지-캡션 쌍과 32개의 unpaired 이미지를 사용한다.
모델은 zero-shot classification 및 image-text retrieval task에서 평가되며, **Top-1 classification accuracy (%)와 recall at K (R@K)**를 측정한다. 우리는 세 가지 random seed에 대한 평균과 표준 편차를 보고한다.
명시되지 않은 경우, OpenClip [77]의 학습 방식을 따른다. 추가 실험 세부 사항은 Appendix C에 있다.
5.1 Baselines
우리가 제안하는 S-CLIP은 두 가지 새로운 pseudo-labeling 방법을 포함한다. 따라서 우리는 주로 S-CLIP을 **다른 pseudo-labeling 접근 방식들(semi-supervised classification 기법의 확장)**과 비교한다. 우리의 baseline인 Hard-PL과 Soft-PL은 pseudo-label 할당을 위한 hard (top-1) 및 soft nearest neighbor 접근 방식을 확장한 것이다. 우리는 이 방법들을 Eq. (3)과 유사하게 caption-level pseudo-label로 활용한다. 각 방법의 구체적인 형태는 다음과 같다.
Hard-PL. 주어진 unlabeled 이미지 에 대해, Hard-PL은 코사인 유사도를 기반으로 top-1 nearest labeled 이미지 를 식별한다. 코사인 유사도는 로 계산된다. 이어서 의 pseudo-label은 해당 캡션인 로 결정된다. 이 pseudo-label은 를 예측하기 위한 target으로 사용되며, 손실은 로 계산된다.
Soft-PL. Soft-PL은 top-1 nearest 이미지 하나만 선택하는 대신, labeled 이미지와 unlabeled 이미지 간의 모든 관계를 고려하는 soft nearest neighbor [21] 방식을 통해 Hard-PL의 pseudo-label을 보정한다. unlabeled 이미지 와 labeled 이미지 집합 에 대해, 이러한 관계는 코사인 유사도에 softmax를 적용하여 결정된다. pseudo-label은 으로 정의되며, 여기서 시각적으로 유사한 이미지에 대해 pseudo-label은 1에 가까운 높은 값을 갖는다. 우리는 labeled 이미지와 텍스트 임베딩 간의 유사도를 계산하는 데 사용되는 **CLIP과 동일한 softmax temperature **를 사용한다. 손실은 로 계산된다.
5.2 Remote sensing datasets
우리는 [64]의 설정에 따라 RSICD [27], UCM [32], Sydney [78]의 합집합을 사용하여 RS-ALL이라는 vision-language model을 학습시킨다. semi-supervised learning을 위해, 우리는 이미지-텍스트 쌍의 10%를 labeled data (L)로 샘플링하고, 나머지 90%의 이미지(L=U) 또는 **RESISC45 [79] 데이터셋의 unlabeled 이미지(L≠U)**를 unlabeled data로 사용한다. Appendix D에서는 우리의 방법이 다양한 설정에서 CLIP 대비 지속적인 개선을 제공함을 보여준다. 여기에는 다양한 신경망 아키텍처, 이미지-텍스트 쌍의 다양한 비율, 심지어 RS-ALL의 모든 이미지-텍스트 쌍과 RESISC45의 unlabeled 이미지를 함께 사용하는 시나리오까지 포함된다.
zero-shot classification의 경우, 우리는 RSICD 및 UCM 데이터셋의 분류 버전인 RSCID-CLS 및 UCM-CLS의 validation set을 사용한다. 일반화 능력을 평가하기 위해, 우리는 WHU-RS19 [31], RSSCN7 [80], AID [81]와 같은 unseen 데이터셋에서 모델을 테스트한다. image-text retrieval의 경우, 우리는 RSICD, UCM, Sydney 데이터셋의 validation set을 사용한다.
Zero-shot classification. Table 1은 zero-shot classification 결과를 보여준다. S-CLIP은 모든 supervised CLIP fine-tuning 및 semi-supervised 방법들보다 일관되고 유의미하게 우수한 성능을 보인다. 몇 가지 관찰 사항을 정리할 수 있다. 첫째, CLIP fine-tuning은 original CLIP보다 성능을 향상시키며, 이는 모델을 특정 전문 도메인에 적응시키는 것의 중요성을 강조한다. 둘째, 우리가 제안한 pseudo-labeling 기법은 매우 중요하다. 왜냐하면 naive pseudo-labeling은 종종 정확도를 저해하기 때문이다. 셋째, semi-supervised learning 방법들은 RSSCN7과 같은 unseen 데이터셋에서 성능을 향상시키며, 이는 일반화에 있어 더 많은 unlabeled 이미지를 관찰하는 것의 유용성을 보여준다. 마지막으로, 우리의 방법은 실제 환경에서 흔히 발생하는 시나리오인 외부 unlabeled 이미지 소스를 활용하는 분포 변화(L≠U) 설정에 강건하다. 이와 대조적으로, Soft-PL은 동일 분포(L=U) 설정에서는 성능을 향상시키지만, 분포 변화 시나리오에서는 실패하며, 이는 pseudo-label 할당의 균형을 맞추는 데 있어 optimal transport의 효과를 확인시켜준다.
Image-text retrieval. Table 2는 image-text retrieval 결과를 보여준다. S-CLIP은 supervised baseline이 가장 좋은 성능을 보이는 한 가지 경우를 제외하고, image→text 및 text→image retrieval 모두에서 일관되게 성능을 향상시킨다. 이는 S-CLIP이 retrieval을 위한 미세한 언어 이해에도 도움이 된다는 것을 확인시켜준다. Appendix의 R@1 결과에서 볼 수 있듯이, 이러한 경향은 평가 지표 전반에 걸쳐 일관적이다.
Table 2: 원격 감지 데이터셋에 대한 이미지-텍스트 검색 결과, Table 1과 동일한 설정. 굵은 글씨는 동일한 설정 내에서 semi-supervised 방법 중 가장 좋은 결과를 나타낸다. S-CLIP은 대부분의 경우에서 가장 좋은 성능을 보이지만, Sydney 데이터셋의 text → image 검색에서는 supervised baseline이 가장 좋은 성능을 보인다. Naive pseudo-labeling도 도움이 되지만, 그 이득은 종종 불안정하다.
| Method | Data | Image text R@5 | Text image R@5 | ||||
|---|---|---|---|---|---|---|---|
| RSICD | UCM | Sydney | RSICD | UCM | Sydney | ||
| CLIP (original) | - | 9.4 | 34.3 | 36.2 | 10.1 | 24.8 | 51.7 |
| CLIP (fine-tune) | L | ||||||
| Hard-PL [16] | |||||||
| Soft-PL [21] | |||||||
| S-CLIP (ours) | |||||||
| Hard-PL [16] | |||||||
| Soft-PL [21] | |||||||
| S-CLIP (ours) |
5.3 Fashion datasets
우리는 Fashion200k [28], FashionGen [82], Polyvore Outfits [83] 데이터셋의 합집합을 사용하여 vision-language model을 학습시킨다. 이미지-텍스트 쌍의 10%를 labeled data로, 나머지 90%의 이미지를 unlabeled data로 샘플링한다. 우리는 세 데이터셋의 validation set에 대해 zero-shot 정확도를 평가하며, Fashion200k와 FashionGen의 경우 super-class와 sub-class 정확도를 모두 고려한다. Polyvore의 class 이름은 다른 데이터셋의 super-class와 동일한 수준을 따른다.
Table 3는 zero-shot 분류 결과를 보여준다. S-CLIP은 모든 supervised 및 semi-supervised 방법들을 일관되게 능가한다. 이러한 성능 향상은 super-class 분류에서 더 두드러지지만, sub-class 분류 및 image-text retrieval에서는 덜 명확하다. 이는 현재의 pseudo-labeling 접근 방식이 unlabeled 이미지의 의미가 batch 내의 caption으로 표현될 수 있다고 가정하기 때문이다. 그러나 이러한 가정은 세분화된(fine-grained) 의미에서는 항상 유효하지 않을 수 있다. 특정 fine-grained caption이 batch에 포함되지 않을 수 있기 때문이다. 따라서 우리의 방법은 batch size를 늘리거나 caption embedding 큐 [84, 85]를 통합함으로써 더욱 향상될 수 있다.
Table 3: 패션 데이터셋에 대한 Zero-shot 분류 결과. 괄호 안의 값은 supervised CLIP과의 성능 차이를 나타내며, 녹색으로 강조된 값은 1보다 큰 차이를 의미한다. 굵은 글씨는 최고 결과를 나타낸다. S-CLIP은 모든 supervised 및 semi-supervised 방법들을 일관되게 능가한다.
| Method | Fashion200k | FashionGen | Polyvore | ||
|---|---|---|---|---|---|
| Super-class | Sub-class | Super-class | Sub-class | Class | |
| CLIP (original) | 73.4 | 29.3 | 35.9 | 22.1 | 58.4 |
| CLIP (fine-tune) | |||||
| Hard-PL [16] | |||||
| Soft-PL [21] | |||||
| S-CLIP (ours) |
Table 4: SciCap (과학 그림) 및 Simpsons (만화) 데이터셋에 대한 Image-text retrieval 결과. 우리는 각 데이터셋으로 모델을 학습시키고 validation set에서 평가한다. 굵은 글씨는 최고 결과를 나타낸다. S-CLIP은 모든 supervised 및 semi-supervised 방법들을 일관되게 능가한다.
| Method | SciCap | Simpsons | ||||||
|---|---|---|---|---|---|---|---|---|
| Image text | Text image | Image text | Text image | |||||
| R@1 | R@5 | R@1 | R@5 | R@1 | R@5 | R@1 | R@5 | |
| CLIP (original) | 9.2 | 14.7 | 9.0 | 14.5 | 15.8 | 40.8 | 10.5 | 27.6 |
| CLIP (fine-tune) | ||||||||
| Hard-PL [16] | ||||||||
| Soft-PL [21] | ||||||||
| S-CLIP (ours) |
5.4 More captioning datasets
우리는 두 가지 더 전문적인 도메인, 즉 **과학 그림(science figures)**과 **만화(comics)**에 대해 실험을 수행한다. 이를 위해 SciCap [29] 및 Simpsons [30] 데이터셋을 사용한다. 각 데이터셋으로 모델을 학습시키고, validation set에서 이미지-텍스트 검색(retrieval) 성능을 평가한다. 결과는 Table 4에 제시되어 있으며, 자세한 논의는 다음 단락에서 확인할 수 있다.
SciCap
우리는 이미지-텍스트 쌍의 10%를 labeled data로, 나머지 90%의 이미지를 unlabeled data로 샘플링한다. S-CLIP은 CLIP이 사전학습된 자연 이미지 도메인과 상당한 차이를 보이는 과학 그림 도메인에서도 CLIP보다 성능을 향상시킨다. 이는 S-CLIP이 CLIP의 적용 가능성을 다양한 전문 도메인으로 확장하는 데 실질적인 영향을 미친다는 것을 확인시켜 준다.
Simpsons
Simpsons 데이터셋은 800개의 이미지-텍스트 쌍만 포함하고 있으므로, 우리는 Simpsons Characters [33]라는 다른 데이터셋에서 unlabeled 이미지를 추가한다. S-CLIP은 unlabeled 이미지와 labeled 이미지 간에 분포 변화(distribution shifts)가 존재함에도 불구하고 CLIP의 성능을 크게 향상시킨다. 예를 들어, text image retrieval R@1을 11.8%에서 15.8%로 (+33%) 향상시킨다. 이는 S-CLIP이 사용 가능한 이미지-텍스트 쌍이 제한적인 전문 도메인에서도 실질적인 영향을 미친다는 것을 확인시켜 준다.
5.5 Ablation studies
우리는 S-CLIP의 설계 선택에 대한 ablation study를 수행했다. 그 결과는 Table 5에 보고되어 있으며, 각 설계 선택에 대한 zero-shot 정확도(Table 1의 5개 task 평균)와 image-text retrieval R@1(Table 2의 6개 task 평균)의 평균값을 비교한다. 관찰된 내용은 다음과 같다:
(a) 학습 목표 (Training objective). Caption-level pseudo-label은 image-text retrieval에 더 유익한 반면, keyword-level pseudo-label은 zero-shot classification에 더 효과적이다. 직관적으로, keyword-level pseudo-label은 모델이 특정 단어를 이해하는 데 도움을 주고, caption-level pseudo-label은 세밀한 언어 이해를 돕는다. 이 둘을 결합하면 가장 좋은 결과를 얻을 수 있다.
(b) Sinkhorn 반복 (Sinkhorn iteration). Sinkhorn 반복은 pseudo-label의 균형을 맞춰 Soft-PL(=Iter. 0)의 성능을 크게 향상시킨다. 그러나 10회 반복 후에는 수렴하므로, 우리는 실험에서 이를 기본값으로 사용했다. 반복 횟수를 늘리면 pseudo-label의 분포가 더 균일해진다. 예를 들어, Soft-PL에서 생성된 pseudo-label은 종종 배치 내의 특정 인덱스로 붕괴되는 경향이 있다. Sinkhorn 반복은 이러한 행동을 효과적으로 정규화하여, 예측의 최대 신뢰도를 100%에서 40%로 줄인다. 이러한 정규화는 Soft-PL이 종종 성능을 저해하는 설정에서 더욱 중요하며, 우리의 방법은 일관되게 성능 향상을 제공한다.
Table 5: 설계 선택에 대한 Ablation study. 우리는 zero-shot 정확도(왼쪽)와 image text retrieval(오른쪽)의 평균값을 보고한다. 굵은 글씨는 최고의 결과를 나타낸다. 논의는 Section 5.5를 참조하라.
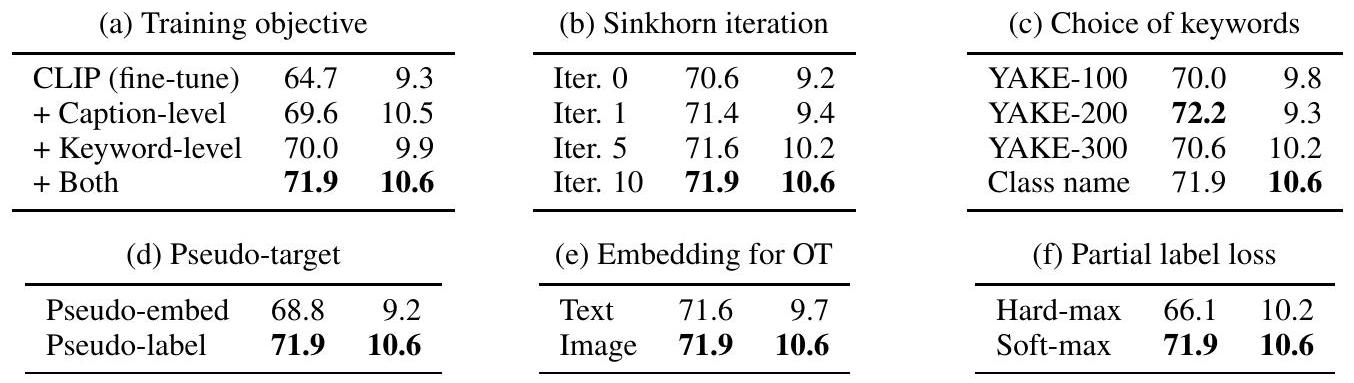
(c) 키워드 선택 (Choice of keywords). 우리는 class name과 YAKE-를 비교했는데, YAKE-는 YAKE [74] 알고리즘을 사용하여 개의 키워드를 추출했음을 의미한다. 두 가지 유형의 키워드 모두 잘 작동하지만, class name이 더 일관된 개선을 제공한다. YAKE는 "building"과 같은 명사뿐만 아니라 "green", "many", "large"와 같은 형용사도 제공하는 반면, class name은 명사로만 구성된다. 이를 통해 YAKE는 객체 인식 외의 다양한 의미를 이해할 수 있으며, keyword-level pseudo-labeling을 모든 도메인에 적용할 수 있게 한다. 이러한 적용 가능성은 class name을 사용할 수 없는 SciCap 및 Simpsons 데이터셋에서도 추가로 확인되었다.
(d) Pseudo-target. unlabeled 이미지 에 대한 pseudo-label 가 주어졌을 때, pseudo-embedding 를 합성할 수 있다. 여기서 는 의 번째 요소를 나타내고, 는 embedding 의 차원이다. 그런 다음, 를 paired 데이터로 간주하고, 실제 쌍 외에 이에 contrastive learning을 적용할 수 있다. 그러나 우리는 pseudo-embedding이 pseudo-labeling보다 덜 효과적이라는 것을 발견했다. 이는 pseudo-embedding을 정확하게 추정하는 것이 실제 embedding에 soft 확률을 할당하는 것보다 더 어렵기 때문이다. 또한, pseudo-embedding은 실제 embedding의 보간(interpolation)에 위치하여 혼란스러운 negative를 유발하고 contrastive learning의 효과를 잠재적으로 해칠 수 있다.
(e) OT를 위한 Embedding (Embedding for OT). 우리는 unlabeled 이미지와 labeled 이미지 또는 labeled 텍스트 간의 관계를 직접 조사하여 pseudo-label을 계산한다. labeled 이미지와의 관계가 pseudo-label 할당에 더 효과적이라는 것이 입증되었다. 특히, 텍스트 embedding을 직접 사용하는 것도 설정에서는 상당히 잘 작동한다. 그러나 설정에서는 종종 완전히 실패한다. 이는 unlabeled 이미지에 대한 해당 caption을 알 수 없기 때문이다. 대조적으로, 시각적 유사성은 이미지를 보지 못했을 때도 강력하게 계산될 수 있다.
(f) 부분 레이블 손실 (Partial label loss). 우리는 PLL의 목표로 에 의해 주어진 soft label을 사용한다. 또한, 후보 세트에서 가장 유사한 키워드, 즉 를 사용하는 hard 버전을 테스트했다. 그러나 이는 성능이 더 나빴으며, 이는 이전 PLL 문헌의 관찰과 일치한다.
우리는 Appendix E에서 추가적인 ablation study를 제공한다. 여기에는 일반 이미지 도메인에서의 결과, 추가적인 pseudo-labeling baseline, pseudo-label의 정성적 예시, 학습 곡선, 정규화된 fine-tuning 접근 방식, 학습 중 미니 배치 선택, 키워드 정보를 사용하는 추가 baseline, 그리고 caption 내 키워드 통계가 포함된다.
6 Conclusion
우리는 S-CLIP을 제안한다. S-CLIP은 CLIP의 semi-supervised 확장으로, unpaired 이미지를 활용하여 이미지-텍스트 쌍이 제한적인 specialist domain에서 학습한다. 우리는 원격 탐사, 패션, 과학 논문 그림, 만화 등 다양한 domain에서 S-CLIP의 우수성을 입증한다. S-CLIP이 CLIP의 적용 가능성을 확장하기를 기대한다. 한계점 및 광범위한 영향은 Appendix F에서 논의한다.
Acknowledgements
본 연구는 한국 정부(MSIT)의 정보통신기획평가원(IITP) 기금 지원을 받아 수행되었습니다 (No.2019-0-00075, Artificial Intelligence Graduate School Program (KAIST); No.2021-0-02068, Artificial Intelligence Innovation Hub; No.2022-0-00959, Few-shot Learning of Casual Inference in Vision and Language for Decision Making).
A Relationship between OT and Soft-PL
Eq. (2)에 기술된 entropic-regularized optimal transport 문제는 Sinkhorn-Knopp [25] 알고리즘을 사용하여 효율적으로 해결할 수 있다. 우리의 경우, **cost function 은 음의 코사인 유사도(negative cosine similarity)**로 주어지며, 이다. Sinkhorn-Knopp 알고리즘은 다음과 같이 진행된다: 먼저, 지수화된 cost matrix 를 계산한다. 여기서 는 entropic regularizer의 스케일을 나타낸다. 그 다음, 알고리즘은 두 벡터 와 를 균일 확률로 초기화한 후 반복적으로 업데이트한다. transportation plan 는 지수화된 cost matrix K와 현재 벡터 및 를 사용하여 추정할 수 있다. 구체적으로, 로 주어지며, 여기서 는 **요소별 곱셈(element-wise multiplication)**을 나타낸다.
초기화 시점(zero)에는 벡터 와 가 균일하므로, transportation plan 는 지수화된 cost matrix K를 정규화하여 얻어진다. 결과적으로, 우리의 caption-level pseudo-label 는 로 주어지며, 이는 softmax temperature 를 제외하면 Soft-PL 와 동일하다. 이러한 관찰은 embedding 간의 관계를 계산하기 위해 로 설정하여 CLIP과 동일한 temperature를 사용하도록 동기를 부여한다. 이러한 관점에서, 우리가 제안하는 OT 접근 방식은 pseudo-label 할당에서 Soft-PL의 견고성(robustness)을 향상시키며, 특히 unlabeled 이미지와 labeled 이미지 간에 분포 변화(distribution shifts)가 있는 경우에 더욱 효과적이다. 우리의 ablation study는 Sinkhorn 반복 횟수를 늘리면 학습 과정이 개선됨을 보여준다.
초기화 후, 벡터 와 는 지수화된 cost matrix K에 맞춰 업데이트되고, flow constraints 와 를 만족하도록 조정된다. 구체적으로, 현재 벡터 와 가 주어졌을 때, 다음 반복의 벡터는 및 로 얻어진다. 이러한 반복 과정은 최적의 해로 수렴한다. 우리의 ablation study는 적은 수의 반복만으로도 충분히 효과적임을 보여주며, 우리는 실험에서 10번의 반복을 사용한다.
B Additional related work
Vision-language model을 위한 Optimal transport
몇몇 선행 연구들은 optimal transport를 vision-language model에 적용해왔다. 그러나 대부분은 이미지와 캡션 간의 transport에 초점을 맞추어 객체와 구문(phrase)을 연결하는 방식이었다 [35, 36, 86-88]. 이는 weakly supervised phrase grounding [89]으로 알려져 있으며, 이미지-텍스트 쌍이 있는 supervised setting을 가정한다. OTTER [90]는 이미지와 텍스트 간의 transport를 계산하는데, 이는 우리의 접근 방식과 유사하다. 하지만 이들 역시 supervised setting을 가정하고 CLIP의 one-hot target을 보정하는 데 집중한다. 우리가 아는 한, 우리의 연구가 semi-supervised CLIP 학습에 optimal transport를 적용한 최초의 시도이다.
Semi-supervised learning을 위한 Optimal transport
일부 선행 연구들은 semi-supervised learning, 특히 이미지 분류 [91, 92]에서 optimal transport를 활용해왔다. 이 연구들은 클래스 레이블의 pseudo-labeling 과정에서 optimal transport의 이점을 보여준다. 그러나 우리는 레이블링된(labeled) 캡션과 레이블링되지 않은(unlabeled) 캡션 간의 내재적인 분포 변화(distribution shift) 때문에 vision-language model에서 OT가 훨씬 더 중요한 역할을 한다고 주장한다. 우리의 실험은 naive pseudo-labeling이 종종 해로운 영향을 미치는 반면, OT는 semi-supervised CLIP 학습을 크게 개선한다는 것을 보여준다.
Partial label learning
Partial label learning (PLL) [26]은 정확한 하나의 레이블 대신 후보 집합(candidate set)을 target으로 사용하여 분류 문제를 완화한다. 이는 집합 내에서 가장 적합한 후보를 최적화하는 것을 포함한다. PRODEN [75]은 후보의 hard assignment를 결정하는 대신, 집합 내 요소들에 대한 soft label을 계산하여 최적화 과정을 부드럽게 한다. PiCO [76]는 contrastive learning을 통합하여 이 접근 방식을 더욱 향상시킨다. 우리의 연구는 PLL의 기술을 새로운 문제, 즉 vision-language model을 위한 키워드 수준의 pseudo-labeling으로 확장한다.
Contrastive learning에서의 Label propagation
Pseudo-labeling (또는 label propagation) 개념은 이미지 전용 contrastive learning에서도 적용된다. 서로 다른 augmentation을 적용한 동일한 이미지를 사용하는 것 외에도 [84, 85], 일부 연구들은 인접한 이미지들을 positive pair로 활용하는 것을 탐구한다 [93-95]. 유사한 개념은 supervised [96] 및 semi-supervised [22, 97] contrastive learning으로 확장될 수 있으며, 여기서는 동일한 클래스 레이블을 공유하는 이미지들이 positive pair로 간주된다.
C Experimental details
C. 1 Dataset details
Remote sensing. 우리는 학습을 위해 RSICD [27], UCM [32], Sydney [78] 데이터셋의 통합본을 사용한다. UCM 및 Sydney 데이터셋의 캡션은 Qu et al. [98]에 의해 주석되었다. Figure 4는 예시 이미지와 캡션을 보여주며, Table 6은 각 데이터셋의 통계를 제시한다. 하나의 이미지에 여러 캡션이 연결될 수 있으므로, 우리는 각 iteration마다 무작위로 하나의 캡션을 선택한다.
 Figure 4: Remote sensing domain의 이미지-텍스트 쌍 예시.
Figure 4: Remote sensing domain의 이미지-텍스트 쌍 예시.
Table 6: Remote sensing domain의 이미지-텍스트 쌍 데이터셋 통계.
| RSICD | UCM | Sydney | |
|---|---|---|---|
| # of pairs | 8,734 | 1,680 | 497 |
우리는 zero-shot classification을 위해 RSCID-CLS [27], UCM-CLS [32], WHU-RS19 [31], RSSCN7 [80], AID [81] 데이터셋의 validation set을 사용한다. RSCID-CLS와 UCM-CLS는 각각 RSCID와 UCM의 classification 버전이다. Table 7은 각 데이터셋의 통계를 제시한다.
Table 7: Remote sensing domain의 classification 데이터셋 통계.
| RSICD-CLS | UCM-CLS | WHU-RS19 | RSSCN7 | AID | |
|---|---|---|---|---|---|
| # of images | 1,094 | 2,100 | 1,005 | 2,800 | 10,000 |
| # of classes | 31 | 21 | 19 | 7 | 30 |
Fashion. 우리는 학습을 위해 Fashion200k [28], FashionGen [82], Polyvore Outfits [83] 데이터셋의 통합본을 사용한다. Figure 5는 예시 이미지와 캡션을 보여주며, Table 8은 각 데이터셋의 통계를 제시한다. 하나의 아이템에 캡션에 해당하는 여러 이미지 뷰가 연결될 수 있으므로, 우리는 각 iteration마다 무작위로 하나의 뷰를 선택한다. 캡션의 경우, FashionGen과 Polyvore에서는 제목과 설명을 연결하여 사용하고, Fashion200k에서는 문장을 사용한다.
 Figure 5: Fashion domain의 이미지-텍스트 쌍 예시.
Figure 5: Fashion domain의 이미지-텍스트 쌍 예시.
Table 8: Fashion domain의 이미지-텍스트 쌍 데이터셋 통계.
| Fashion200k | FashionGen | Polyvore | |
|---|---|---|---|
| # of pairs | 61,753 | 60,147 | 71,967 |
우리는 zero-shot classification을 위해 Fashion200k, FashionGen, Polyvore 데이터셋의 validation set을 사용한다. Table 9는 각 데이터셋의 통계를 제시한다. Fashion200k와 FashionGen의 경우, super-class와 sub-class를 모두 보고한다. Polyvore의 class 이름은 다른 데이터셋의 super-class와 동일한 수준을 따른다. 예를 들어, super-class에는 "dress"와 같은 class 이름이 포함되고, sub-class에는 "casual and day dress"와 같은 class 이름이 포함된다.
Table 9: Fashion domain의 classification 데이터셋 통계.
| Fashion200k | FashionGen | Polyvore | |||
|---|---|---|---|---|---|
| Super-class | Sub-class | Super-class | Sub-class | Class | |
| # of images <br> # of classes | 32,528 | 14,657 | |||
| 121 | 11 |
Scientific figures. 우리는 학습을 위해 SciCap [29] 데이터셋을 사용한다. Figure 6은 예시 이미지와 캡션을 보여주며, Table 10은 각 데이터셋의 통계를 제시한다. 우리는 단순화를 위해 하위 그림(subfigures)이 없는 그림들로 구성된 "SciCap-No-Subfig-Img" subset을 사용한다. Comics. 우리는 Simpsons [30] 데이터셋을 labeled data로, Simpsons Character [33] 데이터셋을 unlabeled data로 사용한다. Figure 6은 예시 이미지와 캡션을 보여주며, Table 10은 각 데이터셋의 통계를 제시한다. 우리는 Simpsons 데이터셋의 90%를 training split으로, 나머지 10%를 validation split으로 사용한다. training split은 720개의 이미지-텍스트 쌍만 포함하므로, Simpsons Characters와 같은 다른 데이터셋의 이미지를 통합하는 것이 필요하다.
 Figure 6: Scientific figure 및 comics domain의 이미지-텍스트 쌍 예시.
Figure 6: Scientific figure 및 comics domain의 이미지-텍스트 쌍 예시.
Table 10: Scientific figure 및 comics domain의 이미지-텍스트 쌍 데이터셋 통계.
| # of pairs | SciCap | Simpsons |
|---|---|---|
| 106,834 | 720 |
C. 2 Implementation details
학습 (Training)
우리는 OpenCLIP [77] 라이브러리를 활용하여 알고리즘을 구현한다. 기본적으로, 우리는 원래의 학습 설정을 따른다. GPU당 64의 배치 크기를 사용하며, 총 4개의 GPU를 활용한다. Learning rate는 로 설정하고, 처음 10단계의 warmup 기간을 포함하는 기본 cosine learning rate scheduling을 적용한다.
모든 모델은 성능이 포화될 때까지 학습시키며, 이는 이미지-텍스트 쌍의 수에 따라 달라질 수 있다. 구체적으로, remote sensing 데이터셋은 25 epoch, fashion 데이터셋은 10 epoch, scientific figures 데이터셋은 5 epoch, comics 데이터셋은 10 epoch 동안 학습한다. 우리는 세 번의 실험을 수행하고 모든 결과에 대해 평균과 표준 편차를 보고한다.
semi-supervised 방법의 경우, supervised CLIP loss와 pseudo-label loss를 추가한다. pseudo-label loss의 스케일은 CLIP loss의 이미지 부분 스케일에 맞추기 위해 절반으로 줄인다. entropic regularizer의 스케일은 CLIP의 softmax temperature와 동일하게 설정하며, 이를 로 표기하고, Sinkhorn iteration 횟수는 10으로 설정한다. 우리의 방법은 아래에서 논의할 키워드 후보 세트 선택을 제외하고는 어떠한 추가적인 하이퍼파라미터도 도입하지 않는다.
키워드 (Keywords)
remote sensing 및 fashion 데이터셋의 경우 사용 가능한 클래스 이름을 사용하고, SciCap 및 Simpsons 데이터셋의 경우 캡션에서 YAKE [74] 알고리즘을 사용하여 키워드를 추출한다.
remote sensing의 경우, RSICD-CLS와 UCM-CLS의 클래스 이름을 결합하여 45개의 키워드를 얻었으며, 이 중 약 30개의 단어가 캡션에 나타났다.
fashion의 경우, Fashion200k와 FashionGen의 superclass 이름을 결합하여 56개의 키워드를 얻었다. 이는 캡션에 정확한 sub-class 이름이 포함되지 않는 경우가 많으므로 sub-class 이름보다 더 효과적이다.
우리의 ablation study 결과, YAKE로 추출된 키워드도 효과적이며, 일부 경우에는 클래스 이름을 능가하는 성능을 보였다. remote sensing의 경우, YAKE 키워드는 "building"과 같은 명사뿐만 아니라 "green", "many", "large"와 같은 형용사도 포함하여 모델이 장면의 세분화된 정보(fine-grained information)를 이해하는 데 도움을 준다. 또한, 클래스 이름을 사용할 수 없는 SciCap 및 Simpsons 데이터셋의 경우 YAKE-100 키워드를 활용했으며, 이 접근 방식은 효과적임이 입증되었다. 따라서, 합리적인 키워드 선택이 우리 방법론에 확실히 도움이 될 것이라고 믿는다.
연산 (Computation)
연산 병목 현상은 주로 loss function 계산보다는 embedding 계산에 있다. 따라서, 모든 방법은 단일 학습 iteration에 유사한 시간을 요구하며, S-CLIP만 키워드 추가 forwarding으로 인해 더 오래 걸린다. 학습 시간은 이미지-텍스트 쌍의 수에 따라 다르며, 몇 분에서 몇 시간까지 소요된다. semi-supervised 방법은 labeled 및 unlabeled 데이터를 동일한 크기로 배치하기 때문에 supervised CLIP보다 두 배의 시간이 소요되며, 이는 동일한 epoch에 대해 두 배 많은 iteration이 필요하기 때문이다.
평가 (Evaluation)
우리는 OpenCLIP에서 제공하는 평가 코드를 사용한다. zero-shot classification의 경우, 기본 템플릿인 "a photo of a [class]"를 사용한다. fashion 데이터셋에는 이 템플릿을 사용하지만, remote sensing의 경우 [64]의 설정을 따라 "an aerial photograph of a [class]" 템플릿을 사용한다.
D Additional remote sensing results
D. 1 Different neural architectures
Table 11은 ResNet [99] 및 ViT [100] 모델을 사용한 zero-shot 분류 결과를 보여준다. S-CLIP은 고려된 모든 시나리오에서 supervised baseline을 크게 향상시킨다. 원본 CLIP과 fine-tuned CLIP 모두에서 더 큰 모델이 전반적으로 더 나은 정확도를 보인다는 점에 주목해야 한다. 여기서 S-CLIP은 더 큰 모델로 확장할 때도 신뢰할 수 있는 성능 향상을 제공한다.
Table 11: 다양한 신경 아키텍처를 사용한 원격 감지 데이터셋의 zero-shot 분류 결과.
괄호 안의 숫자는 supervised CLIP과의 성능 차이를 나타내며, 굵은 글씨는 각 아키텍처 내에서 가장 좋은 결과를 의미한다.
S-CLIP은 일관된 성능 향상을 제공하며, 더 큰 네트워크로 확장 가능하다.
| Model | Method | RSICD-CLS | UCM-CLS | WHU-RS19 | RSSCN7 | AID |
|---|---|---|---|---|---|---|
| ResNet-50 | CLIP (original) | 45.3 | 50.5 | 65.5 | 58.9 | 47.8 |
| CLIP (fine-tune) | ||||||
| S-CLIP (ours) | ||||||
| ViT-B/32 | CLIP (original) | 55.8 | 58.6 | 76.4 | 62.1 | 55.7 |
| CLIP (fine-tune) | ||||||
| S-CLIP (ours) | ||||||
| ViT-B/16 | CLIP (original) | 58.9 | 60.1 | 80.9 | 69.4 | 59.6 |
| CLIP (fine-tune) | ||||||
| S-CLIP (ours) |
D. 2 Different image-text pair ratios
Table 12는 다양한 이미지-텍스트 쌍 비율에 따른 zero-shot 분류 결과를 보여준다. CLIP보다 2배 적은 10%의 쌍만 사용했을 때, S-CLIP은 CLIP이 20%의 쌍을 사용했을 때와 유사한 성능을 달성한다. 더 나아가, CLIP보다 3배 적은 30%의 쌍만 사용했을 때, S-CLIP은 CLIP이 100%의 쌍을 사용했을 때의 성능과 일치하거나, 심지어 keyword-level pseudo-labeling 덕분에 이를 능가하기도 한다.
Table 12: 다양한 이미지-텍스트 쌍 비율을 사용한 원격 감지 데이터셋에서의 zero-shot 분류 결과. 괄호 안의 숫자는 supervised CLIP과의 성능 차이를 나타내며, 굵은 글씨는 각 쌍 비율 내에서 가장 좋은 결과를 의미한다. S-CLIP은 일관된 성능 향상을 보여주며, 필요한 쌍의 수를 줄여준다.
| Method | Ratio | RSICD-CLS | UCM-CLS | WHU-RS19 | RSSCN7 | AID |
|---|---|---|---|---|---|---|
| CLIP (original) | 0% | 45.3 | 50.5 | 65.5 | 58.9 | 47.8 |
| CLIP (fine-tune) S-CLIP (ours) | 10% | |||||
| 20% | ||||||
| 30% | ||||||
| CLIP (fine-tune) | 100% |
D. 3 Using all image-text pairs
본 논문에서는 두 가지 시나리오(L=U 및 L≠U) 를 비교하기 위해 이미지-텍스트 쌍의 10%를 labeled data로 사용하였다. L≠U 시나리오에서 S-CLIP의 효과를 입증한 후, 다음 질문은 모든 paired data와 추가적인 unlabeled data를 사용할 때도 S-CLIP이 유용할 것인가였다. Table 13은 전체 RS-ALL 데이터셋을 labeled data로 사용하고 RESISC45를 unlabeled data로 사용한 결과를 보여준다. S-CLIP은 이처럼 가장 어려운 시나리오에서도 효과적임이 입증되었다.
Table 13: 모든 캡션 이미지와 추가 unlabeled 이미지를 사용하여 원격 감지 데이터셋에 대한 zero-shot 분류 결과. 여기서 unlabeled 데이터는 labeled 데이터와 다른 분포를 가진다. S-CLIP은 이 가장 어려운 시나리오에서도 성능 향상을 제공한다.
| Model | Method | RSICD-CLS | UCM-CLS | WHU-RS19 | RSSCN7 | AID |
|---|---|---|---|---|---|---|
| ResNet-50 | CLIP (fine-tune) | |||||
| S-CLIP (ours) | ||||||
| ViT-B/32 | CLIP (fine-tune) | |||||
| S-CLIP (ours) | ||||||
| ViT-B/16 | CLIP (fine-tune) | |||||
| S-CLIP (ours) |
D. 4 Image-text retrieval R@1
Table 14는 이미지-텍스트 검색의 R@1 결과를 제시하며, 이는 본 논문의 Table 2에 있는 R@5 결과를 보완한다. S-CLIP은 대부분의 경우 semi-supervised 방법들보다 우수한 성능을 보이지만, UCM 데이터셋의 image text 검색에서는 supervised baseline이 가장 좋은 성능을 나타낸다.
Table 14: 원격 감지 데이터셋에 대한 이미지-텍스트 검색 결과. Table 1과 동일한 설정으로 진행되었다. 굵은 글씨는 동일한 설정 내에서 semi-supervised 방법 중 가장 좋은 결과를 나타낸다. Table 2의 관찰과 유사하게, S-CLIP이 대부분의 경우에서 가장 좋은 성능을 보인다.
| Method | Data | Image text R@1 | Text image R@1 | ||||
|---|---|---|---|---|---|---|---|
| RSICD | UCM | Sydney | RSICD | UCM | Sydney | ||
| CLIP (original) | - | 2.1 | 7.1 | 10.3 | 2.2 | 7.1 | 20.7 |
| CLIP (fine-tune) | L | ||||||
| Hard-PL [16] | |||||||
| Soft-PL [21] | |||||||
| S-CLIP (ours) | |||||||
| Hard-PL [16] | |||||||
| Soft-PL [21] | |||||||
| S-CLIP (ours) |
E Additional ablation studies
E. 1 General image domain (COCO) results
Table 15는 COCO [101] 데이터셋에 대한 결과를 보여준다. 우리는 제한된 이미지-캡션 쌍을 사용하여 모델을 fine-tuning하는 것이 성능을 저하시킨다는 것을 관찰했다. 이는 원래 CLIP 모델이 이미 좋은 성능을 보이기 때문이다. 따라서 우리는 원래 CLIP이 상대적으로 약한 성능을 보이는 "스포츠" 카테고리의 하위 집합을 선택했다. 다른 설정과 마찬가지로, 데이터의 10%를 labeled data로, 나머지를 unlabeled data로 사용했다. 학습 설정은 본 논문의 내용과 일관되게 유지했지만, 모델 수렴을 보장하기 위해 10 epoch를 실행했다. S-CLIP 모델은 이러한 일반 이미지 도메인에서도 다른 모델들을 능가하는 성능을 보인다.
Table 15: COCO 스포츠 카테고리에 대한 이미지-텍스트 검색 결과. 이 카테고리에서 원래 CLIP은 상대적으로 약한 성능을 보인다. S-CLIP은 일반 이미지 도메인에서도 좋은 성능을 보인다.
| Method | Image-to-text retrieval | Text-to-image retrieval |
|---|---|---|
| CLIP (original) | 40.30 | 38.17 |
| CLIP (fine-tune) | 46.59 | 47.76 |
| Hard-PL | 48.72 | 47.12 |
| Soft-PL | 48.72 | 47.23 |
| S-CLIP (ours) | 49.79 | 48.40 |
E. 2 Additional pseudo-labeling baselines
Table 16은 state-of-the-art semi-supervised 이미지 분류 방법에서 채택된 pseudo-labeling baseline과의 비교를 제시한다. 구체적으로, 우리는 SemPPL [22]과 RoPAWS [69]의 pseudo-labeling 기법을 사용한다.
- SemPPL은 k-NN 예측의 mode를 사용한다. 우리의 경우, 각 이미지에 대한 caption이 고유하므로, k-NN 샘플에 대해 균일한 확률을 할당하며, 이를 "k-NN" pseudo-labeling이라고 부른다.
- 반면, RoPAWS는 label propagation을 위한 분석적 고정점(fixed-point) 해법을 활용하며, 이를 "LabProp" pseudo-labeling이라고 부른다.
우리는 이러한 baseline을 caption-level pseudo-labeling에 사용하고 OT와 비교한다. 공정한 비교를 위해 keyword-level pseudo-labeling은 사용하지 않았다. OT는 다른 pseudo-labeling 접근 방식들을 능가한다.
Table 16: Table 5의 설정에 따라 SOTA semi-supervised 이미지 분류 방법에서 채택된 pseudo-labeling 접근 방식과의 비교. OT가 가장 좋은 성능을 보인다.
| Method | Zero-shot accuracy | Image-text retrieval |
|---|---|---|
| k-NN (k=5) | 61.1 | 8.8 |
| LabProp | 68.2 | 9.4 |
| OT (ours) |
E. 3 Qualitative examples of pseudo-labels
Figure 7과 Figure 8은 각각 caption-level 및 keyword-level pseudo-label의 정성적 예시를 보여준다. **Optimal transport (OT)**는 시각적으로나 의미적으로 유사한 labeled 이미지를 unlabeled query와 매칭하여 의미 있는 caption-level pseudo-label을 제공한다. 또한, 가장 가까운 labeled 이미지들은 겹치는 키워드를 공유하여 의미 있는 keyword-level pseudo-label을 제공한다.
 Figure 7: caption-level pseudo-label의 정성적 예시. **Optimal transport (OT)**는 숲, 항구, 고층 빌딩 등 시각적으로나 의미적으로 유사한 이미지를 식별할 수 있다. 그 결과, caption-level pseudo-label은 unlabeled 이미지에 대해 정확한 의미론적 정보를 제공한다.
Figure 7: caption-level pseudo-label의 정성적 예시. **Optimal transport (OT)**는 숲, 항구, 고층 빌딩 등 시각적으로나 의미적으로 유사한 이미지를 식별할 수 있다. 그 결과, caption-level pseudo-label은 unlabeled 이미지에 대해 정확한 의미론적 정보를 제공한다.
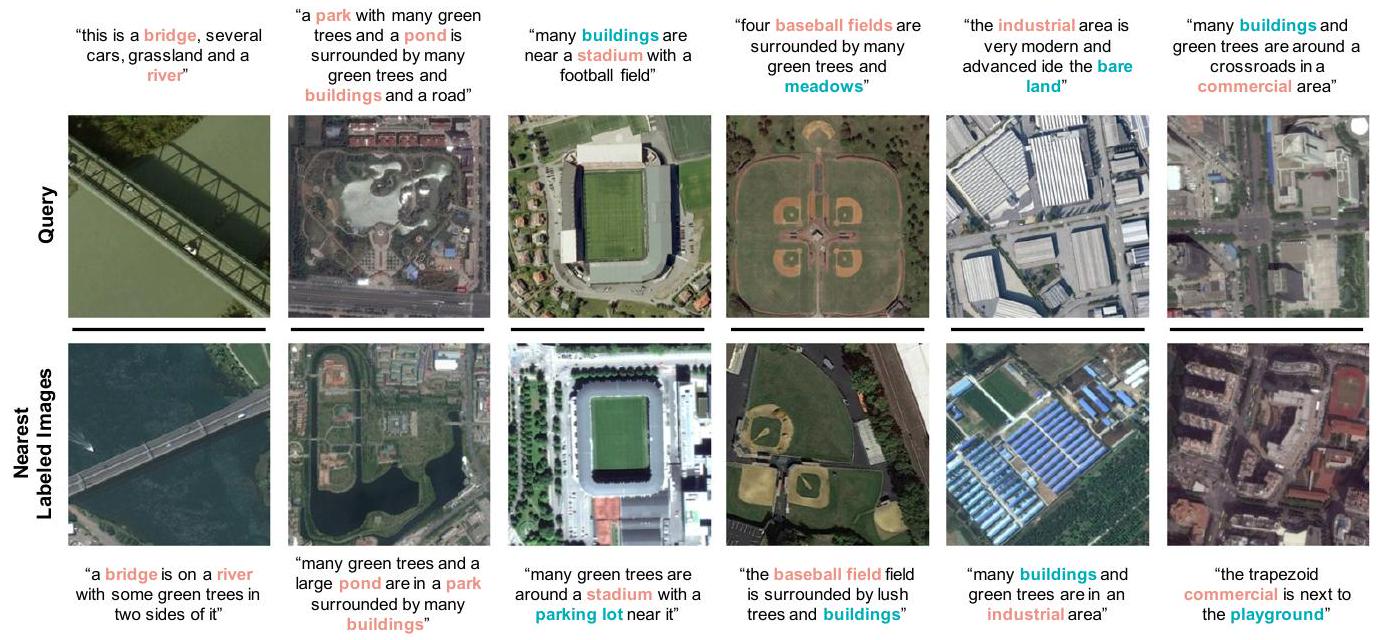
Figure 8: keyword-level pseudo-label의 정성적 예시. OT에 의해 발견된 query에 가장 가까운 이미지들은 종종 caption에서 키워드를 공유한다 (1-2열). 이미지가 모든 키워드를 공유하지 않는 경우에도, 일부 겹치는 키워드를 가지고 있다 (3-6열).
E. 4 Training curves
Figure 9는 학습 중 loss 및 평가 지표의 변화 곡선을 보여준다. RSICD-CLS에서의 zero-shot 분류 정확도와 RS-ALL에서의 이미지-텍스트 검색(image text retrieval) 성능이 보고되었다. 다른 데이터셋에서도 유사한 경향을 보인다. Supervised CLIP은 CLIP validation loss에서 나타나듯이 과적합(overfitting) 경향이 있지만, 이는 Hard-PL과 Soft-PL에 의해 정규화된다. 우리가 제안한 S-CLIP은 가장 큰 이점을 제공하며, 우수한 분류 및 검색 성능을 보여준다.
 Figure 9: 학습 중 loss 및 평가 지표의 변화. S-CLIP은 CLIP validation loss에서 나타나듯이 과적합을 정규화한다. 그 결과, 최고의 분류 및 검색 성능을 달성한다.
Figure 9: 학습 중 loss 및 평가 지표의 변화. S-CLIP은 CLIP validation loss에서 나타나듯이 과적합을 정규화한다. 그 결과, 최고의 분류 및 검색 성능을 달성한다.
E. 5 Locked image or text tuning
Table 17은 LiT [41]에서 제안한 대로 이미지 또는 텍스트 인코더 중 하나를 고정(freezing weights)한 후 fine-tuning한 결과를 보여준다. 우리의 방법에서는 어떤 인코더를 고정하더라도 성능 저하가 발생한다. 이는 전문 분야(specialist domain)의 이미지 및 텍스트 데이터가 모두 모델에게는 새로운 정보이므로, 모델이 이 새로운 정보를 학습해야 하기 때문이다. 반면, 기존 CLIP 모델에서는 텍스트 인코더를 고정해도 고정하지 않은 경우와 유사한 결과를 보인다. 이는 기존 CLIP이 overfitting으로 인해 텍스트 정보를 불충분하게 학습했기 때문이다. 이러한 결과는 S-CLIP을 사용한 pseudo-labeling이 모델의 언어 이해 능력을 향상시킨다는 추가적인 증거를 제공한다.
Table 17: 고정된 이미지 또는 텍스트 인코더에 대한 ablation study.
우리는 **zero-shot 정확도(왼쪽)**와 **이미지 텍스트 검색(오른쪽)**의 평균값을 보고한다.
이미지 또는 텍스트 인코더 중 하나를 고정하는 것은 성능을 저하시키는데, 이는 모델이 전문 분야로부터 새로운 정보를 학습하는 것을 방해하기 때문이다.
| Locked image | Locked text | No lock | ||||||
|---|---|---|---|---|---|---|---|---|
| CLIP (fine-tune) | 48.7 | 8.6 | 64.8 | 9.4 | 64.7 | |||
| S-CLIP (ours) | 63.1 | 8.7 | 67.1 | 10.2 |
E. 6 Selection of mini-batches during training
Table 18은 S-CLIP에 다양한 batch 선택 전략을 적용했을 때의 효과를 보여준다. 원래 batch size인 대신 더 작은 batch size인 를 사용했을 때 성능이 크게 감소했다. 하지만 유사한 이미지를 함께 모아 batch를 구성하는 것이 이러한 성능 하락을 완화하는 데 도움이 되었다. 우리는 시각적 유사도를 기준으로 인덱스를 정렬한 후, 이를 바탕으로 batch를 구성하고 셔플 없이 사용하는 방식으로 과정을 단순화했다. 이러한 "sorted batch" 방식은 상당한 성능 향상을 가져왔다. 향후에는 더 효과적인 active batch sampling 전략을 탐구하는 것이 흥미로운 연구 방향이 될 것이다.
Table 18: mini-batch sampling 전략에 대한 ablation study (Table 5의 설정에 따름)
더 크고 정렬된 batch를 사용하면 더 유익한 pseudo-label을 제공하여 성능이 향상된다.
| Batch size | Zero-shot accuracy | Image-text retrieval |
|---|---|---|
| 64 (random batch) | 65.8 | 8.3 |
| 64 (sorted batch) | 67.3 | 8.9 |
| 256 (random batch) |
E. 7 Baselines using keyword information
Table 19는 키워드 정보를 활용한 baseline과의 비교 결과를 보여준다. 구체적으로, 우리는 두 가지 loss를 통합하였다: (a) multi-label classification을 사용한 labeled 데이터에 대한 키워드 loss, (b) 우리의 pseudo-labeling 접근 방식(가장 가까운 이미지는 OT에 의해 주어짐)을 사용한 unlabeled 데이터에 대한 키워드 loss. 두 loss의 영향을 평가하기 위해, 우리는 **CLIP-FT, CLIP-FT+(a), CLIP-FT+(a)+(b)**를 비교하였다. ablation study를 위해 caption-level pseudo-labeling은 적용하지 않았다. (a)와 (b) 모두 전반적인 성능에 기여하며, 이는 우리가 제안한 pseudo-labeling loss가 키워드 정보뿐만 아니라 unlabeled 데이터로부터 정보를 활용하는 것에도 의존함을 확인시켜준다.
Table 19: 키워드 정보를 활용한 baseline과의 비교 결과 (Table 5의 설정에 따름). 키워드 정보와 semi-supervised learning 모두 최종 성능에 기여한다.
| Method | Zero-shot accuracy | Image-text retrieval |
|---|---|---|
| CLIP-FT | 64.7 | 9.3 |
| + keyword info. | 67.3 | 9.7 |
| + semi-supervised |
E. 8 Keyword statistics in captions
우리는 캡션이 있는 데이터셋을 사용하여 모델을 학습했으며, 클래스 이름은 데이터셋의 분류 counterpart에서 파생되었다. 결과적으로, 캡션에는 종종 여러 클래스 이름이 포함된다. 예를 들어, RSICD 데이터셋 캡션의 45.8%는 두 개 이상의 클래스 이름을 포함한다. 나머지 50%의 캡션은 단일 클래스 이름만 가지며, 이는 우리의 keyword-level loss가 분류 loss로 축소되는 결과를 낳는다. 클래스 이름을 사용할 수 없는 시나리오를 처리하는 방법을 개발했다는 점은 주목할 만하다. YAKE-200 키워드를 활용하여, 우리는 캡션의 94.8%가 두 개 이상의 키워드를 포함한다는 것을 발견했으며, 이는 partial label learning의 필요성을 확인시켜준다.
F Limitations and broader impacts
한계점
우리의 pseudo-labeling 접근 방식은 zero-shot 분류에는 효과적이지만, 세밀한 언어 이해를 요구하는 이미지-텍스트 검색(retrieval)에는 덜 효과적이다. 이는 현재의 pseudo-labeling 접근 방식이 batch 내의 caption들이 unlabeled 이미지의 의미를 포착할 수 있다고 가정하기 때문인데, 이러한 가정은 세밀한(fine-grained) 맥락에서는 항상 유효하지 않을 수 있다. 이 문제를 해결하기 위해 batch size를 늘리거나 [84] caption embedding의 큐(queue)를 통합하는 방법을 고려할 수 있다 [85].
또한, 현재의 caption-level pseudo-labeling을 위한 OT(Optimal Transport) 공식화는 균일한 sink 및 source 제약 조건을 가정한다. 그러나 이러한 가정은 분포 변화(distribution shifts)가 있는 경우 개선될 수 있다. 예를 들어, robust semi-supervised learning [68, 69]의 기술을 활용하여 in-domain-ness를 추정하고, 이 추정치를 기반으로 pseudo-labeling을 정규화할 수 있다.
마지막으로, keyword-level pseudo-labeling은 더욱 향상될 수 있다. 현재 방법은 caption에 키워드가 정확히 포함되어야만 후보군을 형성할 수 있도록 한다. 추가적인 추론 단계를 통합하여 동의어나 관련 개념을 포함하도록 이 기준을 완화할 수 있다. 또한, caption에서 추출된 키워드는 그 수준(level)이 다양할 수 있다. 단어 계층(word hierarchy)을 통합하여 다양한 수준의 키워드를 고려하는 것은 흥미로운 미래 연구 방향이 될 것이다.
광범위한 영향 (Broader impacts)
본 논문은 CLIP의 적용 가능성을 전문 분야로 확장하는 것을 목표로 한다. 그러나 이러한 광범위한 적용 범위는 유해한 콘텐츠를 포함하는 도메인에서 모델을 사용할 때 문제를 야기할 수 있다. 이러한 문제는 모델 자체보다는 데이터 자체에서 발생한다. 따라서 이러한 우려를 효과적으로 해결하기 위해서는 적절한 데이터 정규화(data regularization)가 필수적이다.