SA-DETR: Span Aware Detection Transformer를 이용한 Moment Retrieval
본 논문은 주어진 텍스트와 관련된 비디오 세그먼트를 찾는 Moment Retrieval 문제를 해결하기 위해 Span Aware DEtection TRansformer (SA-DETR)를 제안합니다. 기존 DETR 기반 방법들이 Query Initialization에서 비디오-텍스트 인스턴스 관련 정보를 간과하고 Query Refinement에서 span anchor의 역할을 충분히 활용하지 못하는 문제를 지적합니다. SA-DETR은 인스턴스에 관련된 span anchor의 중요성을 활용하여, 학습 가능한 파라미터 대신 비디오-텍스트 쌍을 기반으로 span anchor를 생성하고 GT 레이블로 감독합니다. 또한, denoise learning을 적용하여 모델의 span 인지 능력을 향상시킵니다. 논문 제목: SA-DETR:Span Aware Detection Transformer for Moment Retrieval
논문 요약: SA-DETR: Span Aware Detection Transformer for Moment Retrieval
- 논문 링크: https://aclanthology.org/2025.coling-main.510/
- 저자: Tianheng Xiong 외 (Huazhong University of Science and Technology, Ping An Property & Casualty Insurance company of China, Ltd.)
- 발표 시기: 2025년, Proceedings of the 31st International Conference on Computational Linguistics
- 주요 키워드: Moment Retrieval, DETR, Video Understanding, Multimodal Learning, Denoise Learning
1. 연구 배경 및 문제 정의
- 문제 정의:
주어진 텍스트 설명과 관련된 특정 비디오 세그먼트(Moment)를 정확하게 찾는 Moment Retrieval 문제. 최근 Object Detection에서 유래한 DETR 기반 방법들이 효과적인 해결책으로 부상했으나, Query Initialization 및 Query Refinement 과정에서 한계를 보인다. - 기존 접근 방식:
Moment Retrieval은 크게 Proposal-based와 Proposal-free 방법으로 나뉜다. Proposal-based는 높은 정밀도를 제공하지만 중복 계산이 많고, Proposal-free는 효율적이지만 경계 인식(boundary perception)이 부족하다. DETR 기반 방법들은 이 둘의 균형을 맞추며 효과적인 해결책으로 부상했으나, 다음과 같은 한계를 가진다:- Query Initialization 시 인스턴스 관련 정보 간과: 기존 DETR 기반 방법들은 span anchor를 학습 가능한 파라미터로 초기화하여 비디오-텍스트 인스턴스 관련 정보를 충분히 활용하지 못한다.
- Query Refinement 시 span anchor의 안내 역할 미흡: span anchor를 단순히 positional encoding으로만 활용하여, Moment Retrieval에서 span anchor와 비디오 클립 feature 간의 강력한 대응 관계를 간과한다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- Moment Retrieval에서 인스턴스 관련 span anchor의 중요한 역할을 강조하는 새로운 SA-DETR (Span Aware DEtection TRansformer) 제안.
- 다양한 단계와 granularity에서의 feature alignment 영향을 탐구하고, denoise learning을 통해 모델의 span awareness를 향상.
- QVHighlights, Charades-STA, TACoS 데이터셋에서 제안 방법의 효과 입증.
- 제안 방법:
SA-DETR은 Moment Retrieval에서 span anchor의 중요한 역할을 강조하며, 인스턴스 관련 Query Initialization과 span aware Query Refinement에 중점을 둔다.- Multi Modal Align Encoder: 모달 융합 전후에 비디오-텍스트 및 클립-텍스트 수준에서 feature를 정렬하여 거친 수준에서 미세한 수준으로 비디오와 텍스트 간의 관계를 이해하도록 돕는다. 또한, Moment Retrieval 및 Highlight Detection task의 다양한 관점에서 융합된 시각 feature를 강화한다.
- Dual Path Query Initializer: 기존 학습 가능한 파라미터 대신 비디오-텍스트 쌍을 기반으로 span anchor를 생성하고 GT(Ground Truth) label로 지도 학습한다. 또한, denoise learning을 통합하여 노이즈가 있는 Query 그룹을 통해 모델의 span 인지 능력을 향상시킨다.
- Span Aware Refine Decoder: span anchor의 안내를 받아 content embedding과 융합 feature 간의 의미적 불일치를 완화한다. 특히, span anchor를 사용하여 cross-attention layer에서 Gaussian mask를 생성하여 이들 간의 상호작용을 직접적으로 조절한다.
3. 실험 결과
- 데이터셋:
QVHighlights, Charades-STA, TACoS 데이터셋을 사용하여 Moment Retrieval 및 Highlight Detection 성능을 평가했다. 비디오 feature는 SlowFast+CLIP 또는 VGG를, 텍스트 feature는 CLIP 또는 GloVe를 사용했다. - 주요 결과:
- QVHighlights: Moment Retrieval에서 거의 모든 지표에서 기존 DETR 기반 방법들을 능가하며, 특히 mAP Avg.에서 47.40으로 최고 성능을 달성했다. Highlight Detection에서도 경쟁력 있는 결과를 보였다.
- Charades-STA 및 TACoS: 두 데이터셋 모두에서 기존의 모든 방법들을 상당한 차이로 능가하는 Moment Retrieval 성능을 보였다. Charades-STA R1@0.7에서 41.51, TACoS mIOU에서 40.03을 기록했다.
- Ablation Studies: Multi-stage feature alignment, instance-related Query initialization, span aware Decoder, denoise learning 등 제안된 모든 구성 요소가 모델 성능 향상에 긍정적인 영향을 미침을 입증했다. 특히, denoise learning은 모델의 수렴 속도와 품질을 크게 향상시켰다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 기존 DETR 기반 모델의 한계점(Query 초기화 및 정제)을 명확히 지적하고, 이를 해결하기 위한 'span aware'라는 새로운 관점을 제시한 점이 인상 깊다.
- 비디오-텍스트 쌍에서 직접 span anchor를 생성하고 GT로 지도 학습하는 방식은 기존의 학습 가능한 파라미터 방식보다 훨씬 직관적이고 효과적이다.
- Denoise learning을 통해 모델의 span 인지 능력을 향상시키고 수렴 속도와 품질을 개선한 점이 뛰어나다.
- 다양한 데이터셋에서 일관되게 SOTA 또는 경쟁력 있는 성능을 달성하여 제안 방법의 견고함을 입증했다.
- 단점/한계:
- Hungarian matching의 안정성: 초기화된 span과 정제된 span 모두에 대해 Hungarian matching을 사용하는데, span anchor의 다른 레이어와 GT 레이블 간의 매칭 안정성이 고려되지 않아 성능 저하로 이어질 수 있다.
- 다중 task 동시 최적화: Modal Fusion 및 Align, Highlight Detection, Moment Retrieval을 통합 프레임워크 내에서 해결하지만, 각 task의 강조점이나 최적화 순서를 고려하지 않고 단순히 동시에 최적화하여 잠재적 성능 한계가 있을 수 있다.
- 제한된 모달리티: 비디오 및 텍스트 모달리티에만 초점을 맞추었으며, 오디오와 같은 다른 모달리티를 통합하기 위한 일반적인 멀티모달 융합 구조는 설계되지 않았다.
- 응용 가능성:
- 비디오 콘텐츠 검색 및 요약: 특정 이벤트나 장면을 빠르게 찾아내어 비디오 검색 엔진, 뉴스 요약, 교육 콘텐츠 제작 등에 활용될 수 있다.
- 스마트 감시 시스템: 특정 행동이나 사건 발생 시 해당 비디오 구간을 자동으로 식별하여 알림을 제공하는 데 응용될 수 있다.
- 개인 미디어 관리: 방대한 개인 비디오 컬렉션에서 특정 순간을 텍스트 쿼리로 쉽게 찾아볼 수 있도록 돕는다.
Xiong, Tianheng, et al. "SA-DETR: Span Aware Detection Transformer for Moment Retrieval." Proceedings of the 31st International Conference on Computational Linguistics. 2025.
SA-DETR:Span Aware Detection Transformer for Moment Retrieval
Tianheng Xiong , Wei Wei , Kaihe , Dangyang Chen <br> Cognitive Computing and Intelligent Information Processing (CCIIP) Laboratory, School of Computer Science and Technology, Huazhong University of Science and Technology<br> Joint Laboratory of HUST and Pingan Property & Casualty Research (HPL),<br> Ping An Property & Casualty Insurance company of China, Ltd., xiongtianheng52@gmail.com, weiw@hust.edu.cn<br>xukaihenupt@gmail.com, chendangyang273@pingan.com.cn
Abstract
Moment Retrieval은 주어진 텍스트와 관련된 특정 비디오 세그먼트를 찾는 것을 목표로 한다. 최근 Object Detection에서 유래한 DETR 기반 방법들이 Moment Retrieval의 효과적인 해결책으로 부상했다. 이러한 접근 방식들은 멀티모달 feature fusion과 span anchor 및 content embedding으로 구성된 Query를 정제하는 데 중점을 둔다.
하지만 이러한 성공에도 불구하고, 기존 방법들은 Query Initialization 시 비디오-텍스트 인스턴스 관련 정보와 Query Refinement 시 span anchor의 중요한 안내 역할을 간과하는 경우가 많아 부정확한 예측으로 이어진다.
이를 해결하기 위해 우리는 **인스턴스 관련 span anchor의 중요성을 활용하는 새로운 Span Aware DEtection TRansformer (SA-DETR)**를 제안한다. 인스턴스 관련 정보를 완전히 활용하기 위해, 우리는 기존 DETR 기반 방법에서 흔히 사용되는 학습 가능한 파라미터 대신 비디오-텍스트 쌍을 기반으로 span anchor를 생성하고, 이를 GT(Ground Truth) label로 지도 학습한다.
span anchor와 비디오 클립 간의 대응 관계를 효과적으로 활용하기 위해, 우리는 텍스트 feature의 안내를 받아 content embedding을 강화하고, Gaussian mask를 생성하여 content embedding과 fusion feature 간의 상호작용을 조절한다. 또한, 우리는 다양한 단계와 granularity에 걸친 feature alignment를 탐색하고, denoise learning을 적용하여 모델의 span awareness를 향상시킨다.
QVHighlights, Charades-STA, TACoS 데이터셋에 대한 광범위한 실험은 우리 접근 방식의 효과를 입증한다.
1 Introduce
인터넷의 발전과 함께 비디오는 주요 미디어 형태로 부상했다. 비디오에서 가치 있는 콘텐츠를 추출해야 하는 절박한 필요성은 Video Action Recognition(Xu et al., 2020 Zhang et al., 2022a), Video Retrieval(Miech et al., 2019; Xue et al., 2022), Video Question Answering(Yu et al., 2019; Yang et al., 2021)을 포함한 비디오 이해 및 검색 task의 발전을 이끌었다. 이러한 방법들은 비디오 검색 및 이해를 향상시키지만, 특정 설명에 기반하여 관련 비디오 세그먼트를 찾는 근본적인 task는 여전히 도전 과제로 남아있다. 이를 위해 Moment Retrieval(Gao et al., 2017; Anne Hendricks et al., 2017) task가 최근 몇 년간 점진적으로 발전해왔다.
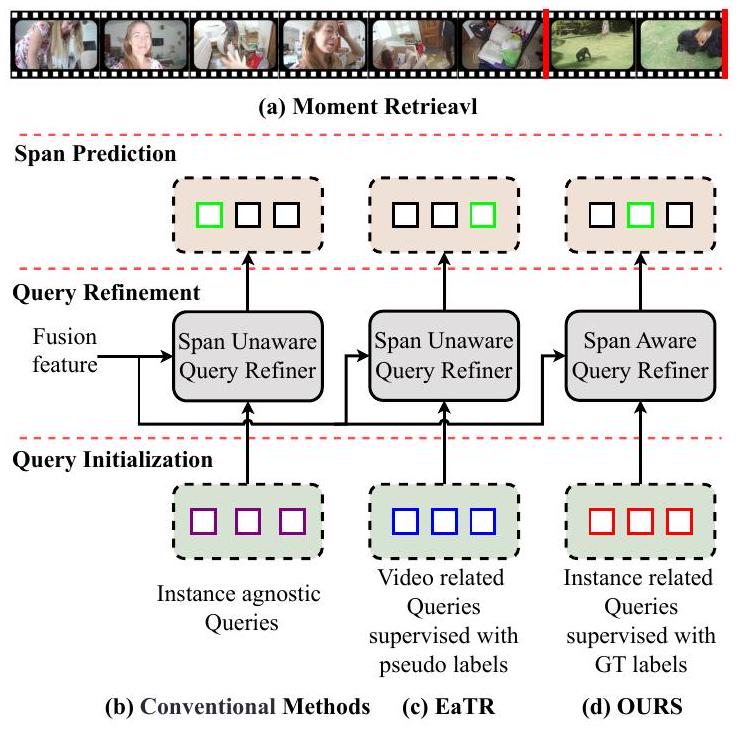
Figure 1: (a) Moment Retrieval. (b)(c)(d) 다양한 방법들 간의 Query Initialization 및 Query Refinement 차이.
Figure 1(a)에 나타난 바와 같이, Moment Retrieval의 목표는 텍스트 설명에 기반하여 관련 비디오 세그먼트를 식별하는 것이다. Moment Retrieval의 핵심은 서로 다른 modality 간의 견고한 정렬(alignment) 및 융합(fusion)을 달성하고, 융합된 feature를 활용하여 세그먼트 경계를 정확하게 찾는 것에 있다. 기존 연구들은 proposal-based methods(Gao et al., 2017; Zhang et al., 2020b; Qu et al., 2020)와 proposal-free methods(Yuan et al., 2019; Zhang et al., 2020a; Liu et al., 2021)로 나눌 수 있다. 전자는 일반적으로 신중하게 설계된 다수의 proposal을 랭킹하여 localization 결과를 얻는데, 이는 높은 정밀도를 제공하지만 중복 계산을 유발한다. 반면 후자는 융합 feature를 통해 직접 moment를 예측하여 높은 효율성을 달성하지만 경계 인식(boundary perception)이 부족하다. Detection Transformer(DETR)(Carion et al., 2020)의 등장은 정밀도와 효율성 사이의 균형을 맞추었다. DETR의 Query는 proposal처럼 작동하지만 복잡성이 적고, Hungarian matching이 부담스러운 Non-Maximum Suppression(NMS) 후처리를 대체한다. 결과적으로 DETR은 Moment Retrieval에 빠르게 채택되었고, 다양한 DETR-based methods에 영감을 주었다.
DETR-based methods에서 Query는 일반적으로 span anchor와 content embedding으로 구성된다. 전자는 **위치 안내(positional guidance)**를 제공하고, 후자는 **의미 정보(semantic information)**를 전달한다. Query Initialization에서 기존 방법들(Figure 1 b)은 span anchor를 학습 가능한 파라미터로 초기화함으로써 인스턴스 관련 정보(instance related information)를 간과한다. 단일 이미지 내에서 다양한 객체 크기를 매칭하기 위해 수많은 anchor box를 사용하는 Object Detection과 달리, Moment Retrieval에서는 span anchor가 비디오-텍스트 쌍과 밀접하게 연결되어 있다. 이러한 맥락에서 학습 가능한 파라미터는 충분한 사전 지식(prior knowledge)을 제공하지 못한다. EaTR (Jang et al., 2023) (Figure 1 c)은 slot attention을 사용하여 비디오 내 이벤트를 인식함으로써 초기화 문제를 해결한다. 이들은 감지된 이벤트를 기반으로 span anchor를 생성하고, Temporal Self-similarity Matrix(TSM)를 사용하여 supervision을 위한 pseudo label을 구성한다. 그러나 이들은 비디오 내에 여러 이벤트가 있다고 가정하며, TSM에 의해 생성된 pseudo label은 정확하지 않다. Query Refinement에서 기존 방법들은 span anchor의 안내 역할(guiding role)을 충분히 활용하지 못한다. 이들은 주로 span anchor를 refiner를 안내하는 positional encoding으로만 활용하며, Moment Retrieval에서 span anchor와 비디오 클립 feature 간의 강력한 대응 관계를 간과한다.
본 논문에서는 Moment Retrieval에서 span anchor의 중요한 역할을 강조하는 **Span Aware DEtection TRansformer(SA-DETR)**를 제안한다. 우리의 방법은 인스턴스 관련 Query Initialization과 span aware Query Refinement에 중점을 둔다. Multi Modal Align Encoder에서는 다중 융합 단계(multi fusion stages)에서 시각 및 텍스트 feature를 다른 granularity로 정렬한다. Dual Path Query Initializer에서는 직접 Query 그룹의 span anchor를 인스턴스 관련 융합 token으로 초기화하고 GT label로 supervision한다. 또한, denoise learning을 통합하여 noise Query 그룹에서 span anchor를 생성함으로써 부정확한 초기화 span을 시뮬레이션하고 추가적인 supervision 정보를 제공한다. Span Aware Refine Decoder에서는 span 기반 enhance block을 도입하여 content embedding과 융합 feature 간의 의미적 불일치(semantic mismatch)를 완화한다. 또한, span anchor는 cross attention layer에서 직접적으로 이들 간의 상호작용을 조절하기 위해 Gaussian mask를 생성하는 데 사용된다.
우리는 SA-DETR을 여러 Moment Retrieval 벤치마크에서 검증했으며, 모든 기존 방법을 능가하고 경쟁력 있는 결과를 달성했다. 요약하면, 우리의 기여는 다음과 같다:
- 우리는 Moment Retrieval에서 인스턴스 관련 span anchor의 중요한 역할을 강조하는 새로운 SA-DETR을 제안한다.
- 우리는 다른 단계와 granularity에서의 feature alignment의 영향을 탐구하고, denoise learning을 통해 모델의 span awareness를 향상시킨다.
- QVHighlights(Lei et al., 2021), Charades-STA(Gao et al., 2017), TACoS(Regneri et al., 2013)에 대한 실험은 우리 방법의 효과를 입증했다.
2 Related Work
2.1 Moment Retrieval with DETR
**Detection Transformer (DETR)**는 원래 Object Detection을 위해 제안되었으며, 수동으로 설계된 anchor box와 복잡한 NMS 후처리 과정이 필요 없는 간단한 Encoder-Decoder 아키텍처를 특징으로 한다. Moment Retrieval과의 높은 호환성 덕분에, Moment-DETR (Lei et al., 2021)는 Moment Retrieval과 Highlight Detection을 동시에 해결하기 위해 처음으로 DETR을 도입했다.
이후, 일련의 DETR 기반 Moment Retrieval 방법론들이 개발되었다. 그중:
- BMDETR (Jung et al., 2023)은 비디오에서 배경 인식 및 시간적 민감도를 향상시켰다.
- QDDERT (Moon et al., 2023b)는 Moment Retrieval 및 Highlight Detection task에서 텍스트 쿼리의 중요한 역할을 탐구했다.
- TR-DETR (Sun et al., 2024) 및 UVCOM (Xiao et al., 2024)은 Moment Retrieval과 Highlight Detection task 간의 차이점과 관계를 논의했다.
- EaTR (Jang et al., 2023)은 비디오에서 발생하는 이벤트에 집중했다.
- CG-DETR (Moon et al., 2023a)은 상관관계를 통해 멀티모달 상호작용을 유도하려고 시도했다.
- BAM-DETR (Lee and Byun, 2023)은 span anchor의 다양한 표현을 탐구했다.
우리의 방법은 DETR 기반 아키텍처를 채택하지만, 위 방법들과 달리 Moment Retrieval에서 instance 관련 Query Initialization과 span aware Query Refinement에 중점을 둔다.
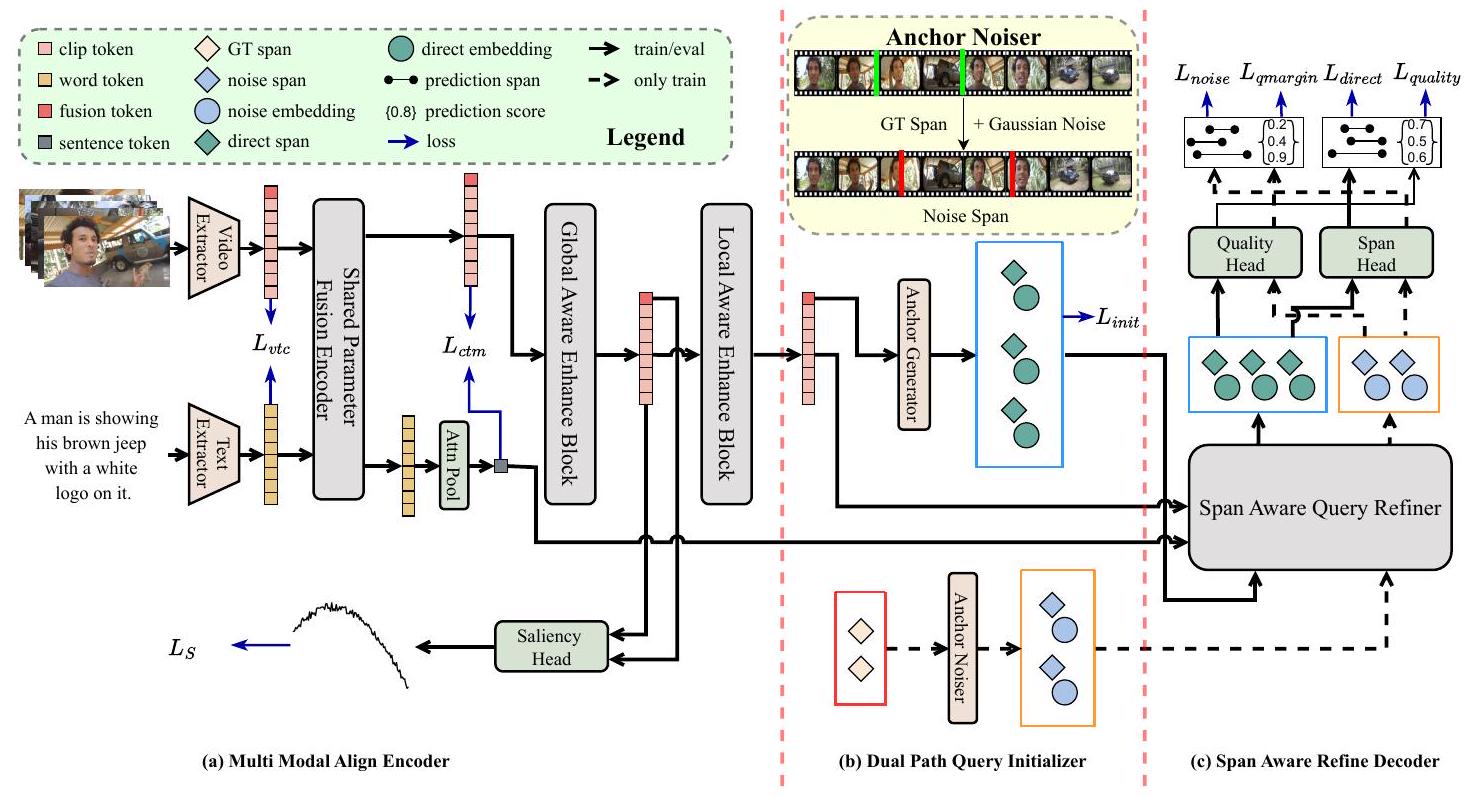
Figure 2: SA-DETR의 전체 개요. 주어진 비디오-텍스트 쌍에 대해, Multi Modal Align Encoder에서는 먼저 frozen backbone을 사용하여 feature를 추출한 다음, modal fusion 전후로 비디오-텍스트 및 클립-텍스트 수준에서 시각 및 텍스트 feature를 정렬한다. 또한, Moment Retrieval 및 Highlight Detection task의 다양한 관점에서 fusion visual feature를 강화한다. Dual Path Query Initializer에서는 direct Query 그룹에서 fusion token으로 span anchor를 초기화하고, noise Query 그룹에서는 GT span에 노이즈를 추가하여 span anchor를 생성한다. Span Aware Refine Decoder에서는 해당 span anchor의 안내에 따라 fusion feature를 사용하여 Query를 refine하고 최종 예측 span과 품질 점수를 얻는다. 특히, noise Query는 학습 단계에서만 사용된다.
2.2 Denoise Learning
DN-DETR (Li et al., 2022)는 DETR 기반 방법론의 느린 수렴 문제를 해결하기 위해 denoise learning을 처음 도입했다. 이 접근 방식은 GT bounding box에 작은 perturbation을 추가하여 anchor box로 사용함으로써, 모델 수렴을 위한 우회 경로를 제공한다. DINO (Zhang et al., 2022b)는 denoise learning을 contrastive setting으로 확장하여, 다양한 정도의 noise를 positive 및 negative 그룹으로 활용했다. MomentDiff (Li et al., 2024)는 generative diffusion model을 활용하여 noise로부터 비디오 moment를 복구함으로써, 데이터셋 편향을 완화하고 검색 정확도를 향상시켰다. DenoiseLoc (Xu et al., 2023)은 비디오 활동 localization task에 denoise learning을 적용하여 경계 모호성을 완화했다.
위 방법들과 유사하게, 우리는 contrastive setting을 사용한 denoise learning을 적용한다. 이는 모델 수렴을 가속화할 뿐만 아니라, noise Query 그룹에서 다양한 noise scale로 생성된 span anchor가 direct Query 그룹에서 초기화된 덜 정밀한 span anchor를 효과적으로 시뮬레이션할 수 있게 한다. 이는 다양한 초기 품질의 span anchor로부터 정확한 예측을 정제하는 모델의 능력을 향상시킬 수 있다.
3 Method
3.1 Objective and Overall
주어진 비디오-텍스트 쌍에 대해, 우리는 비디오를 개의 클립 으로, 텍스트를 개의 단어 토큰 으로 표현한다. Moment Retrieval의 목표는 텍스트에 설명된 스팬을 찾는 것으로, 이는 으로 표현된다 (는 스팬의 중심, 는 스팬의 너비를 각각 의미하며, N은 텍스트와 관련된 스팬의 개수이다). Highlight Detection의 목표는 각 비디오 클립과 텍스트 설명 간의 상관 점수 를 계산하는 것이다. SA-DETR의 전체적인 구조는 Figure 2에 나타나 있다.
3.2 Multi Modal Align Encoder
Feature Extractor. 주어진 비디오에 대해, 우리는 이를 **겹치지 않는 클립(non-overlapping clips)**으로 나누고, frozen video extractor를 사용하여 클립 수준에서 feature를 추출하여 **visual feature **를 얻는다. 주어진 텍스트에 대해서는 frozen text extractor를 활용하여 **단어 수준의 textual feature **를 추출한다.
Multi Stage Modal Aligner. 비디오와 텍스트의 정렬(alignment) 및 융합(fusion)은 모델이 둘 사이의 관계를 인지하는 데 필수적이다. 이전 방법들(Lei et al., 2021; Moon et al., 2023b)은 시각 및 텍스트 feature를 직접 병합하여 중요한 연결성을 간과했다. TR-DETR(Sun et al., 2024)은 비디오와 텍스트 feature를 여러 수준에서 정렬했지만, 융합 단계의 영향을 간과했다. 이를 위해 우리는 Multi Stage Modal Aligner를 개발하여, 모달 융합 전후에 각각 비디오-텍스트 수준 및 클립-텍스트 수준에서 feature를 정렬한다. 전자는 의미적으로 관련된 비디오와 텍스트가 의미 공간에서 유사하도록 보장하며, 후자는 모델이 의미와 강하게 연관된 클립 feature를 인식하도록 한다. 이러한 정렬 순서는 모델이 거친 수준에서 미세한 수준으로(coarse-to-fine) 비디오와 텍스트 간의 관계를 이해하는 데 도움을 준다.
**visual feature **와 **textual feature **에 대해, 우리는 먼저 두 개의 개별 MLP를 사용하여 이들을 동일한 차원 로 투영하여 ****와 ****를 얻는다.
비디오-텍스트 정렬을 적용하기 위해, 우리는 mean pooling을 사용하여 비디오 feature와 텍스트 feature를 풀링한 다음, CLIP(Radford et al., 2021)의 contrastive loss를 채택하여 **video-text contrastive loss **를 얻는다.
이어서, 우리는 **visual feature **를 학습 가능한 **fusion token **와 연결한 다음, 공유 파라미터를 가진 cross-attention layer를 사용하여 시각 및 텍스트 feature를 융합하여 **text-related visual feature **와 **video-related textual feature **를 얻는다. 구체적으로, 우리는 visual feature 를 로, textual feature 를 와 로 투영하여 text-related visual feature를 얻는다. video-related textual feature의 과정은 그 반대이다. 특히, 우리는 에 positional embedding을 추가한다.
클립-텍스트 정렬을 수행하기 위해, 우리는 video-related textual feature 에 attention pooling을 사용하여 sentence token 를 도출한다. 그런 다음, fusion token이 없는 visual feature 와 사이의 코사인 유사도 를 계산하고, TR-DETR의 과 UniVTG(Lin et al., 2023)의 를 사용하여 fine-grained alignment를 수행한다. 클립을 해당 텍스트와 정렬하는 것 외에도, 모델은 클립과 관련 없는 텍스트 간의 비대응성(non-corresponding)도 학습해야 한다. 이를 위해 우리는 UniVTG의 ****를 통합한다. 클립-텍스트 매칭 손실은 세 부분으로 구성된다: .
Local and Global Enhance Block. Moment Retrieval과 Highlight Detection은 모두 비디오-텍스트 이해를 요구하지만, 서로 다른 관점에서 접근한다. Highlight Detection은 다양한 클립과 텍스트 간의 관련성 차이를 강조하며, **전역적인 인식(global awareness)**을 필요로 한다. 반면, Moment Retrieval은 연속적인 클립의 세그먼트를 찾는 데 중점을 두며, **지역적인 인식(local awareness)**을 필요로 한다. 이를 위해 우리는 특정 task에 따라 feature를 강화하기 위한 local/global enhance block을 고안했다.
**전역적인 인식(global awareness)**을 위해, 우리는 표준 Transformer Encoder를 global enhance block으로 사용하여 ****를 얻는다. QDDETR(Moon et al., 2023b)을 따라, 우리는 를 사용하여 HD score와 saliency loss 를 생성한다.
**지역적인 인식(local awareness)**을 위해, 우리는 UVCOM(Xiao et al., 2024)에서 영감을 받아 stride가 1, 3, 1인 간단한 3계층 스택형 1D convolution을 local enhancement block으로 적용하여 ****를 얻는다. 마지막으로, 우리는 를 fusion feature 와 fusion token 로 분할한다.
3.3 Dual Path Query Initializer
Direct Query group Initializer
비디오-텍스트 인스턴스 관련 초기화 span anchor를 얻기 위해 우리는 간단한 방법을 사용한다. fusion token 와 간단한 3-layer MLP를 사용하여 를 생성한다. 여기서 는 direct Query의 수이다. 이 span anchor들은 Hungarian matching을 통해 GT span과 매칭되어 초기화 moment loss 를 생성한다. 또한, direct Query group의 content embedding 는 모든 값이 0인 학습 가능한 파라미터로 초기화된다.
Noise Query group Initializer
우리는 GT span의 경계를 교란(perturb)하여 noise Query group에 noise span anchor를 구성한다. 구체적으로, 주어진 GT span 와 noise scale 에 대해, 우리는 랜덤 노이즈를 도입하여 noised span anchor 를 생성한다. 이때 , 를 만족하고, noise span anchor가 유효한 상태를 유지하도록 한다. 우리는 contrastive learning 접근 방식을 사용하여 positive 및 negative 그룹을 생성하고, 고품질 및 저품질 span anchor를 각각 시뮬레이션한다. **negative noise group의 noise scale 는 positive group 보다 큰 상수 **이다. 각 GT에 대해 우리는 개의 positive 및 negative noise span anchor를 생성한다. 또한, noise Query group의 content embedding은 direct Query group과 구별하기 위해 모든 값이 1인 학습 가능한 파라미터로 초기화된다.
3.4 Span Aware Refine Decoder
Span Aware Query Refiner. span anchor의 guidance를 최대한 활용하기 위해, Figure 3에 나타난 Span Aware Query Refiner를 도입한다. Direct Query 그룹의 i번째 refine 프로세스를 예시로 들어 설명한다. 입력은 i번째 span anchor , i번째 content embedding , fusion feature 및 sentence token 를 포함한다.
기존 방법들을 따라, 우리는 self-attention layer를 사용하여 Query들 간의 정보를 교환하고 중복을 제거한다. 구체적으로, 는 및 로 projection된다. 또한, 를 positional embedding 로 변환한다. 구체적인 과정은 다음과 같다:
우리는 Span Based Enhance Block을 도입하여, 텍스트 메모리의 guidance를 받아 각 content embedding을 해당 span anchor의 비디오 클립으로 강화한다. 목표는 cross-attention layer에서 content embedding과 fusion feature 간의 불일치를 완화하는 것이다. 먼저, Temporal Align (Xu et al., 2020)을 사용하여 span anchor 를 기반으로 fusion feature 를 샘플링하여, 샘플 feature TemporalAlign 를 얻는다. 여기서 는 샘플링된 클립의 수이다. 다음으로, 를 sentence token 로 modulate하여 텍스트와 관련된 를 강화한다:
여기서 , 는 학습 가능한 파라미터이며, 는 element-wise multiplication을 나타낸다. 텍스트 관련 샘플 feature 를 얻은 후, gate fusion (Jang et al., 2023)을 사용하여 이를 와 융합한다:
여기서 , 는 학습 가능한 파라미터이다. 다음으로, cross-attention layer를 사용하여 content embedding과 fusion feature 를 융합한다. 를 로, 를 와 로 projection한 다음, 에 positional encoding 를 적용한다. 우리는 위치와 내용의 상호작용을 분리하기 위해 (Liu et al., 2022) feature와 positional encoding을 더하는 대신 직접 concatenate하며, attention map은 다음과 같이 얻어진다:
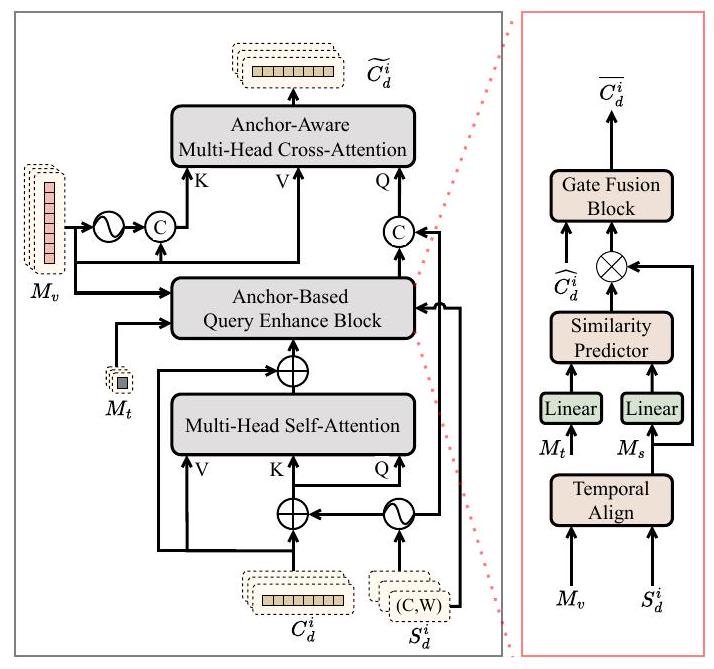
Figure 3: Span Aware Query Refiner의 구조
attention map 을 얻은 후, CNM (Zheng et al., 2022)에서 영감을 받아 span anchor를 사용하여 Gaussian mask를 생성한다. 즉, span anchor 에 대해:
여기서 는 Gaussian mask의 스케일을 제어하는 하이퍼파라미터이다. 이 mask들은 attention map을 modulate하는 데 사용된다:
마지막으로, 간단한 feedforward network를 사용하여 refined content embedding 를 얻는다. Prediction Head. 우리는 간단한 3-layer MLP를 사용하여 span anchor의 offset 을 예측하고, refined span anchor 를 얻는다. BAM-DETR (Lee and Byun, 2023)을 따라, 단일 layer Linear를 사용하여 Query quality 를 예측한다.
3.5 Matching, Objective and Inference
Matching. Direct Query 그룹의 초기화된 span과 예측 span의 경우, GT span과의 일대일 대응이 없으므로 Hungarian matching을 사용하여 GT span과 매칭한다. noise Query 그룹의 예측 span의 경우, 예측 span을 해당 GT span과 직접 매칭한다.
Moment Loss. Direct query 그룹을 예로 들면, 실제 span 과 그에 매칭된 예측 span 에 대해 L1 loss와 giou loss(Rezatofighi et al., 2019)를 사용하여 차이를 측정한다:
여기서 은 GT span의 개수이고, 는 과 의 균형 파라미터이다. 또한, 와 도 같은 방식으로 얻을 수 있다. positive noise Query 그룹의 예측 span만이 moment loss를 생성한다. 총 moment loss는 이다.
Quality Loss. quality score는 예측의 품질을 직접적으로 측정한다. Direct Query 그룹의 경우, BAM-DETR을 따라 각 예측 span과 모든 GT span 사이의 **최대 교차 비율(maximum intersection ratio)**을 계산하여 quality score를 결정한다. 또한, 매칭된 쌍을 강조하기 위해 해당 span에 더 높은 가중치를 부여한다:
만약 가 어떤 GT span과 매칭되면 이고, 그렇지 않으면 이다.
positive noise Query 그룹과 해당 negative noise Query 그룹에 의해 생성된 quality score 와 에 대해서는, Query의 품질을 인지하는 모델의 능력을 향상시키기 위해 margin loss를 사용한다:
여기서 는 배치 내 GT span의 개수이고, 는 positive quality와 negative quality 사이의 margin이며, 총 quality loss는 이다.
Total Loss. 모델의 총 loss는 다음 네 부분으로 구성된다: Moment loss , Quality loss , Align loss 및 Saliency loss :
여기서 는 균형 가중치이다.
Inference. noise Query 그룹은 학습 단계에서만 활성화된다. 추론 단계에서는 가장 높은 quality score를 가진 span을 최종 예측으로 사용한다.
4 Experiments
4.1 Datasets and Metrics
데이터셋. 우리는 QVHighlights, TACoS, Charades-STA 데이터셋으로 실험을 수행한다. 지면 제약으로 인해 데이터셋 관련 자세한 내용은 Appendix A.1에서 확인할 수 있다.
평가 지표. 우리는 이전 연구들(Lei et al., 2021, Moon et al., 2023b)에 따라 모델을 평가한다.
- Moment Retrieval의 경우, 기본적으로 IOU 임계값 0.5와 0.7에서의 Recall@1을 보고한다.
- QVHighlights의 경우, 여러 GT span이 있을 때 IOU 임계값 0.5와 0.75에서의 mAP를 기록하며, IOU 임계값 [0.5:0.05:0.95]에서의 평균 mAP도 보고한다.
- TACoS의 경우, Top-1 Prediction의 mIOU도 보고한다.
- Highlight Detection의 경우, QVHighlights 데이터셋에서 mAP와 HIT@1을 보고한다.
4.2 Implement Details
Frozen Backbone. 공정한 비교를 위해, 우리는 사전학습된 SlowFast (Feichtenhofer et al., 2019), CLIP (Radford et al., 2021), VGG (Simonyan and Zisserman, 2014)를 비디오 feature extractor로, 그리고 CLIP, GloVe (Pennington et al., 2014)를 텍스트 feature extractor로 선택하였다. 구체적으로, QVHighlights와 TACoS의 경우, 비디오를 2초 클립으로 자른 후 CLIP+SlowFast를 사용하여 비디오 feature를 추출하고, CLIP으로 단어 토큰을 추출한다. Charades-STA의 경우, CLIP+SlowFast visual backbone을 사용할 때는 비디오를 1초 클립으로 자르고 CLIP을 사용하여 단어 토큰을 추출한다. VGG feature를 활용할 때는 비디오를 1/8초 클립으로 나누고 GloVe를 사용하여 텍스트를 인코딩하여 단어 토큰을 얻는다.
Training Settings. 모든 실험에서 Shared Parameter Fusion Encoder, Global Aware Enhance Block, Span Aware Query Refiner는 각각 2개의 layer로 구성하였다. 모든 Transformer-like 구조에 대해 모델 차원(dimension)은 256, head 수는 8로 설정하였다. AdamW (Loshchilov and Hutter, 2017)를 optimizer로 사용하였다. 모든 실험은 단일 RTX3090 GPU에서 torch2.2.1+cu118 환경으로 수행되었다. 지면 제약으로 인해, 더 많은 하이퍼파라미터 및 loss 설정은 Appendix A.2에서 확인할 수 있다.
| Method | MR | HD | |||||
|---|---|---|---|---|---|---|---|
| R1 | mAP | VeryGood | |||||
| @0.5 | @0.7 | @0.5 | @0.75 | Avg. | mAP | HIT@1 | |
| M-DETR | 52.89 | 33.02 | 54.82 | 29.40 | 30.73 | 35.69 | 55.60 |
| UniVTG | 58.86 | 40.86 | 57.60 | 35.59 | 35.47 | 38.20 | 60.69 |
| MH-DETR | 60.05 | 42.28 | 60.75 | 38.13 | 38.38 | 38.22 | 60.51 |
| QD-DETR | 62.40 | 44.98 | 62.52 | 39.88 | 39.86 | 38.94 | 62.40 |
| EaTR | 61.36 | 45.79 | 61.86 | 41.91 | 41.74 | 37.15 | 58.65 |
| TR-DETR | 64.66 | 48.96 | 63.98 | 43.73 | 42.62 | 39.91 | 63.42 |
| CG-DETR | 65.43 | 48.38 | 64.51 | 42.77 | 42.86 | 40.33 | 66.21 |
| UVCOM | 63.55 | 47.47 | 63.37 | 42.67 | 43.18 | 39.74 | 64.20 |
| BAM-DETR | 62.71 | 48.64 | 64.57 | 46.33 | 45.36 | - | - |
| SA-DETR | 64.96 | 49.09 | 65.30 | 47.80 | 47.40 | 40.02 | 65.69 |
Table 1: QVHighlights 온라인 테스트 분할에 대한 Moment Retrieval 및 Highlight Detection의 통합 결과.
| Method | feat | R1@0.5 | R1@0.7 |
|---|---|---|---|
| 2D-TAN | VGG | 40.94 | 22.85 |
| QD-DETR | VGG | 52.77 | 31.13 |
| TR-DETR | VGG | 53.47 | 30.81 |
| MH-DETR | VGG | 55.47 | 32.41 |
| SA-DETR | VGG | 55.59 | 37.1 |
| 2D-TAN | SF+C | 46.02 | 27.40 |
| M-DETR | SF+C | 52.07 | 30.59 |
| QD-DETR | SF+C | 57.31 | 32.55 |
| TR-DETR | SF+C | 57.61 | 33.52 |
| UniVTG | SF+C | 58.01 | 35.65 |
| CG-DETR | SF+C | 58.44 | 36.34 |
| UVCOM | SF+C | 59.25 | 36.64 |
| BAM-DETR | SF+C | 59.95 | 39.38 |
| SA-DETR | SF+C | 61.16 | 41.51 |
Table 2: Charades-STA 테스트 분할 결과. SF는 SlowFast를, C는 CLIP을 나타낸다.
4.3 Main Results
QVHighlights 결과
Table 1에서 보여지듯이, 우리는 QVHighlights의 test split에서 SA-DETR의 Moment Retrieval 및 Highlight Detection 성능을 다른 DETR 기반 방법들과 비교하였다. 공정한 비교를 위해, 모든 모델은 사전학습 없이 비디오와 텍스트 쌍만으로 scratch부터 학습되었다.
Moment Retrieval의 경우, SA-DETR는 거의 모든 metric에서 이전 방법들보다 훨씬 뛰어난 성능을 보였는데, 이는 instance-related span guidance의 중요성을 강조한다. 비록 HD(Highlight Detection) task가 우리 방법의 주된 초점은 아니지만, multi-stage feature alignment 및 fusion 덕분에 모델이 경쟁력 있는 결과를 달성할 수 있었다.
Charades-STA 및 TACoS 결과
우리는 Charades-STA 및 TACoS 데이터셋의 test split에서 우리 모델의 MR(Moment Retrieval) 성능을 테스트하였다.
| Method | R1@0.3 | R1@0.5 | R1@0.7 | mIOU |
|---|---|---|---|---|
| 2D-TAN | 40.01 | 27.99 | 12.92 | 27.22 |
| VSLNet | 35.54 | 23.54 | 13.15 | 24.99 |
| M-DETR | 37.97 | 24.67 | 11.97 | 25.49 |
| UniVTG | 51.44 | 34.97 | 17.35 | 33.60 |
| CG-DETR | 52.23 | 39.61 | 22.23 | 36.48 |
| UVCOM | - | 36.39 | 23.32 | - |
| BAM-DETR | 56.69 | 41.54 | 26.77 | 39.31 |
| SA-DETR | 58.16 | 42.56 | 27.87 | 40.03 |
Table 3: TACoS test split 결과
Table 2에서 보여지듯이, Charades-STA에서 우리 모델은 VGG 또는 SlowFast+CLIP backbone 사용 여부와 관계없이 더 나은 성능을 달성했다. 특히 높은 IOU인 R1@0.7에서 MH-DETR (Xu et al., 2024)보다 4.69%, BAM-DETR보다 1.13% 더 높은 성능을 보였다. Table 3에서 보여지듯이, TACoS 데이터셋에서는 우리 모델이 이전의 모든 방법들을 상당한 차이로 능가한다.
4.4 Ablation Studies
주요 구성 요소 Ablation
Table 4에서 보듯이, 우리는 QVHighlights 데이터셋의 val split에 대해 ablation 실험을 수행하고 그 결과를 보고한다.
- **Feature Align (FA)**은 multi-stage feature alignment를 나타낸다.
- **Query Initialization (QI)**은 instance-related Query initialization을 의미한다.
- **Span Aware (SA)**는 span aware Decoder를 나타낸다.
- **Denoise Learning (DN)**은 contrastive denoise learning을 의미한다.
**Setting (a)**는 공유 파라미터와 local/global enhance block을 포함하는 fusion Encoder와 DAB-DETR (Liu et al., 2022)과 유사한 Decoder로 구성된 baseline 모델이다. 반면, **setting (j)**는 모든 구성 요소를 포함하는 완전한 모델을 나타낸다. 실험 결과는 다음과 같다:
- Setting (b)부터 (e)까지의 실험을 통해 각 구성 요소가 모델 성능에 긍정적인 영향을 미친다는 것을 확인하였다.
| settings | FA | QI | AD | DN | MR | HD | |||
|---|---|---|---|---|---|---|---|---|---|
| R1 @0.5 | R1 @0.7 | mAP Avg. | mAP | HIT@1 | |||||
| (a) | 62.39 | 46.77 | 40.71 | 39.33 | 62.13 | ||||
| (b) | 65.16 | 49.23 | 44.26 | 40.24 | 67.29 | ||||
| (c) | 63.74 | 50.32 | 45.39 | 39.42 | 62.90 | ||||
| (d) | 63.35 | 48.19 | 42.85 | 39.45 | 62.65 | ||||
| (e) | 65.03 | 48.39 | 43.69 | 39.50 | 62.39 | ||||
| (f) | 63.35 | 50.06 | 46.27 | 39.53 | 63.03 | ||||
| (g) | 63.87 | 50.13 | 45.96 | 39.63 | 64.13 | ||||
| (h) | 63.74 | 50.52 | 47.01 | 39.75 | 63.55 | ||||
| (i) | 65.29 | 51.35 | 47.54 | 40.59 | 66.32 | ||||
| (j) | 67.03 | 52.52 | 48.84 | 40.81 | 67.61 |
Table 4: QVHighlights val split에 대한 구성 요소 ablation.
| Method | R1@0.5 | R1@0.7 | mAP |
|---|---|---|---|
| baseline | 64.58 | 49.61 | 44.69 |
| +Dynamic Anchor | 64.97 | 51.16 | 47.19 |
| +Init Loss |
Table 5: Query Initializer에 대한 Ablation.
- Setting (c)와 비교하여 setting (f)는 DN을 도입한다. noise Query group은 direct Query group의 부정확한 span anchor를 시뮬레이션하며, 두 모듈의 조합은 성능 향상 효과를 가져온다. Setting (d)와 비교하여 setting (g)는 QI를 추가한다. 학습 가능한 instance-unrelated span anchor와 비교할 때, QI가 제공하는 instance-related span anchor는 Span Aware Decoder에서 더 나은 안내 역할을 수행한다.
- Setting (j)와 비교하여 setting (h)는 FA를 제거한다. 이 경우 Moment Retrieval과 Highlight Detection 성능이 모두 크게 감소하는데, 이는 잘 정렬된 feature가 두 task 모두에서 중요한 역할을 한다는 것을 나타낸다. Setting (j)와 비교하여 setting (i)는 AD를 제거한다. span anchor의 refinement 과정에서 guidance가 없으면 모델은 정확한 결과를 찾을 수 없게 되어 MR 성능이 저하된다.
Query Initializer에 대한 Ablation
Table 5에서 보듯이, 우리는 Query Initialization의 중요한 역할을 검증하기 위해 QVHighlights에 대한 ablation 실험을 설정하였다. instance-related span anchor를 학습 가능한 파라미터로 대체하고 를 제거한 baseline 모델의 성능은 크게 감소했다. dynamic span anchor를 추가한 후 성능이 향상되었고, 이어서 를 추가하여 span anchor의 초기화를 supervise함으로써 성능이 더욱 향상되었다.
Span Aware Query Refiner에 대한 Ablation
우리는 Span Aware Query Refiner의 구성 요소에 대한 ablation 실험을 수행했으며, Table 6에 그 결과가 나와 있다. 결과는 span anchor를 활용하여 content embedding을 강화하고 interaction을 조절하는 두 가지 방법 모두 모델 성능에 긍정적인 영향을 미친다는 것을 보여준다. 특히, 두 기술을 함께 사용할 때 가장 높은 성능 향상을 가져온다.
| modulate | enhance | R1@0.5 | R1@0.7 | mAP |
|---|---|---|---|---|
| 65.29 | 51.35 | 47.54 | ||
| 66.84 | 52.77 | 48.14 | ||
| 66.58 | 47.97 | |||
| 52.52 |
Table 6: Span Aware Query Refiner에 대한 Ablation.
Align Stage에 대한 Ablation
Table 7에서 보듯이, 우리는 modal fusion의 다른 단계에서 video-text level () 및 clip-text level () alignment가 모델 성능에 미치는 영향을 조사했다. 실험 결과, modal fusion, 특히 share-parameter encoder 이전에 video-text level feature alignment를 수행하면, paired video-text 쌍을 전역적인 관점에서 더 가까운 semantic space로 투영할 수 있음을 나타낸다. 이는 이들의 fusion과 이후의 clip-text level local alignment를 용이하게 한다.
| MR | HD | |||||
|---|---|---|---|---|---|---|
| R1 @0.5 | R1 @0.7 | mAP Avg. | mAP | HIT@1 | ||
| before | before | 66.71 | 52.71 | 48.24 | 40.89 | 66.58 |
| after | after | 65.42 | 51.74 | 47.56 | 40.20 | 65.94 |
| after | before | 65.55 | 51.87 | 47.85 | 40.65 | 65.81 |
| before | after | 67.03 | 52.52 | 48.84 | 40.81 | 67.61 |
Table 7: Align Stage에 대한 Ablation. 'before'는 modal fusion 이전, 'after'는 modal fusion 이후를 나타낸다.
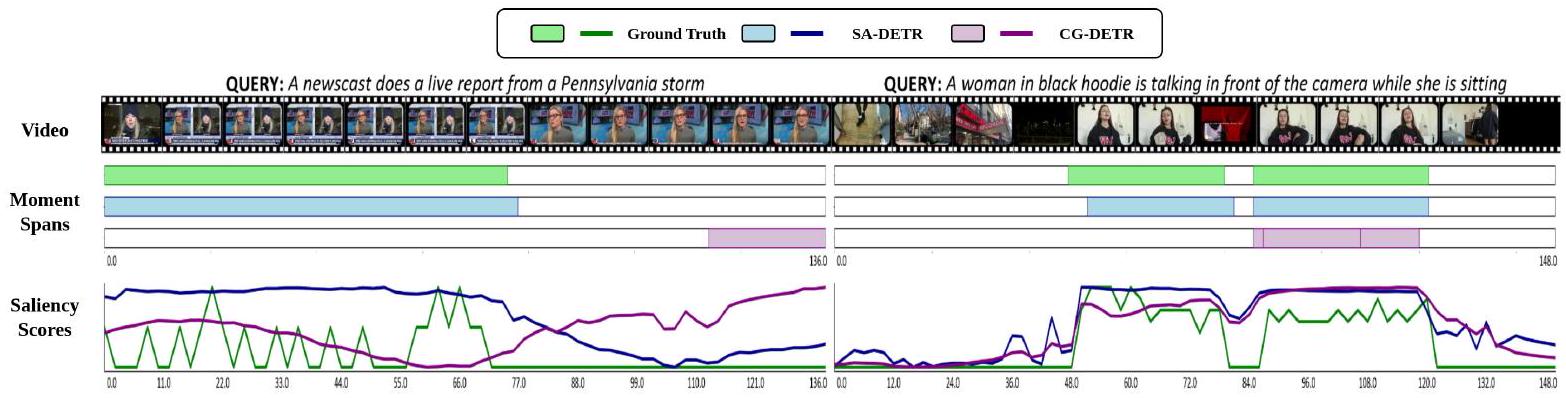
Figure 4: 정성적 결과 (Qualitative Results).
Contrastive Denoise Learning에 대한 Ablation
negative noise Query group은 높은 노이즈를 가진 span anchor를 제공하여, 모델이 다양한 Query의 품질을 더 잘 평가할 수 있도록 돕는다. Table 8에 제시된 바와 같이, 우리는 contrastive 설정의 효과를 확인하기 위한 실험을 수행했다. negative group을 사용하지 않을 때 모델의 성능은 크게 저하된다. 그러나 학습 과정 전반에 걸쳐 negative group과 positive group 간의 noise scale margin을 점진적으로 감소시키는 coarse learning 전략을 구현함으로써 모델의 성능이 향상된다. 또한, negative group과 positive group 간의 noise margin을 일정하게 유지함으로써 모델은 이들 간의 차이를 일관되게 식별할 수 있게 되어 가장 큰 성능 향상을 가져온다.
| Method | R1@0.5 | R1@0.7 | mAP |
|---|---|---|---|
| w/o contrastive groups | 66.52 | 52.32 | 47.88 |
| course learning | 52.19 | 48.36 | |
| fixed margin | 67.03 |
Table 8: Contrastive Denoise Learning에 대한 Ablation.
수렴 속도 (Convergence Speed)
우리는 QVHighlights 데이터셋에서 다른 방법들과의 수렴 속도 및 품질을 비교하고 val split에서의 mAP를 보고한다. Figure 5에서 보듯이, denoise learning을 사용하지 않을 때 모델의 성능은 다른 방법들을 능가하지만, SA-DETR의 초기 수렴은 다른 모델들과 유사하다. denoise learning을 추가하면 모델의 수렴 속도와 품질이 크게 향상된다.
공간 제약으로 인해 더 많은 ablation 실험은 Appendix A.3에서 확인할 수 있다.
4.5 Qualitative Results
Figure 4에서 볼 수 있듯이, 우리는 예측 결과를 CG-DETR과 비교한다. 왼쪽 사례에서 우리 방법은 텍스트와 관련된 세그먼트를 정확하게 결정하고 올바른 saliency score를 얻을 수 있다. 오른쪽 사례에서 우리 방법은 반복적이고 복잡한 세그먼트를 중복 없이 성공적으로 찾아낸다.
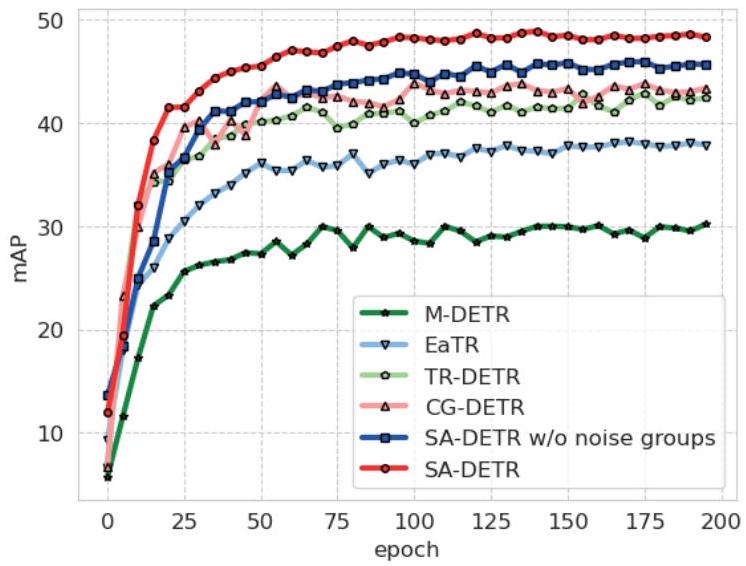
Figure 5: QVHighlights에서 공식 코드로 scratch부터 학습된 모든 모델의 수렴 속도 및 품질에 대한 다른 방법들과의 비교. 여기서는 val split에서의 mAP를 보고한다.
5 Conclusion
우리는 Moment Retrieval 문제를 해결하기 위한 효과적인 방법인 Span Aware DEtection TRansformer (SA-DETR) 를 제안한다. SA-DETR에서는 Query Initialization 및 Refinement 과정에서 span anchor의 중요성을 탐구한다. 구체적으로, 우리는 instance 관련 fuse token을 사용하여 span anchor를 초기화하고, GT label로 이를 supervise한다. 또한, span anchor를 통해 Query refinement를 유도하여 더욱 정확한 localization을 달성한다. 나아가, 우리는 다양한 granularity와 stage에서의 feature alignment가 모델 성능에 미치는 영향을 조사하고, denoise learning이 모델의 span awareness에 미치는 효과를 검증한다. 우리의 접근 방식은 QVHighlights, Charades-STA, TACoS 데이터셋에서 경쟁력 있는 결과를 달성하며 그 효과를 입증한다.
Limitation
우리의 방법은 span anchor를 인식하여 moment retrieval task를 효과적으로 해결하지만, 다음과 같은 측면에서 여전히 몇 가지 한계가 존재한다:
- 우리는 초기화된 span과 정제된(refined) span 모두에 대해 Hungarian matching을 사용한다. 그러나 span anchor의 다른 layer와 GT(Ground Truth) label 간의 매칭 안정성은 고려하지 않는다. 결과적으로, GT label이 다른 layer의 다른 span anchor와 매칭되는 경우가 발생할 수 있으며, 이는 모델 성능 저하로 이어질 수 있다.
- 우리의 방법은 Modal Fusion 및 Align, Highlight Detection, Moment Retrieval을 통합된 프레임워크 내에서 해결하지만, 이 세 가지 문제는 각기 다른 강조점과 최적화 목표를 가지고 있다. 우리는 이들의 차이점이나 최적화 순서를 고려하지 않고 단순히 동시에 최적화한다.
- 우리의 실험은 비디오 및 텍스트 모달리티만을 포함한다. 오디오와 같은 다른 모달리티를 통합하기 위한 일반적인 멀티모달 융합 구조는 설계하지 않았다.
Acknowledgments
본 연구는 중국 국가자연과학기금(National Natural Science Foundation of China)의 No. 62276110, No. 62172039 과제, 그리고 화중과학기술대학교(HUST)와 평안재산보험연구소(Pingan Property Casualty Research)의 공동 연구소(HPL) 기금의 지원을 받아 수행되었다. 또한, 본 논문의 품질 향상에 기여한 익명의 심사위원들께 감사드린다.
| Datasets | vid feat. | txt feat. | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| bs | epoch | ||||||||||||||||||
| QVHighlights | SF+C | CLIP | 32 | 200 | 1e-4 | 10 | 5 | 10 | 2 | 0.2 | 0.6 | 10 | 1 | 1 | 0.4 | 1 | 1 | 1 | 1 |
| TACoS | SF+C | CLIP | 32 | 200 | 2e-4 | 10 | 5 | 15 | 2 | 0.2 | 0.6 | 10 | 1 | 10 | 0.4 | 0 | 4 | 1 | 1 |
| Charades-STA | SF+C | CLIP | 32 | 200 | 2e-4 | 10 | 5 | 15 | 2 | 0.2 | 0.6 | 10 | 1 | 10 | 0.4 | 0 | 4 | 1 | 1 |
| Charades-STA | VGG | GloVe | 16 | 100 | 1e-4 | 10 | 5 | 10 | 2 | 0.2 | 0.6 | 10 | 1 | 10 | 0.4 | 0 | 4 | 1 | 1 |
Table 9: 구현 세부 사항. 왼쪽에서 오른쪽으로: bs는 batch size, lr은 learning rate, ****는 Queries의 수, ****은 noise group의 수, ****는 Temporal Align에서 샘플링되는 프레임 수, ****는 Gaussian mask 생성의 하이퍼파라미터, ****와 ****은 positive 및 negative noise group의 noise scale, ****는 에서 일치하는 span의 가중치, ****는 의 margin, ** 및 **는 각각 및 의 가중치를 나타낸다.
A Appendix
A. 1 Details of Datasets
QVHighlights. QVHighlights 데이터셋은 Moment Retrieval과 Highlight Detection task를 동시에 다루기 위해 구축되었다. 이 데이터셋은 일상 활동 브이로그 및 뉴스 보도를 포함한 다양한 콘텐츠를 포함한다. 이 데이터셋에서 단일 쿼리는 여러 순간에 해당할 수 있으며, 10,148개의 비디오, 10,310개의 쿼리, 그리고 그와 관련된 18,367개의 순간으로 구성된다. Charades-STA. Charades-STA는 Charades [Sigurdsson et al., 2016] 데이터셋에서 파생되었으며, 실내 활동에 중점을 둔다. 이 데이터셋은 6,672개의 비디오와 16,124개의 비디오-쿼리 쌍을 포함한다. TACoS. TACoS는 MPII Cooking Composite Activities 데이터셋 [Rohrbach et al., 2012]을 기반으로 구축되었으며, 주방에서의 인간 활동을 포착한다. 이 데이터셋은 127개의 비디오와 18,818개의 비디오-쿼리 쌍을 특징으로 한다.
A. 2 More Implementation Details
수렴 안정성을 확보하기 위해, 우리는 QVHighlights에 대해 40 epoch 이후 학습률(learning rate)을 점진적으로 0으로 감소시킨다. 추가적인 하이퍼파라미터 및 손실 설정은 Table 9를 참조하라.
A. 3 More Ablation Studies
노이즈 그룹 수(Noise Group Nums)에 대한 Ablation
우리는 denoise learning에서 노이즈 그룹 수가 QVHighlights 성능에 미치는 영향을 조사했다. Figure 6에서 볼 수 있듯이, 노이즈 그룹 수가 적을 때는 모델이 충분한 추가적인 supervisory information을 얻지 못한다. 반대로, 노이즈 그룹 수가 많을 때는 지속적인 노이즈가 모델의 수렴에 영향을 미치고 원래의 학습 경로를 방해한다. 경험적 증거에 따르면, 노이즈 그룹 수를 5로 설정했을 때 모델이 최적의 성능을 보인다.
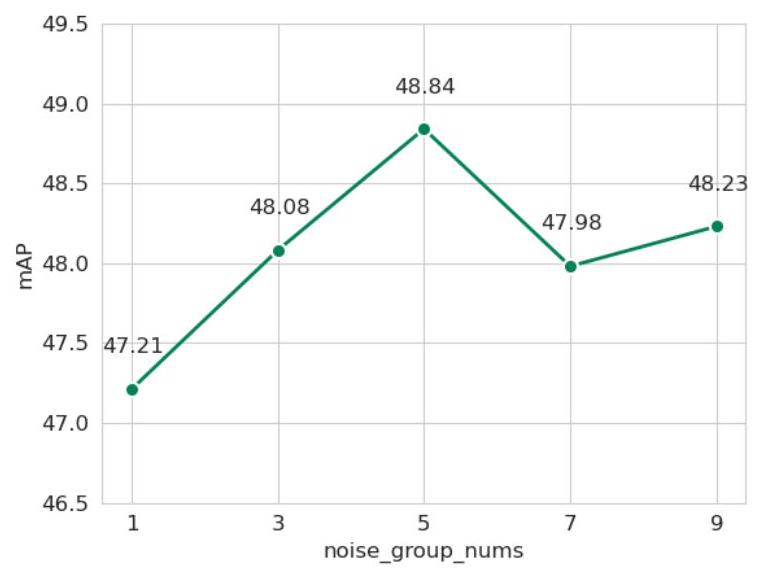
Figure 6: 노이즈 그룹 수에 대한 Ablation
| MR | HD | |||||
|---|---|---|---|---|---|---|
| R 1 | R 1 | mAP | mAP | |||
| Avg. | ||||||
| 63.74 | 50.52 | 47.01 | 39.75 | 63.55 | ||
| 65.68 | 50.77 | 47.19 | 40.03 | 64.39 | ||
| 65.29 | 47.77 | 39.97 | 63.42 | |||
| 52.52 |
Table 10: Feature Align Loss에 대한 Ablation
| Method | R1@0.5 | R1@0.7 | mAP |
|---|---|---|---|
| QD-DETR | 46.84 | 41.35 | |
| +dynamic anchor | 62.06 | 47.42 | 42.09 |
| +Gaussian mask | 62.0 |
Table 11: Component Generalizability에 대한 Ablation.
| Method | mAP | ||
|---|---|---|---|
| M-DETR | |||
| QD-DETR | |||
| SA-DETR |
Table 12: 성능 통계 분석.
Abstract
Feature Align Loss에 대한 Ablation
Table 10에서 보듯이, 우리는 Feature Align Loss 와 이 QVHighlights에 미치는 영향을 조사했다.
실험 결과, 는 비디오와 텍스트를 전역적으로(global aware) 정렬하여 Highlight Detection 성능을 크게 향상시키는 것으로 나타났다.
반면 은 클립과 텍스트를 지역적으로(local aware) 정렬하여 Moment Retrieval 성능을 향상시켰다.
이 두 가지 손실 함수의 조합은 성능 향상에 시너지 효과를 가져왔다.
Component Generalizability에 대한 Ablation
Table 11에서 보듯이, 우리는 **우리의 instance related span anchor와 Gaussian mask modulate의 일반화 가능성(generalizability)**을 조사했다.
이들을 QDDETR에 추가하고 QVHighlights val split에서 결과를 보고했다.
이러한 결과는 우리의 구성 요소들이 기존 모델에 효과적으로 통합되어 성능을 향상시킬 수 있음을 보여주며, 그들의 일반화 가능성을 확인시켜준다.
성능 통계 분석
우리는 결과의 **견고성(robustness)과 통계적 유의미성(statistical significance)**을 검증하기 위해 실험을 수행했다.
구체적으로, QVHighlights val set에서 seed 0, 1, 2, 3, 2018을 사용하여 실험을 반복했다.
Moment Retrieval metrics의 평균과 표준 편차는 Table 12에 제시되어 있다.