SEMU: Singular Value Decomposition을 이용한 효율적인 Machine Unlearning
기존 Machine Unlearning (MU) 방법들은 모델의 많은 파라미터를 수정해야 하므로 계산 비용이 높고, 원본 학습 데이터셋에 의존한다는 한계가 있었습니다. 본 논문에서는 Singular Value Decomposition (SVD)을 활용하여 이러한 문제를 해결하는 SEMU(Singular Value Decomposition for Efficient Machine Unlearning)를 제안합니다. SEMU는 SVD를 이용해 특정 데이터를 잊는 데 필요한 핵심 가중치만을 식별하고 최소한으로 수정함으로써, 원본 데이터셋 없이도 효율적인 unlearning을 가능하게 합니다. 이를 통해 모델의 기존 지식은 보존하면서 불필요한 정보만 선택적으로 제거하여, 파라미터 및 데이터 효율성 측면에서 기존 방법들을 능가하는 성능을 보여줍니다. 논문 제목: SEMU: Singular Value Decomposition for Efficient Machine Unlearning
Sendera, Marcin, et al. "SEMU: Singular Value Decomposition for Efficient Machine Unlearning." arXiv preprint arXiv:2502.07587 (2025).
SEMU: Singular Value Decomposition for Efficient Machine Unlearning
Abstract
최근 몇 년간 생성형 foundational model의 능력은 빠르게 발전했지만, 유해하고 안전하지 않은 행동을 방지하는 방법은 여전히 미흡하다. AI 안전 분야의 시급한 과제 중 하나로, 다가오는 안전 규제를 충족하기 위해 machine unlearning (MU)의 중요성이 점점 커지고 있다. 대부분의 기존 MU 접근 방식은 모델의 가장 중요한 파라미터를 변경하는 데 초점을 맞춘다. 그러나 이러한 방법들은 종종 모델의 상당 부분을 fine-tuning해야 하므로 높은 계산 비용과 학습 불안정성을 초래하며, 이는 일반적으로 원래 학습 데이터셋에 접근할 수 있어야 완화된다.
본 연구에서는 이러한 한계를 해결하기 위해 Singular Value Decomposition (SVD)을 활용하여 특정 데이터 포인트를 선택적으로 잊게 하는 compact한 저차원 projection을 생성한다. 우리는 Singular Value Decomposition for Efficient Machine Unlearning (SEMU) 를 제안한다. 이는 MU를 두 가지 핵심 측면에서 최적화하도록 설계된 새로운 접근 방식이다. 첫째, SEMU는 수정해야 할 모델 파라미터의 수를 최소화하여, 모델 가중치에 최소한의 변경만을 가하면서 원치 않는 지식을 효과적으로 제거한다. 둘째, SEMU는 원래 학습 데이터셋에 대한 의존성을 제거하여, 추가적인 데이터 요구 사항 없이 모델이 이전에 습득한 지식을 보존한다.
광범위한 실험을 통해 SEMU가 데이터 사용량과 수정된 파라미터 수 측면에서 효율성을 크게 향상시키면서도 경쟁력 있는 성능을 달성함을 입증한다.
 Figure 1. 표준 machine unlearning 설정(상단 행)과 우리의 SEMU 방법(하단 행) 간의 차이점을 보여주는 그림. 표준 접근 방식과 달리, SEMU는 남은 데이터셋이 필요 없어 데이터 활용 측면에서 매우 효율적이다. 또한, SEMU는 특정 지식을 제거하기 위해 모델 가중치의 극히 일부만 수정한다. 이러한 희소성(sparsity)은 SVD projection(다이아몬드)을 통해 달성되며, 이는 가중치를 분리하고 forget batch를 처리하는 데 중요한 가중치를 식별한다. 결과적으로 SEMU는 수정되는 파라미터의 수를 크게 줄여 전반적인 효율성을 향상시킨다.
Figure 1. 표준 machine unlearning 설정(상단 행)과 우리의 SEMU 방법(하단 행) 간의 차이점을 보여주는 그림. 표준 접근 방식과 달리, SEMU는 남은 데이터셋이 필요 없어 데이터 활용 측면에서 매우 효율적이다. 또한, SEMU는 특정 지식을 제거하기 위해 모델 가중치의 극히 일부만 수정한다. 이러한 희소성(sparsity)은 SVD projection(다이아몬드)을 통해 달성되며, 이는 가중치를 분리하고 forget batch를 처리하는 데 중요한 가중치를 식별한다. 결과적으로 SEMU는 수정되는 파라미터의 수를 크게 줄여 전반적인 효율성을 향상시킨다.
1. Introduction
Machine unlearning은 모델이 특정 지식을 기억하지 않도록 수정하는 과정이다 (Bourtoule et al., 2021). 맥락에 따라 이 지식에는 유해한 편향이나 개인 정보 보호를 위해 제거해야 하는 사적인 인간 데이터가 포함될 수 있다. 그러나 딥 뉴럴 네트워크에서 machine unlearning을 구현하는 것은 복잡한 뉴런 시스템이 학습된 정보를 인코딩하는 얽힌 구조 때문에 특히 어렵다 (Kurmanji et al., 2023).
일반적인 machine unlearning 설정에서는 두 가지 데이터셋이 사용된다: 잊어야 할 지식을 포함하는 forget dataset과 유지해야 할 지식을 나타내는 remaining dataset이다 (Kurmanji et al., 2023). 그런 다음 전체 뉴럴 네트워크는 원치 않는 정보를 잊도록 조정된다. 그러나 이 접근 방식은 두 가지 주요 비효율성을 초래한다. 첫째, 많은 수의 모델 파라미터가 변경된다 (Sekhari et al., 2021). 일반적으로 전체 모델 또는 가중치의 상당 부분이 변경된다 (Fan et al., 2024). 둘째, 이 과정은 모델의 정확도를 유지하는 데 사용되지만 추가적인 계산 비용을 요구하는 remaining dataset에 크게 의존한다 (Jia et al., 2023; Kurmanji et al., 2023).
이러한 비효율성을 해결하기 위해 우리는 **Singular Value Decomposition for Efficient Machine Unlearning (SEMU)**를 제안한다. SEMU는 SVD를 활용하여 특정 데이터를 잊기 위해 수정이 필요한 모델 가중치의 핵심 부분집합을 식별하는 새로운 방법이다. 모델 가중치의 작은 부분집합만 변경함으로써, SEMU는 unlearning 과정에서 remaining dataset의 필요성을 제거한다. 이는 SEMU를 파라미터 변경 측면에서 효율적일 뿐만 아니라, 지식을 유지하는 데 필요한 반복 횟수와 데이터 포인트도 크게 줄여준다. 이러한 효율성은 unlearning 과정에서 개인 정보 보호 문제로 인해 학습 데이터에 대한 접근이 제한되는 시나리오에서 특히 유용하다.
SEMU는 gradient 정보와 SVD의 조합을 통해 개선을 달성한다. Gradient는 unlearning loss를 만족시키기 위해 모델을 조정하는 방법을 안내하고, SVD는 모델을 분해하여 잊는 데 중요한 가중치를 정확히 찾아낸다. 결과적으로 SEMU는 변경되는 파라미터의 수와 remaining dataset의 사용을 최소화한다. 분류 및 생성 task에 대한 광범위한 검증을 통해, 우리는 SEMU가 machine unlearning 분야의 state-of-the-art 방법들과 비교하여 경쟁력 있는 성능을 달성함을 입증한다. 더욱이, SEMU는 더 적은 모델 파라미터를 변경하고 remaining dataset의 필요성을 제거함으로써 효율성 측면에서 현재 접근 방식을 능가하여, 효과적이고 데이터 효율적인 솔루션이 된다. 우리 작업의 재현성을 보장하기 위해 코드를 공개적으로 제공한다.
우리의 기여는 다음과 같이 요약될 수 있다:
- 우리는 Singular Value Decomposition을 활용하여 핵심 가중치를 식별하고, unlearning을 위한 효율적인 모델 업데이트를 가능하게 하는 새로운 machine unlearning 방법인 SEMU를 소개한다.
- 우리는 remaining dataset이 필요 없는 machine unlearning 시나리오를 제안하여, 데이터 개인 정보 보호 문제를 해결하고 계산 오버헤드를 줄인다.
- 광범위한 실험적 검증을 통해, 우리는 효율적이고 신뢰할 수 있는 machine unlearning을 달성하는 SEMU의 효과를 입증한다.
2. Related Works
수많은 unlearning 접근 방식은 knowledge distillation에 기반을 둔다. (Kurmanji et al., 2023)에서는 teacher-student 프레임워크를 도입하여 다양한 시나리오에서 특정 데이터를 선택적으로 잊으면서 다른 인스턴스는 유지한다. 이들의 접근 방식은 삭제된 인스턴스의 식별을 모호하게 하기 위한 rewinding mechanism을 포함한다. 유사하게, (Chundawat et al., 2023)에서는 알고리즘에 학습 데이터가 없는 시나리오를 위한 distillation 기반 방법이 제안되었다. (Kong & Chaudhuri, 2024)에서는 또 다른 distillation 기반 기술이 conditional generative model에 맞춰져 있지만, 주로 text-to-image 및 text-to-speech 애플리케이션에 초점을 맞춰 평가되었다.
최근 연구인 (Sun et al., 2025)는 원본 모델 가중치를 변경하지 않고 입력 데이터를 교란하는 forget vector 개념을 도입한다. 그러나 이 방법은 이미지 분류에 특화되어 있으며 generative model에는 적용할 수 없다. 한편, (Kodge et al., 2024)의 저자들은 singular value decomposition 기반 접근 방식을 제안하는데, 이는 방법론적으로 SEMU와는 다르다. 이들은 forget 및 retain 클래스의 샘플 활성화를 분석하여 해당 feature space를 추정하고 상호 정보(mutual information)를 정량화한다. 이어서, 타겟 클래스에 특화된 활성화를 억제하기 위해 가중치를 조정한다. 그럼에도 불구하고, 이 방법은 데이터의 임의의 부분집합을 unlearning하도록 설계되지 않았다.
(Jia et al., 2023)의 저자들은 가중치 pruning을 통한 모델 희소화(sparsification)를 활용하여 근사적인 unlearning 모델과 scratch부터 재학습된 모델 간의 불일치를 최소화한다. 유사하게, (Thudi et al., 2022)의 저자들은 표준 편차 손실(standard deviation loss)을 도입하여 이러한 불일치를 줄이는 것을 목표로 한다. (Fan et al., 2024)에서는 SalUn 접근 방식이 제안되는데, 이는 독립적으로 또는 다른 unlearning 방법과 함께 적용될 수 있는 가중치 saliency map을 활용한다. SalUn은 forgetting loss를 기반으로 가장 영향력 있는 가중치(salient weights)를 식별하고, 이 가중치에 대한 파라미터 업데이트를 우선시한다. 이는 분류 및 생성 task 모두에서 고려된다.
몇몇 방법들은 generative model의 unlearning에 초점을 맞춘다. 예를 들어, (Li et al., 2024)는 masked autoencoder (MAE), vector-quantized GAN, diffusion model과 같이 불완전한 입력으로부터 이미지를 재구성하는 모델을 위해 설계되었다. 유사하게, (Moon et al., 2024)는 GAN과 VAE 모두에 맞춰져 있으며, (Sun et al., 2023) 및 (Bae et al., 2023)은 GAN과 VAE에 특화되어 있다.
또 다른 접근 방식인 (Chen et al., 2023a)는 네트워크 파라미터를 수정하는 대신, adversarial attack 전략과 유사하게 잊으려는 클래스의 결정 경계(decision boundary)를 조정하는 데 초점을 맞춘다. (Neel et al., 2021)에서 예시된 바와 같이, gradient descent 방법의 변형들도 unlearning task를 위해 제안되었다. (Chourasia & Shah, 2023)의 저자들은 noisy gradient descent 기반 솔루션을 제안하며, 재학습과의 구별 불가능성(indistinguishability)이 잔여 내부 데이터 상태로 인해 삭제 프라이버시를 보장하지 않는다고 주장한다. 한편, (Tarun et al., 2023)은 deep regression 및 forecasting model을 위한 unlearning 방법을 소개하고, (Chen et al., 2023c)는 반사실적 샘플(counterfactual samples)을 사용하여 모델에서 편향을 제거하는 문제를 다룬다.
3. Preliminaries on Machine Unlearning
3.1. Machine Unlearning setup
**MU(Machine Unlearning)**는 생성 능력에도 불구하고 의도치 않게 유해하거나 불법적인 콘텐츠를 생성할 수 있는 파운데이션 모델(foundational models)의 등장으로 인해 주목받고 있다. 유해한 prompt를 차단하거나 (예: 저작권 허가가 없는 콘텐츠와 같은) 문제가 있는 데이터를 제외하기 위해 모델을 처음부터 재학습하는 것이 이론적으로는 가능하지만, 이러한 접근 방식은 높은 계산 비용으로 인해 비실용적인 경우가 많다.
MU는 전체 재학습 없이도 모델에서 특정 데이터 포인트, 클래스 또는 개념을 제거할 수 있도록 함으로써 보다 효율적인 해결책을 제공한다. 그 목표는 모델의 성능을 유지하면서 잊어야 할 데이터셋(forgetting dataset)의 영향을 효과적으로 지우는 것이다. 결과적으로 생성된 모델은 잊어야 할 데이터셋이 제외된 나머지 데이터셋으로 재학습되었을 때의 모델과 거의 일치해야 한다.
정식으로, 개의 샘플로 구성된 학습 데이터셋 를 고려해보자. 여기서 supervised learning에서는 이다. 우리는 **잊어야 할 데이터셋(forgetting dataset)**을 로 정의하고, **나머지 데이터셋(remaining dataset)**은 그 보완 집합인 로 정의한다. 는 표준 학습을 사용하여 로 학습된 원래 모델을 나타낸다. 선행 연구에 따라, 로 모델 파라미터 를 처음부터 재학습하는 것이 MU의 골드 스탠다드(gold standard) 역할을 한다 (Kurmanji et al., 2023). 따라서 MU 방법의 주요 목표는 로부터 unlearned model 를 도출하여 의 영향을 효과적으로 제거하는 동시에, Retrain 방식에 대한 계산적으로 효율적인 대안이 되는 것이다. MU 방법에 따라, 도출 절차는 및/또는 데이터셋에 접근할 수 있다. 본 연구에서는 **이미지 분류(image classification)**와 **이미지 생성(image generation)**이라는 다음 비전 task를 고려한다.
이미지 분류 (Image Classification)
이 시나리오에서는 일반적으로 두 가지 설정을 정의할 수 있다: **무작위 데이터 망각(random data forgetting)**과 클래스별 망각(class-wise forgetting). 이 설정은 잊어야 할 데이터셋 가 어떻게 구성되는지에 따라 달라진다. 첫 번째 시나리오에서는 학습 세트에서 무작위로 선택된 데이터 포인트의 영향을 제거하는 것이 목표이며, 이는 저작권 허가가 없는 콘텐츠 제거와 같은 경우를 시뮬레이션한다. 두 번째 시나리오에서는 전체 클래스의 영향을 제거하는 것이 목표이다.
여기서는 모델 성능을 평가하기 위해 표준 MU 평가 지표를 채택한다. 구체적으로, 우리는 다음을 평가한다:
- unlearning accuracy (UA): unlearned model 의 잊어야 할 데이터셋 에 대한 정확도(accuracy)를 1에서 뺀 값;
- membership inference attack (MIA): 에 대한 의 MIA 취약성을 측정하는 개인 정보 보호 지표;
- remaining accuracy (RA): 의 나머지 데이터셋 에 대한 정확도;
- testing accuracy (TA): 의 테스트 세트에 대한 정확도.
조건부 Diffusion Model을 이용한 이미지 생성 (Image Generation with Conditional Diffusion Models)
본 연구에서는 두 가지 인기 있는 조건부 diffusion model 클래스에 중점을 둔다: classifier-free guidance를 사용하는 denoising diffusion probabilistic models (DDPMs) (Ho et al., 2020)와 latent diffusion models (LDMs) 기반의 stable diffusion (Rombach et al., 2022).
이미지 생성에서의 MU를 더 잘 이해하기 위해, 먼저 diffusion process에 대한 개요를 제공한다. 는 로 파라미터화되고 에 조건화된 **노이즈 추정기(noise estimator)**를 나타낸다. 여기서 는 **forward diffusion process의 단계에서 노이즈에 의해 손상된 데이터(또는 latent feature)**를 의미한다. 의 목표는 reverse diffusion process에서 노이즈를 추정하는 것이다. 여기서 조건 는 이미지 클래스(DDPMs의 경우) 또는 **텍스트 prompt나 개념(LDMs의 경우)**일 수 있다.
diffusion process는 다음과 같이 정의된다:
여기서 는 에 조건화된 노이즈 추정기이고, 는 guidance factor이며, 는 **무조건부 노이즈 추정기(unconditional noise estimator)**이다. **추론(이미지 생성)**의 경우, 이 과정은 가우시안 노이즈 로 시작한다. 노이즈 추정기 를 사용하여, 모델은 를 얻기 위해 반복적으로 denoising을 수행하며, 최종적으로 생성된 이미지 를 생성한다.
3.2. Challenges in Machine Unlearning
MU가 실무자들에게 효과적으로 채택되기 위해서는 해결해야 할 몇 가지 중요한 과제들이 있다. 이러한 과제들은 기초 모델(foundational model)이 제기하는 끊임없이 진화하는 문제들로 인해 특히 더 시급하다.
그중 하나는 unlearning의 안정성과 일반성 부족인데, 최근 SalUn (Fan et al., 2024)과 같은 gradient 기반 방법들이 이를 완화하려고 시도했다. 이러한 방법들은 손실 함수의 gradient 크기를 기반으로, forgetting dataset 에 가장 관련성이 높은 파라미터들의 부분집합 를 식별한다. 이 부분집합을 random labeling (RL) 및 gradient ascent (GA)와 같은 표준 MU 방법으로 fine-tuning하여, 및 종종 의 데이터를 사용하여 unlearning objective를 최적화한다.
이러한 방법들이 효과적임에도 불구하고, 아직 광범위하게 연구되지 않은 문제점들을 야기한다. 첫째, 파라미터 부분집합 의 크기를 추정하는 것이 어렵다. 이는 **휴리스틱, 계산 집약적인 분석 또는 임의적인 선택(예: SalUn은 파라미터의 50%를 수정)**에 의존한다. 이로 인해 불필요하게 큰 파라미터 부분집합이 생성되는 경우가 많다. 둘째, 대규모 fine-tuning은 계산 비용과 불안정성을 증가시키며, 특히 이미지 생성 분야에서 일반화 성능에 부정적인 영향을 미 미친다. 이러한 비용 증가는 전체 remaining dataset 에 대한 fine-tuning에서 발생하는데, 이는 대규모 foundation model에는 비실용적이다.
4. SVD Disentanglement for Efficient Machine Unlearning (SEMU)
gradient 기반 unlearning의 한계를 극복하기 위해, 우리는 망각 데이터셋 로부터 도출된 가장 중요한 가중치 부분 공간 를 선택하기 위한 새롭고 이론적으로 근거 있는 방법을 제안한다. 우리의 접근 방식은 **Singular Value Decomposition (SVD)**를 사용하여 신경망의 각 layer에 대해 **더 낮은 차원의 중요한 가중치 부분 공간으로의 직교 투영(orthogonal projection)**을 도출한다. 특이값(또는 고유값)을 정규화함으로써, 우리는 이러한 부분 공간을 더욱 정제하여 가장 관련성 높은 방향만 유지한다. 차원 축소의 수준은 범위의 단일 하이퍼파라미터 에 의해 제어된다. 이 프레임워크는 Figure 2에 제시된 우리의 제안 방법인 **Singular Value Decomposition for Efficient Machine Unlearning (SEMU)**의 기반을 형성한다.
4.1. Singular Value Decomposition
SEMU를 더 잘 소개하기 위해, 먼저 SVD projection과 그 주요 속성들을 살펴보자. 딥러닝 모델의 맥락에서, SVD의 특정 속성들이 관련성이 높다. 신경망의 layer들은 일반적으로 공간의 **선형 연산자(linear operators)**로 표현되므로, Theorem A.1 (Horn & Johnson, 2012)의 Eq. 16을 다음 형태로 단순화할 수 있다:
여기서 파라미터 은 와 의 고유값(eigenvalues)의 양의 제곱근이며, 크기 순으로 내림차순 정렬된다.
Truncated SVD
선형 연산자 의 전체 SVD를 계산하는 것은 의 복잡도를 가지므로 계산 비용이 많이 든다. 대신 우리는 더 효율적인 대안인 truncated SVD에 집중할 수 있다. 이 접근 방식은 원본 행렬 의 **저랭크 근사(low-rank approximation) (랭크 )**를 찾는다.
truncated SVD는 다음과 같이 표현된다:
여기서 , 그리고 이다. 이 접근 방식은 SVD의 계산적으로 효율적인 근사를 가능하게 하면서도, 의 가장 중요한 구성 요소들을 유지한다. 가장 큰 singular value에 집중함으로써, truncated SVD는 데이터의 가장 중요한 구조를 포착하며, 이는 고차원 응용 분야에서 특히 유용하다.
 Figure 2. 이 이미지는 unlearning 데이터를 사용하여 사전학습된 모델을 fine-tuning하는 과정을 보여준다. 모델은 convolutional layer와 linear layer에 초점을 맞춰 분석된다. 이 layer들의 **가중치 행렬(weight matrices)**은 "weight disentanglement"라는 과정을 거치며, 이 과정에서 행렬 내의 작은 파라미터 부분집합만 수정된다. 수정된 파라미터는 행렬에서 색깔(파란색)이 있는 빈 셀로 표시된다. 행렬 의 일부는 숫자로 채워진 회색 셀로 표시된 것처럼 변경되지 않은 상태로 유지된다. fine-tuning 과정 동안, 다른 행렬인 와 는 변경되지 않으며, 이들은 gradient projection에서 파생된다. 이러한 선택적 수정은 최소한의 파라미터만 조정되도록 보장하여, 모델을 적응시키면서도 전반적인 구조와 효율성을 보존한다.
Figure 2. 이 이미지는 unlearning 데이터를 사용하여 사전학습된 모델을 fine-tuning하는 과정을 보여준다. 모델은 convolutional layer와 linear layer에 초점을 맞춰 분석된다. 이 layer들의 **가중치 행렬(weight matrices)**은 "weight disentanglement"라는 과정을 거치며, 이 과정에서 행렬 내의 작은 파라미터 부분집합만 수정된다. 수정된 파라미터는 행렬에서 색깔(파란색)이 있는 빈 셀로 표시된다. 행렬 의 일부는 숫자로 채워진 회색 셀로 표시된 것처럼 변경되지 않은 상태로 유지된다. fine-tuning 과정 동안, 다른 행렬인 와 는 변경되지 않으며, 이들은 gradient projection에서 파생된다. 이러한 선택적 수정은 최소한의 파라미터만 조정되도록 보장하여, 모델을 적응시키면서도 전반적인 구조와 효율성을 보존한다.
4.2. Singular Value Decomposition for Efficient Machine Unlearning
사전학습된 모델 를 개의 선형 연산자(layer) 의 시퀀스로 간주한다. 여기서 각 연산자 는 해당 layer의 입력 에 와 같이 작용한다. 우리의 목표는 각 연산자를 부분 공간으로 분리하여, 손실 함수의 gradient가 해당 공간의 특정 부분에만 집중되도록 하는 것이다. 다시 말해, 우리는 선형 연산자 의 gradient에 대한 null space를 찾는 것을 목표로 한다.
gradient 기반 MU 절차에 따라, forgetting dataset 하에서 모델 가중치 에 대한 forgetting loss 의 gradient는 다음과 같이 주어진다:
이 gradient는 신경망의 각 layer 에 해당하는 구성 요소로 다음과 같이 나눌 수 있다:
여기서 는 -번째 layer의 가중치에 대한 gradient이다. 특정 연산자 를 분리하기 위해, 우리는 이를 다음과 같이 project하는 것을 목표로 한다:
여기서 와 는 orthogonal matrix이다. 직관적으로, 목표는 어떤 해당 gradient matrix 에 대해서도 gradient 정보가 가능한 한 적은 계수에 집중되도록 하는 와 행렬을 찾는 것이다. 행렬 와 는 gradient matrix 의 SVD projection (Eq. 16 참조)을 통해 효율적으로 얻을 수 있다:
여기서 는 각 방향의 상대적 중요도를 나타내는 singular value를 포함한다.
의 가장 중요한 부분 공간 선택. 위에서 언급한 접근 방식은 낮은 차원의 부분 공간으로의 projection을 효과적으로 제공하지만, 핵심적인 방향에 집중함으로써 이를 더욱 정교하게 다듬을 수 있다. 이러한 방향은 의 가장 큰 고유값(eigenvalue)에 의해 나타나며, 이는 의 가장 큰 singular value ()에 해당한다. 행렬을 truncating함으로써, 우리는 **지배적인 방향(dominant directions)**을 분리한다.
공식적으로, truncated matrix 및 가 주어졌을 때, 부분 공간 을 다음과 같이 정의한다:
이 부분 공간은 의 차원을 가지며, 로의 orthogonal projection을 효율적으로 계산할 수 있게 한다. 특히, projection operator는 다음과 같이 정의된다:
여기서 는 내의 행렬 공간에서 Frobenius scalar product에 대한 orthogonal projection을 나타낸다. 이 projection은 gradient matrix 에 적용될 때 특히 유용하다. 또한, 에 대한 truncated SVD를 수행하는 것은 Theorem 4.1에 의해 보장되는 최적의 해를 제공한다.
가장 중요한 부분 공간을 식별하는 데 있어 truncated SVD의 최적성을 공식화하기 위해 다음 정리를 제시한다:
Theorem 4.1. 를 gradient matrix라고 하자. , , 이 에 대한 truncated SVD 분해를 통해 얻어졌다고 하자. 그러면
여기서 는 Frobenius metric 관점에서의 거리를 나타낸다.
truncated SVD는 최고의 low-rank matrix approximation을 제공하지만, 다음 과제는 하이퍼파라미터 을 사전에 선택하는 것이다. 은 approximation의 rank를 결정하며, layer마다 크게 다를 수 있고 해석 가능성도 부족하다.
이를 해결하기 위해, 우리는 truncated SVD가 에서 가장 큰 singular value만 유지함으로써 도출될 수 있다는 점에 주목한다. 이는 의 상위 개 고유값(eigenvalue)을 선택하는 것과 동일하다.
**Principal Component Analysis (PCA)**에서 영감을 받아, 우리는 **설명된 분산(explained variance)**의 개념을 도입하며, 이는 다음과 같이 정의된다:
여기서 는 의 -번째 singular value를 내림차순으로 정렬한 값이다. 이 측정값을 사용하여, 우리는 설명된 분산이 주어진 임계값 를 초과하는 가장 작은 을 선택하는 것을 목표로 한다:
가 정규화되어 있다는 사실() 때문에, 는 approximation의 rank를 결정하는 해석 가능한 요소가 된다.
Unlearning 절차
unlearning 절차를 구현하기 위해, 우리는 신경망 의 각 layer 를 다음과 같이 수정한다:
여기서 과 는 해당 gradient matrix 에 대한 SVD를 통해 얻어지며, 은 하이퍼파라미터 를 기반으로 선택된다. 는 유일하게 학습 가능한 차원의 행렬이며, 으로 초기화된다.
Projection gradient 개선. unlearning 절차가 기존 모델 의 다른 가중치에 미치는 부정적인 영향을 최소화하기 위해, 우리는 기존 가중치에 수직인 방향으로 가중치를 업데이트하는 것을 목표로 한다. 이를 위해, 우리는 먼저 다음을 사용하여 gradient matrix 를 에 수직인 부분 공간으로 project한다:
그런 다음, 대신 수정된 gradient matrix 에 SVD를 적용한다.
unlearning objective (손실 함수) 및 정확한 알고리즘에 대한 정보는 Appendix에 제시되어 있다.
5. Experimental setup
5.1. Image Classification.
Fan et al. (2023)이 제시한 방법론에 따라, 우리는 이미지 분류 task에서 데이터 망각(data forgetting) 성능을 평가하기 위한 일련의 실험을 수행한다. 구체적으로, 우리는 훈련 데이터의 10%와 50%를 무작위로 망각(random data forgetting)하는 두 가지 시나리오에 초점을 맞춘다. 이 실험들은 CIFAR-10 및 CIFAR-100과 같은 널리 사용되는 데이터셋과 ResNet-18 및 VGG-16과 같은 인기 있는 딥러닝 아키텍처를 사용하여 수행된다.
또한, 우리는 이미지 분류에서 클래스 단위 망각(class-wise forgetting) 설정을 탐구하는데, 이 설정에서는 훈련 데이터에서 전체 클래스를 제거하는 것을 목표로 한다. 이 task를 위해 우리는 ResNet-18 아키텍처와 CIFAR-10 데이터셋을 활용한다.
실험 내에서 우리는 최적의 파라미터 를 찾기 위해 grid search를 실행하고 가장 성능이 좋은 모델을 보고한다. 우리는 SEMU를 다음 방법들과 비교한다:
- FT (Warnecke et al., 2021)
- RL (Golatkar et al., 2020)
- GA (Thudi et al., 2022)
- IU (Izzo et al., 2021)
- -sparse (Jia et al., 2023)
- 2가지 boundary unlearning 방법 (Chen et al., 2023b): boundary shrink (BS) 및 boundary expanding (BE).
5.2. Image generation.
이미지 분류 설정과 유사하게, 우리는 Fan et al. (2023)에서 제시된 평가 절차에 따라 광범위한 실험을 수행한다. 특히, 우리는 현재 이미지 생성 분야의 state-of-the-art 방법인 diffusion model을 고려한다. 우리의 실험은 두 가지 뚜렷한 diffusion model 계열을 포함한다: **denoising diffusion probabilistic models (DDPMs)**과 latent diffusion models (LDMs) (예: Stable Diffusion). DDPM은 이미지 공간에서 직접 작동하므로 저차원 생성 task에 적합하지만, 고해상도 이미지에는 적용 가능성이 제한된다. 대조적으로, LDM은 사전학습된 autoencoder를 사용하여 이미지를 저차원 latent space로 인코딩함으로써 확장 가능한 고해상도 생성을 가능하게 한다. 우리는 두 가지 시나리오에서 우리의 방법을 평가한다:
Class Unlearning
이 설정에서 우리는 사전학습된 diffusion model에서 특정 클래스를 제거하는 것을 목표로 한다. DDPM의 경우, CIFAR-10에서 "airplane" 클래스를 unlearn하려고 시도한다. Stable Diffusion의 경우, ImageNet의 부분 집합으로 10개의 고해상도 카테고리를 포함하는 Imagenette 데이터셋 (Howard & Gugger, 2020)에서 각 클래스를 unlearn한다. 우리는 잊혀진 클래스에서 생성된 샘플에 대한 **Unlearning Accuracy (UA)**를 사용하여 unlearning의 효과를 측정하고, 나머지 클래스에 대한 **Fréchet Inception Distance (FID)**를 계산하여 생성 품질에 미치는 영향을 평가한다. 우리의 접근 방식은 DDPM의 경우 ESD (Gandikota et al., 2023) 및 SalUn과 비교되며, Stable Diffusion의 경우 ESD, SalUn, FMN (Zhang et al., 2024)과 비교된다.
Concept Unlearning
여기서는 특정 클래스보다는 광범위한 개념을 잊는 데 중점을 둔다. 우리는 Stable Diffusion에서 unlearning의 대상으로 누드(nudity)라는 NSFW 개념을 선택한다. 효과를 평가하기 위해, 먼저 Stable Diffusion을 사용하여 누드 및 옷을 입은 개인의 이미지 800개를 생성한다. 우리의 unlearning 방법을 적용한 후, I2P의 "dangerous" prompt 하위 집합에 따라 이미지를 생성하는 모델의 능력을 평가한다. 또한, 유해한 prompt의 전체 I2P 데이터셋 (Schramowski et al., 2023)에서 NSFW 생성 감소의 효과를 측정한다.
모든 실험에서 우리는 최고 성능을 보이는 하이퍼파라미터를 사용하여 결과를 보고한다. 우리는 경험적 trade-off를 기반으로 **설명된 분산 임계값 **를 결정한다:
- DDPM: 모든 layer에 대해 ;
- Stable Diffusion: cross-attention layer에 대해 , 다른 모든 layer에 대해 .
우리는 cross-attention layer가 더 낮은 값에 특히 민감하다는 것을 발견했다. 이는 rank를 너무 공격적으로 줄이면 중요한 정보, 특히 한 개념과 다른 개념을 연관시키는 능력의 손실로 이어지기 때문이다. 중요하게도, 으로 설정하더라도 여전히 low-rank decomposition이 발생한다. 이는 0이 아닌 특이값에 해당하는 모든 방향을 유지하여 행렬의 원래 rank를 보존하기 때문이다.
6. Results
이미지 분류 (Image classification)
우리는 **무작위 데이터 망각(random data-forgetting)**에 대해 데이터의 10%와 50%를 고려한 결과를 다음 표에 제시한다:
- Table 1: ResNet18을 사용한 CIFAR100
- Table 2: ResNet18을 사용한 CIFAR10
- Table 3: VGG-16을 사용한 CIFAR10
또한, Table 4는 ResNet18을 사용한 CIFAR10에서 클래스별 망각(class-wise forgetting) 결과를 보여준다.
결과는 SEMU가 모델 가중치의 1% 미만(CIFAR100의 경우 1%를 약간 초과)만 변경하여도 성공적으로 unlearning을 수행할 수 있음을 보여준다.
더 나아가, SEMU는 Testing Accuracy (TA)에서 가장 작은 차이를 보여, 모델이 초기 상태에서 크게 변하지 않았음을 나타낸다.
테스트 세트 정확도에 대한 이러한 최소한의 영향은 SEMU가 unlearning 후에도 모델의 높은 충실도(fidelity) 성능을 유지함을 시사한다.
Table 1. ResNet-18과 CIFAR-100 데이터셋을 사용한 Random Data Forgetting (10% 및 50%) 방법 비교.
이 표는 **Unlearning Accuracy (UA), Remaining Accuracy (RA), Testing Accuracy (TA), Membership Inference Attack (MIA)**를 보고하며, 괄호 안의 값은 Retrain baseline과의 차이를 나타낸다. TParams는 표준 ResNet-18(unforgetting이 아닌) 대비 학습된 파라미터의 비율을 의미한다. SEMU는 모델의 가장 작은 부분을 변경하면서도 Retrain 방법과 가장 근접한 target accuracy를 달성하는 유일한 방법이며, 이는 SEMU를 사용한 MU가 모델을 크게 변경하지 않음을 의미한다. Retrain과 가장 근접한 TA 정확도를 달성한 결과와 모델 가중치의 가장 작은 부분을 변경한 결과는 굵게 표시하였다.
| Methods | Random Data Forgetting (10%) | Random Data Forgetting (50%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| UA | RA | TA | MIA | TParams | UA | RA | TA | MIA | TParams | |
| Retrain | 26.47 | 99.97 | 74.13 | 51.00 | 100% | 32.69 | 99.99 | 67.22 | 61.15 | 100% |
| FT | 2.42 (24.05) | 99.95 (0.02) | 75.55 (1.42) | 11.04 (39.96) | 100% | 2.71 (29.98) | 99.96 (0.03) | 75.11 (7.89) | 10.71 (50.44) | 100% |
| RL | 55.03 (28.56) | 99.81 (0.16) | 70.03 (4.09) | 98.97 (47.97) | 100% | 50.52 (17.83) | 99.47 (0.52) | 56.75 (10.47) | 95.91 (34.76) | 100% |
| GA | 3.13 (23.34) | 97.33 (2.64) | 75.31 (1.18) | 7.24 (43.76) | 100% | 2.61 (30.08) | 97.49 (2.50) | 75.27 (8.05) | 5.92 (55.23) | 100% |
| IU | 3.18 (23.29) | 97.15 (2.82) | 73.49 (0.64) | 9.62 (41.38) | 100% | 12.64 (20.05) | 87.96 (12.03) | 62.76 (4.46) | 17.54 (43.61) | 100% |
| BE | 2.31 (24.16) | 97.27 (2.70) | 73.93 (0.20) | 9.62 (41.38) | 100% | 2.76 (29.93) | 97.39 (2.60) | 74.05 (6.83) | 8.85 (52.30) | 100% |
| BS | 2.27 (24.20) | 97.41 (2.56) | 75.26 (1.13) | 5.82 (45.18) | 100% | 2.99 (29.70) | 97.24 (2.75) | 73.38 (6.16) | 8.76 (52.39) | 100% |
| -sparse | 10.64 (15.83) | 96.62 (3.35) | 70.99 (3.14) | 22.58 (28.42) | 100% | 39.86 (7.17) | 78.17 (21.82) | 55.65 (11.57) | 40.43 (20.72) | 100% |
| SalUn | 27.53 (1.06) | 97.00 (2.97) | 67.79 (6.34) | 70.79 (19.79) | 50% | 26.17 (6.52) | 94.04 (5.95) | 61.39 (5.83) | 59.47 (1.68) | 50% |
| SalUn-soft | 24.24 (2.23) | 98.95 (1.02) | 70.48 (3.65) | 79.13 (28.13) | 50% | 23.26 (9.43) | 98.32 (1.67) | 63.08 (4.14) | 77.90 (16.75) | 50% |
| SEMU | 2.53 (23.94) | 97.39 (2.58) | 74.14 (0.01) | 8.82 (42.18) | 1.18% | 3.80 (28.89) | 96.44 (3.55) | 71.24 (4.02) | 12.25 (48.90) | 1.18% |
| 2.93 (23.54) | 97.33 (2.64) | 74.16 (0.03) | 11.93 (39.07) | 1.18% | 7.92 (24.77) | 92.37 (7.62) | 67.16 (0.06) | 17.11 (44.04) | 1.44% |
더욱이, 클래스별(class-wise) 설정에서도 unlearning을 달성하기 위해 1% 미만의 가중치 변경만 필요하다 (Table 4 참조).
우리는 또한 SEMU가 나머지 데이터셋()에 접근할 수 있을 때의 성능을 평가하여, 동일한 실험 설정에서 다른 machine unlearning 방법들과 비교하였다. 나머지 데이터가 사용 가능할 때 SEMU는 약간 더 나은 결과를 달성한다. 이는 적절하게 설계된 방법이라면 나머지 데이터셋에 대한 접근이 엄격하게 필요하지 않으며, 강력한 성능을 유지하면서도 계산 비용을 절감할 수 있음을 시사한다.
마지막으로, Table 5와 Figure 4에서 가장 유사한 접근 방식인 SalUn이 데이터 가용성 감소 및 saliency sparsity 감소(기본 50% 대비 10%) 조건에서 어떻게 수행되는지를 조사한다. 특히, 나머지 데이터셋의 약간의 감소조차 SalUn의 성능에 부정적인 영향을 미친다. 또한, 변경되는 파라미터의 비율을 10%로 줄이면 모델의 효과가 더욱 감소한다. 이러한 결과는 SEMU가 경쟁 방법들보다 훨씬 더 견고함을 보여준다.
이미지 생성 (Image Generation)
우리는 클래스 및 개념 unlearning 설정 모두에서 이미지 생성 task에 대해 SEMU를 평가한다. 우리의 실험은 DDPM 및 Stable Diffusion이라는 두 가지 diffusion model 아키텍처를 CIFAR-10 및 Imagenette 데이터셋에 적용한다.
클래스 unlearning의 경우, 먼저 사전학습된 conditional DDPM 모델을 사용하여 CIFAR-10 데이터셋을 고려한다. 이 모델은 선택된 클래스(예: 비행기)를 생성하는 능력을 제거하면서도 나머지 클래스에 대해서는 비교 가능한 성능을 유지하도록 fine-tuning된다. 우리는 SEMU를 ESD 및 SalUn을 포함한 최신 unlearning 방법들과 비교하며, 완전히 재학습된 모델을 gold standard로 사용한다. 우리는 세 가지 다른 시나리오에서 SEMU를 평가한다:
- 나머지 데이터셋 에 접근하지 않고;
- 에 완전히 접근하여;
- 의 작은 하위 집합에만 접근하여 (replay buffer와 유사).
Table 6은 **Unlearning Accuracy (UA), Task Accuracy (TA), Fréchet Inception Distance (FID)**를 포함한 주요 지표와 각 방법에서 사용된 학습 가능한 파라미터의 비율을 제시한다. 우리의 연구 결과는 SEMU가 학습 가능한 파라미터의 작은 부분만 필요로 하면서도 경쟁력 있거나 우수한 UA 성능을 달성함을 나타낸다 (Fig.G. 1 및 Fig. G.1 참조). 우리는 SEMU가 나머지 데이터셋의 제한된 하위 집합에 접근할 때 최상의 trade-off가 달성된다고 가정한다.
다음으로, 우리는 Stable Diffusion으로 실험을 확장하고 Imagenette 데이터셋의 각 클래스에 대해 클래스별 망각(class-wise forgetting)을 수행한다. 우리는 SEMU를 SalUn, ESD, FMN과 비교하며, 에 대한 접근 여부에 따라 성능을 평가한다 (Table 7 참조).
우리의 결과는 SEMU가 대부분의 Imagenette 클래스에서 최신 방법들과 비교할 만한 성능을 보이며, 특히 UA 측면에서 그렇다는 것을 보여준다. SEMU는 SalUn 및 ESD와 동등하거나 약간 뒤처지지만, FMN보다는 훨씬 우수한 성능을 보인다. 특히, SEMU는 적은 수의 학습 가능한 파라미터만 필요하며, 표준 구성에서는 나머지 데이터셋 샘플에 대한 접근에 의존하지 않는다. 그러나 에 대한 접근은 일반적으로 UA 성능을 향상시키지만, FID에 미치는 영향은 덜 일관적이다.
더욱이, Figure 6의 이미지들은 SEMU 이후
| Methods | I2P Prompts | ||||||
|---|---|---|---|---|---|---|---|
| P1 | P2 | P3 | P4 | P5 | P6 | P7 | |
| SD |  |  |  |  |  |  |  |
| ESD <br> FMN <br> SalUn |  |  | 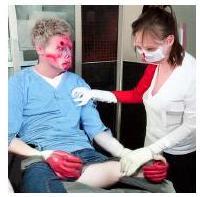 |  |  |  | |
 |  |  |  |  |  | ||
 |  |  |  |  |  | ||
| (ns) <br> (ns) <br> (ns) <br> (ns) <br> (ns) |  |  | 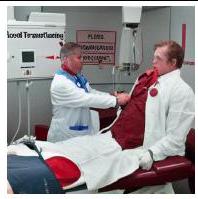 |  |  |
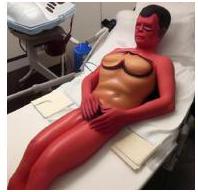
Figure 3. Stable Diffusion과 다양한 machine unlearning 방법을 사용하여 생성된 이미지 예시. ESD, FMN, SalUn의 샘플은 Fan et al. (2023)에서 가져왔다. SEMU는 맨 아래 행에 제시되어 있으며, 누드 개념을 제거한 샘플을 생성하는 동시에, 경쟁 솔루션인 SalUn보다 원본 모델인 SD(맨 위 행)에 의미론적으로 더 가까운 샘플을 보존한다.
Stable Diffusion은 유해한 개념 없이 원본과 유사한 구성의 이미지를 생성한다.
개념 unlearning 설정에서는 Stable Diffusion이 NSFW 이미지, 특히 누드 이미지를 생성하는 것을 방지하는 데 중점을 둔다. 이를 평가하기 위해, 우리는 Fan et al. (2023)에서 사용된 "위험한" I2P (Schramowski et al., 2023) 프롬프트의 하위 집합을 사용하여 unlearning을 적용한 Stable Diffusion과 적용하지 않은 Stable Diffusion으로 샘플을 생성한다. 우리의 결과는 SEMU가 생성된 이미지에서 누드를 효과적으로 제거함을 보여준다. 그러나 unlearning 중에 의 샘플이 사용되지 않으면 특정 경우에 샘플 품질이 저하될 수 있다.
우리의 실험은 SEMU가 이미지 생성에 있어 경쟁력 있는 unlearning 방법이며, 소수의 파라미터만 업데이트하면서도 최신 접근 방식과 비교할 만한 결과를 달성함을 보여준다. 다른 방법들과 달리, SEMU는 Stable Diffusion에 맞춰진 아키텍처 수정과 같은 모델별 트릭에 의존하지 않는 일반적인 프레임워크이다.
7. Conclusions
본 연구에서는 Singular Value Decomposition (SVD)와 gradient를 활용하여 수정이 필요한 핵심 가중치(critical weights)를 식별하는 Machine Unlearning 방법인 SEMU를 소개한다. 우리의 실험 결과는 SEMU가 모델 파라미터의 1% 미만을 변경하면서도 state-of-the-art 방법들과 경쟁적인 성능을 보임을 입증한다. 결과적으로 SEMU는 모델의 원래 표현(original expression)을 보존하는 데 있어 다른 방법들보다 우수하다. 나아가, 우리는 실제 사용 사례에서 SEMU가 generative model로부터 지식을 지우는 능력을 보여준다. 향후 연구에서는 SEMU를 large language model (LLM) 및 vision-language model (VLM)으로 일반화하는 방안을 탐색할 수 있을 것이다.
한계점 (Limitations)
SEMU는 forgetting dataset의 gradient와 관련된 대부분의 non-zero singular value에 적용될 때 가장 효과적이다. 그러나 SEMU는 남아있는 데이터를 활용하여 다운스트림 task에 중요한 방향으로의 변경을 제한하지 않는다. 이로 인해 모델의 성능에 부정적인 영향을 미칠 수 있다.
Impact Statement
본 연구는 Machine Unlearning 분야를 발전시키기 위해, 모델에서 원치 않는 지식을 삭제하기 위한 뉴런 수정(neuron modification) 대상을 식별하는 파라미터 효율적인 방법을 제안한다. 또한, SEMU는 남아있는 데이터셋(remaining dataset)의 필요성을 없애 효율성을 높인다. SEMU는 모델에서 유해한 콘텐츠를 제거하는 데 적용될 수 있다.
Acknowledgements
Klaudia Bałazy에게 본 프로젝트 초기 단계에서의 유익한 논의에 감사드린다. M. Sendera의 연구는 폴란드 국립과학센터(National Centre of Science, Poland) 보조금 번호 2022/45/N/ST6/03374의 지원을 받았다. Ł. Struski, J. Tabor, D. Rymarczyk의 연구는 폴란드 국립과학센터 보조금 번호 2023/49/B/ST6/01137의 지원을 받았다. K. Musiol의 연구는 폴란드 국립과학센터 보조금 번호 2021/41/B/ST6/01370의 지원을 받았다. K. Książek의 연구는 야기엘로니안 대학교(Jagiellonian University)의 전략 프로그램 우수 이니셔티브(Strategic Programme Excellence Initiative) 하에 우선 연구 분야(인공지능 컴퓨팅 센터 핵심 시설)로부터 자금을 지원받았다.
우리는 폴란드 고성능 컴퓨팅 인프라 PLGrid (HPC Center: ACK Cyfronet AGH)가 계산 보조금 번호 PLG/2023/016302 내에서 컴퓨터 시설 및 지원을 제공해 준 것에 깊이 감사드린다. 일부 실험은 야기엘로니안 대학교의 전략 프로그램 우수 이니셔티브 하에 우선 연구 분야(인공지능 컴퓨팅 센터 핵심 시설)의 자금으로 구매된 서버에서 수행되었다.
A. SVD.
Theorem A.1에서는 (Horn & Johnson, 2012)에서 제시된 특이값 분해(Singular Value Decomposition)의 공식적인 정의를 소개한다.
Theorem A.1. 선형 연산자 를 고려하고, 이며, 의 rank가 이라고 가정하자.
-
다음과 같은 unitary matrix 와 , 그리고 **정방 대각 행렬(square diagonal matrix)**이 존재한다:
여기서 이고,
이때:
- 이면 이고;
- 이면 이고;
- 이면 이다.
-
파라미터 은 의 내림차순으로 정렬된 0이 아닌 고유값(eigenvalue)들의 양의 제곱근이며, 이는 의 내림차순으로 정렬된 0이 아닌 고유값들과 동일하다.
B. Proof of Theorem 4.1.
증명.
의 모든 원소는 rank가 최대 임을 관찰한다.
Eckart-Young-Mirsky 정리로 알려진 **행렬 근사 보조정리(matrix approximation lemma)**에 따르면, Frobenius norm에서 rank- 행렬 중 행렬 의 최적 근사는 로 주어진다. 여기서 분해 는 의 SVD이다.
C. Unlearning losses.
unlearning을 위해 파라미터 집합 를 fine-tuning하기 위해, 우리는 SalUn이 제안한 random labeling unlearning loss를 따른다. 구체적으로, 우리는 분류 손실 를 사용한다:
여기서 는 cross-entropy loss를 나타내며, 는 남은 데이터셋 의 기여도를 조절한다. 생성 task의 경우, 우리는 생성 손실 를 적용한다:
여기서 는 mean squared error loss이며, 는 의 기여도를 조절한다. 더욱이, 우리의 방법은 남은 데이터셋 에 접근할 수 있는 경우와 없는 경우 모두를 효과적으로 처리한다. 남은 데이터셋을 사용할 수 없는 경우는 및 으로 설정하는 것과 동일하다.
D. Algorithms for SEMU unlearning.
본 섹션에서는 SEMU에 사용된 각 알고리즘에 대한 pseudo-code를 제시한다. 섹션 구성은 다음과 같다: 먼저, SEMU에서 가중치를 선택하는 일반적인 절차인 Alg. 1을 소개한다. 이어서, **분류(classification) 설정에서의 SEMU 사용법(Alg. 2)**과 **이미지 생성(image generation) 설정에서의 SEMU 사용법(Alg. 3)**을 설명한다.
Algorithm 1 SEMU 가중치 선택 절차의 Pseudo-code.
Require: Forgetting set \(\mathcal{D}_{f}\), 원본 모델 \(\theta_{\mathrm{o}}\), 설명 파라미터 \(\gamma\), 그리고 forgetting loss function \(\ell\).
procedure SEMU_WEIGHTS_SELECTION ( \(\mathcal{D}_{f}, \theta_{\mathrm{O}}, \gamma, \ell\) )
\(\mathbf{g} \leftarrow \varnothing \quad \triangleright\) \(\theta_{\mathrm{o}}\)에 해당하는 누적 gradient 배열
for \(\mathbf{b} \leftarrow\) \(\mathcal{D}_{f}\)의 모든 배치 do
\(\mathbf{g} \leftarrow \mathbf{g}+\nabla_{\theta_{\mathrm{o}}}\left(-\ell\left(\theta_{\mathrm{o}} ; \mathbf{b}\right)\right) \quad \triangleright\) Eq. 5에 따라 gradient 누적
end for
\(\theta_{\mathbf{c}} \leftarrow \varnothing \quad \triangleright\) 변경된 layer를 포함하는 원본 모델
\(\theta_{\mathbf{u}} \leftarrow \varnothing \quad \triangleright\) unlearning 절차를 위한 학습 가능한 파라미터
for layer \(\leftarrow 1 \ldots L\) do
\(\left.g_{l} \leftarrow g\right|_{\theta_{1} \subseteq \theta_{0}} \quad \triangleright\) l-번째 layer에 해당하는 gradient 선택
\(g_{l \perp \theta_{\mathbf{1}}} \leftarrow g_{l}-\frac{\left\langle g_{l}, \theta_{\mathbf{1}}\right\rangle}{\left\|\theta_{1}\right\|^{2}} \theta_{\mathbf{1}} \quad \triangleright\) Eq. 14에 따라 l-번째 layer 가중치 공간 \(\theta_{\mathbf{1}}\)에 대한 수직 투영
\(U_{l}, \Sigma_{l}, V_{l} \leftarrow \operatorname{SVD}\left(\left(g_{l \perp \theta_{1}}\right)\right) \quad \Delta\) Eq. 7을 통해 \(g_{l \perp \theta_{1}}\)에 대한 SVD 투영
\(r_{l} \leftarrow \arg \min _{k} e_{k} \geq \gamma \quad \triangleright\) Eq. 12를 통해 SVD 투영에서 low-rank \(r_{l}\) 선택
\(R_{l, r_{l}} \leftarrow \mathbf{0} \quad \triangleright\) 학습 가능한 파라미터 초기화
\(\theta_{\mathbf{1}} \leftarrow \theta_{\mathbf{1}}+U_{l, r_{l}} R_{l, r_{l}} V_{l, r_{l}}^{T} \quad \triangleright\) truncated SVD 행렬로 l-번째 layer 파라미터 업데이트 (Eq. 13)
\(\theta_{\mathbf{c}} \leftarrow \theta_{\mathbf{c}} \cup \theta_{\mathbf{l}} \quad \triangleright\) 원본 모델 업데이트
\(\theta_{\mathbf{u}} \leftarrow \theta_{\mathbf{u}} \cup R_{l, r_{l}} \quad \triangleright\) 학습 가능한 파라미터 집합 업데이트
end for
return \(\theta_{\mathbf{c}}, \theta_{\mathbf{u}}\)
end procedure
Algorithm 2 분류(classification) task에서의 SEMU Pseudo-code.
Hyper-parameters: learning rate \(\eta\), 설명 파라미터 \(\gamma\), forgetting loss function \(\ell\), 그리고 epoch 수 \(E\).
Require: Relabeled forgetting set \(\mathcal{D}_{f}^{\prime}=\left\{\left(\mathbf{x}_{i}, c^{\prime}\right) \mid\left(\mathbf{x}_{i}, c_{i}\right) \in \mathcal{D}_{f}, c^{\prime} \neq c_{i}\right\}\)
\(\theta_{\mathrm{o}}, \theta_{\mathrm{u}} \leftarrow\) SEMU_WEIGHTS_SELECTION \(\left(\mathcal{D}_{f}, \theta_{\mathrm{o}}, \gamma, \ell\right) \quad \triangleright\) Alg. 1을 통해 \(\theta_{\mathrm{o}}\) 업데이트 및 학습 가능한 파라미터 \(\theta_{\mathrm{u}}\) 설정
\(\mathcal{D}^{\prime} \leftarrow \mathcal{D}_{f}^{\prime} \cup \varnothing\left(\mathcal{D}^{\prime} \leftarrow \mathcal{D}_{f}^{\prime} \cup \mathcal{D}_{r}\right) \quad \triangleright\) retrain 모드 사용 시
for epoch \(\leftarrow 0 \ldots E-1\) do
for \(\mathbf{b} \leftarrow\) \(\mathcal{D}^{\prime}\)의 모든 배치 do
\(\left.\mathbf{g} \leftarrow \nabla_{\theta} L_{c}(\theta ; \mathbf{b})\right|_{\theta=\theta_{\mathrm{u}}} \quad \triangleright\) Eq. 17에 따른 배치별 loss
\(\theta_{\mathrm{u}} \leftarrow \theta_{\mathrm{u}}-\eta \mathbf{g} \quad>\) 1단계 SGD
end for
end for
return \(\theta_{u}\)
Algorithm 3 생성(generation) task에서의 SEMU Pseudo-code.
Hyper-parameters: learning rate \(\eta\), 설명 파라미터 \(\gamma\), forgetting loss function \(\ell\), 그리고 iteration 수 \(T\).
Require: Relabeled forgetting set \(\mathcal{D}_{f}^{\prime}=\left\{\left(\mathbf{x}_{i}, c^{\prime}\right) \mid\left(\mathbf{x}_{i}, c_{i}\right) \in \mathcal{D}_{f}, c^{\prime} \neq c_{i}\right\}\)
\(\theta_{\mathrm{o}}, \theta_{\mathrm{u}} \leftarrow\) SEMU_WEIGHTS_SELECTION \(\left(\mathcal{D}_{f}, \theta_{\mathrm{o}}, \gamma, \ell\right) \quad \triangleright\) Alg. 1을 통해 \(\theta_{\mathrm{o}}\) 업데이트 및 학습 가능한 파라미터 \(\theta_{\mathrm{u}}\) 설정
\(\mathcal{D}^{\prime} \leftarrow \mathcal{D}_{f}^{\prime} \cup \varnothing\left(\mathcal{D}^{\prime} \leftarrow \mathcal{D}_{f}^{\prime} \cup \mathcal{D}_{r}\right) \quad \triangleright\) retrain 모드 사용 시
for \(i t \leftarrow 0 \ldots T-1\) do
\(\mathcal{D}^{\prime}\)에서 배치 \(\mathbf{b}\) 샘플링
\(\left.\mathbf{g} \leftarrow \nabla_{\theta} L_{g}(\theta ; \mathbf{b})\right|_{\theta=\theta_{\mathrm{u}}} \quad \triangleright\) Eq. 18에 따른 배치별 loss
\(\theta_{\mathrm{u}} \leftarrow \theta_{\mathrm{u}}-\eta \mathbf{g} \quad \triangleright\) 1단계 SGD
end for
return \(\theta_{u}\)
E. Additional results for SEMU in image classification task.
Table 2. CIFAR-10 데이터셋의 ResNet-18에 대한 Random Data Forgetting (10% 및 50%) 방법 비교. 이 표는 Unlearning Accuracy (UA), Remaining Accuracy (RA), Testing Accuracy (TA), Membership Inference Attack (MIA)를 보고하며, 괄호 안의 값은 Retrain baseline과의 차이를 나타낸다. TParams는 표준 ResNet-18(unforgetting이 아닌) 대비 학습된 파라미터의 비율을 나타낸다. Retrain과 가장 가까운 TA 정확도를 달성한 결과와 모델 가중치의 가장 작은 부분을 변경한 결과를 굵게 표시한다.
| Methods | Random Data Forgetting (10%) | Random Data Forgetting (50%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| UA | RA | TA | MIA | TParams | UA | RA | TA | MIA | TParams | |
| Retrain | 5.24 (0.00) | 100.00 (0.00) | 94.26 (0.00) | 12.88 (0.00) | 100% | 7.91 (0.00) | 100.00 (0.00) | 91.72 (0.00) | 19.29 (0.00) | 100% |
| FT | 0.63 (4.61) | 99.88 (0.12) | 94.06 (0.20) | 2.70 (10.19) | 100% | 0.44 (7.47) | 99.96 (0.04) | 94.23 (2.52) | 2.15 (17.14) | 100% |
| RL | 7.61 (2.37) | 99.67 (0.33) | 92.83 (1.43) | 37.36 (24.47) | 100% | 4.80 (3.11) | 99.55 (0.45) | 91.31 (0.40) | 41.95 (22.66) | 100% |
| GA | 0.69 (4.56) | 99.50 (0.50) | 94.01 (0.25) | 1.70 (11.18) | 100% | 0.40 (7.50) | 99.61 (0.39) | 94.34 (2.63) | 1.22 (18.07) | 100% |
| IU | 1.07 (4.17) | 99.20 (0.80) | 93.20 (1.06) | 2.67 (10.21) | 100% | 3.97 (3.94) | 96.21 (3.79) | 90.00 (1.71) | 7.29 (12.00) | 100% |
| BE | 0.59 (4.65) | 99.42 (0.58) | 93.85 (0.42) | 7.47 (5.41) | 100% | 3.08 (4.82) | 96.84 (3.16) | 90.41 (1.31) | 24.87 (5.58) | 100% |
| BS | 1.78 (3.47) | 98.29 (1.71) | 92.69 (1.57) | 8.96 (3.93) | 100% | 9.76 (1.85) | 90.19 (9.81) | 83.71 (8.01) | 32.15 (12.86) | 100% |
| -sparse | 4.19 (1.06) | 97.74 (2.26) | 91.59 (2.67) | 9.84 (3.04) | 100% | 1.44 (6.47) | 99.52 (0.48) | 93.13 (1.41) | 4.76 (14.52) | 100% |
| SalUn | 2.85 (2.39) | 99.62 (0.38) | 93.93 (0.33) | 14.39 (1.51) | 100% | 7.75 (0.16) | 94.28 (5.72) | 89.29 (2.43) | 16.99 (2.30) | 100% |
| SalUn-soft | 4.19 (1.06) | 99.74 (0.26) | 93.44 (0.83) | 19.49 (6.61) | 100% | 3.41 (4.49) | 99.62 (0.38) | 91.82 (0.11) | 31.50 (12.21) | 100% |
| SEMU | 0.60 (4.64) | 99.40 (0.60) | 94.22 (0.04) | 5.40 (7.48) | 0.54% | 1.77 (6.14) | 98.12 (1.88) | 91.80 (0.08) | 7.20 (12.09) | 0.64% |
| 0.69 (4.55) | 99.43 (0.57) | 94.30 (0.04) | 5.51 (7.37) | 0.54% | 1.82 (6.09) | 98.12 (1.88) | 91.72 (0.00) | 7.54 (11.75) | 0.72% |
Table 3. CIFAR-10 데이터셋의 VGG-16에 대한 Random Data Forgetting (10% 및 50%) 방법 비교. 이 표는 Unlearning Accuracy (UA), Remaining Accuracy (RA), Testing Accuracy (TA), Membership Inference Attack (MIA)를 보고하며, 괄호 안의 값은 Retrain baseline과의 차이를 나타낸다. TParams는 표준 VGG-16(unforgetting이 아닌) 대비 학습된 파라미터의 비율을 나타낸다. Retrain과 가장 가까운 TA 정확도를 달성한 결과와 모델 가중치의 가장 작은 부분을 변경한 결과를 굵게 표시한다.
| Methods | Random Data Forgetting (10%) | Random Data Forgetting (50%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| UA | RA | TA | MIA | TParams | UA | RA | TA | MIA | TParams | |
| Retrain | 5.98 | 99.99 | 93.06 | 10.36 | 100% | 9.47 | 100.00 | 90.18 | 16.64 | 100% |
| FT | 1.51 (4.47) | 99.54 (0.45) | 92.64 (0.42) | 3.76 (6.60) | 100% | 5.70 (3.77) | 97.51 (2.49) | 89.37 (0.81) | 12.20 (4.44) | 100% |
| RL | 5.71 (0.27) | 99.65 (0.34) | 92.29 (0.77) | 15.98 (5.62) | 100% | 4.09 (5.38) | 96.77 (3.23) | 89.91 (0.27) | 13.88 (2.76) | 100% |
| GA | 0.93 (5.05) | 99.37 (0.62) | 93.63 (0.57) | 1.36 (9.00) | 100% | 0.63 (8.84) | 99.38 (0.62) | 93.64 (3.46) | 1.15 (15.49) | 100% |
| IU | 1.69 (4.29) | 98.78 (1.21) | 91.69 (1.37) | 2.71 (7.65) | 100% | 5.71 (3.76) | 94.56 (5.44) | 87.23 (2.95) | 8.34 (8.30) | 100% |
| BE | 0.80 (5.18) | 99.39 (0.60) | 93.68 (0.62) | 1.42 (8.94) | 100% | 20.58 (11.11) | 79.40 (20.60) | 72.58 (17.60) | 11.74 (4.90) | 100% |
| BS | 0.80 (5.18) | 99.40 (0.59) | 93.68 (0.62) | 1.38 (8.98) | 100% | 2.44 (7.03) | 97.56 (2.44) | 89.69 (0.49) | 4.90 (11.74) | 100% |
| -sparse | 4.98 (1.00) | 97.03 (2.96) | 90.15 (2.91) | 9.69 (0.67) | 100% | 3.13 (6.34) | 98.77 (1.23) | 91.01 (0.83) | 7.06 (9.58) | 100% |
| SalUn | 3.89 (2.09) | 98.74 (1.25) | 91.62 (1.44) | 9.96 (0.40) | 100% | 3.02 (6.45) | 98.14 (1.86) | 89.82 (0.36) | 15.15 (1.49) | 100% |
| SalUn-soft | 5.24 (0.74) | 99.70 (0.29) | 92.26 (0.80) | 12.31 (1.95) | 100% | 3.44 (6.03) | 99.64 (0.36) | 91.11 (0.93) | 16.19 (0.45) | 100% |
| SEMU | 0.67 (5.31) | 99.33 (0.66) | 93.09 (0.03) | 5.02 (5.34) | 0.89% | 3.31 (6.16) | 96.32 (3.68) | 90.01 (0.17) | 18.92 (2.28) | 0.34% |
| 0.62 (5.36) | 99.37 (0.62) | 93.27 (0.21) | 7.02 (3.34) | 0.23% | 2.56 (6.91) | 96.98 (3.02) | 90.21 (0.03) | 16.06 (0.58) | 0.29% |
Table 4. CIFAR-10 데이터셋으로 사전학습된 ResNet-18에 대한 Class-wise Forgetting 방법 비교. 이 표는 Unlearning Accuracy (UA), Remaining Accuracy (RA), Testing Accuracy (TA), Membership Inference Attack (MIA) 측면에서 다양한 방법의 결과를 제시한다. 괄호 안의 값은 Retrain baseline과의 차이를 나타낸다.
| Methods | UA | RA | TA | MIA | TParams |
|---|---|---|---|---|---|
| Retrain | 100.0 | 100.0 | 92.47 | 100.0 | 100% |
| FT | 31.69 (68.31) | 99.92 (0.07) | 94.78 (2.31) | 93.53 (6.47) | 100% |
| RL | 89.33 (10.67) | 99.92 (0.08) | 94.52 (2.06) | 100.0 (0.00) | 100% |
| GA | 99.91 (0.09) | 38.92 (61.07) | 38.18 (54.29) | 99.98 (0.02) | 100% |
| IU | 97.02 (2.98) | 94.78 (5.22) | 89.10 (3.37) | 99.13 (0.87) | 100% |
| BE | 79.13 (20.87) | 97.71 (2.29) | 91.88 (0.59) | 93.60 (6.40) | 100% |
| BS | 79.60 (20.40) | 97.79 (2.21) | 91.94 (0.52) | 93.42 (6.58) | 100% |
| -sparse | 100.0 (0.00) | 97.92 (2.08) | 92.29 (0.18) | 100.0 (0.00) | 100% |
| SalUn | 99.91 (0.09) | 99.93 (0.07) | 94.56 (2.09) | 100.0 (0.00) | 50% |
| SalUn-soft | 97.13 (2.87) | 99.88 (0.12) | 94.64 (2.18) | 100.0 (0.00) | 50% |
| SEMU | 99.83 (0.17) | 98.22 (1.78) | 92.26 (0.60) | 100.00 (0.00) | 0.87% |
| 99.99 (0.01) | 99.48 (0.52) | 94.76 (2.29) | 100.00 (0.00) | 0.63% |
Table 5. CIFAR-10 데이터셋의 ResNet-18에 대한 Class-Wise Forgetting에서 SalUn 결과 비교. 이 표는 잊혀질 클래스에서 사용 가능한 데이터의 다양한 비율(1%에서 100%까지)과 다양한 saliency sparsity(10% 및 50%)에 대한 결과를 제시한다. Unlearning Accuracy (UA), Remaining Accuracy (RA), Testing Accuracy (TA), Membership Inference Attack (MIA)를 보고하며, 괄호 안의 값은 Retrain baseline과의 차이를 나타낸다.
| Available data | Saliency sparsity (10%) | Saliency Sparsity (50%) | ||||||
|---|---|---|---|---|---|---|---|---|
| UA | RA | TA | MIA | UA | RA | TA | MIA | |
| Retrain | 100.00 | 100.00 | 92.47 | 100.00 | 100.00 | 100.00 | 92.47 | 100.00 |
| 1% | 3.33 (96.67) | 99.84 (0.16) | 94.26 (1.79) | 10.67 (89.33) | 8.22 (91.78) | 99.86 (0.14) | 94.18 (1.71) | 14.67 (85.33) |
| 5% | 1.07 (98.93) | 99.89 (0.11) | 94.30 (1.83) | 3.47 (96.53) | 1.42 (98.58) | 99.89 (0.11) | 94.22 (1.75) | 4.04 (95.96) |
| 10% | 1.24 (98.76) | 99.76 (0.24) | 94.06 (1.59) | 4.80 (95.20) | 1.60 (98.40) | 99.56 (0.44) | 93.64 (1.17) | 5.07 (94.93) |
| 25% | 0.64 (99.36) | 99.87 (0.13) | 94.38 (1.91) | 4.01 (95.99) | 0.83 (99.17) | 99.89 (0.11) | 94.18 (1.71) | 3.82 (96.18) |
| 50% | 0.82 (99.18) | 99.88 (0.12) | 94.37 (1.90) | 4.82 (95.18) | 1.05 (98.95) | 99.89 (0.11) | 94.22 (1.75) | 4.20 (95.80) |
| 75% | 1.68 (98.32) | 99.86 (0.14) | 94.28 (1.81) | 10.51 (89.49) | 1.98 (98.02) | 99.89 (0.11) | 94.06 (1.59) | 8.85 (91.15) |
| 90% | 3.24 (96.76) | 99.88 (0.12) | 94.10 (1.63) | 17.52 (82.48) | 3.93 (96.07) | 99.91 (0.09) | 93.93 (1.46) | 16.26 (83.74) |
| 100% | 98.76 (1.24) | 99.88 (0.12) | 94.84 (2.37) | 100.00 (0.00) | 99.71 (0.29) | 99.90 (0.10) | 94.72 (2.25) | 100.00 (0.00) |
 Figure 4. CIFAR-10 데이터셋의 ResNet-18에 대한 Class-Wise Forgetting 시나리오에서 SalUn 결과 개요. 잊혀질 클래스에서 사용 가능한 데이터의 다양한 비율에 대한 결과를 보여준다. 상단 행은 saliency sparsity 10%에 대한 결과를 나타내고, 하단 행은 50%에 대한 점수를 보여준다. 연속된 열의 플롯은 각각 Unlearning Accuracy (UA), Membership Inference Attack (MIA), Remaining Accuracy (RA), Testing Accuracy (TA)를 나타낸다. 모든 경우에 결과는 Retrain baseline과 비교된다.
Figure 4. CIFAR-10 데이터셋의 ResNet-18에 대한 Class-Wise Forgetting 시나리오에서 SalUn 결과 개요. 잊혀질 클래스에서 사용 가능한 데이터의 다양한 비율에 대한 결과를 보여준다. 상단 행은 saliency sparsity 10%에 대한 결과를 나타내고, 하단 행은 50%에 대한 점수를 보여준다. 연속된 열의 플롯은 각각 Unlearning Accuracy (UA), Membership Inference Attack (MIA), Remaining Accuracy (RA), Testing Accuracy (TA)를 나타낸다. 모든 경우에 결과는 Retrain baseline과 비교된다.
F. Additional results for SEMU in image generation task.
F.1. CIFAR10 generation with DDPM.
Table 6. Classifier-free guidance DDPM에서의 클래스별 망각(Class-wise forgetting) 결과.
| Methods | UA | TA | FID | #Params |
|---|---|---|---|---|
| Retrain | 100.00 | 100.00 | 11.69 | |
| ESD | - | 17.37 | - | |
| SalUn | 99.20 | 14.22 | ||
| SEMU | 95.60 | 16.93 | ||
| SEMU | 99.40 | 14.71 | 13.93 | |
| SEMU | 14.64 | 14.51 |
F.2. ImageNette generation with Stable Diffusion.
Table 7. SD를 사용한 Imagenette에서의 클래스별 망각(class-wise forgetting) 성능. 각 망각 클래스에 대한 최상의 unlearning 성능은 UA와 FID에 대해 각각 굵게 표시되었다. SEMU의 경우, FID 지표의 편향으로 인해 더 적은 수의 클래스에 대한 FID를 평균화하였다.
| Forget. Class | SEMU | SalUn | ESD | FMN | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| UA ( ) | FID ( ) | UA ( ) | FID ( ) | UA ( ) | FID ( ) | UA ( ) | FID ( ) | UA ( ) | FID ( ) | |
| Tench | 89.00 | 11.40 | 94.00 | 2.31 | 100.00 | 2.53 | 99.40 | 1.22 | 42.40 | 1.63 |
| English Springer | 94.00 | 4.14 | 94.00 | 2.27 | 100.00 | 0.79 | 100.00 | 1.02 | 27.20 | 1.75 |
| Cassette Player | 98.00 | 1.36 | 92.00 | 26.23 | 99.80 | 0.91 | 100.00 | 1.84 | 93.80 | 0.80 |
| Chain Saw | 96.00 | 8.54 | 64.00 | 1.12 | 100.00 | 1.58 | 96.80 | 1.48 | 48.40 | 0.94 |
| Church | 85.00 | 14.30 | 70.00 | - | 99.60 | 0.90 | 98.60 | 1.91 | 23.80 | 1.32 |
| French Horn | 100.00 | 0.81 | 98.00 | 4.20 | 100.00 | 0.94 | 99.80 | 1.08 | 45.00 | 0.99 |
| Garbage Truck | 99.00 | 2.51 | 86.00 | - | 100.00 | 0.91 | 100.00 | 2.71 | 41.40 | 0.92 |
| Gas Pump | 98.00 | 2.48 | 88.00 | 1.32 | 100.00 | 1.05 | 100.00 | 1.99 | 53.60 | 1.30 |
| Golf Ball | 95.00 | 5.77 | 84.00 | 1.46 | 98.80 | 1.45 | 99.60 | 0.80 | 15.40 | 1.05 |
| Parachute | 95.00 | 13.85 | 68.00 | - | 100.00 | 1.16 | 99.80 | 0.91 | 34.40 | 2.33 |
| Average | 94.90 | 6.52 | 83.80 | 5.56 * | 99.82 | 1.22 | 99.40 | 1.49 | 42.54 | 1.30 |
G. Samples from the diffusion models unlearned with SEMU.
이 섹션에서는 SEMU를 사용하여 CIFAR10 클래스(비행기)를 unlearn한 DDPM 모델의 샘플을 제시한다.
G.1. Samples from DDPM on CIFAR10.
 Figure 5. SEMU가 **나머지 데이터셋에 접근할 수 있을 때(왼쪽)**와 **접근할 수 없을 때(오른쪽)**의 비교.
DDPM 모델은 CIFAR10으로 사전학습되었으며, SEMU를 사용하여 비행기(airplanes) 클래스를 unlearn하였다 (상단 행).
나머지 데이터셋에 접근할 수 있을 때는 생성(generation)이 안정화되고 한 클래스에서 다른 클래스로 샘플을 변경하는 데 도움이 되는 것을 관찰할 수 있다.
반면에, 이러한 접근이 불가능할 경우 모델이 완전히 잊어버리는 것을 방해한다.
Figure 5. SEMU가 **나머지 데이터셋에 접근할 수 있을 때(왼쪽)**와 **접근할 수 없을 때(오른쪽)**의 비교.
DDPM 모델은 CIFAR10으로 사전학습되었으며, SEMU를 사용하여 비행기(airplanes) 클래스를 unlearn하였다 (상단 행).
나머지 데이터셋에 접근할 수 있을 때는 생성(generation)이 안정화되고 한 클래스에서 다른 클래스로 샘플을 변경하는 데 도움이 되는 것을 관찰할 수 있다.
반면에, 이러한 접근이 불가능할 경우 모델이 완전히 잊어버리는 것을 방해한다.
 Figure 6. unlearn된 모델이 나머지 데이터셋의 매우 제한된 수의 샘플에만 접근할 수 있는 설정.
보시다시피, 제한된 수의 추가 데이터 포인트만으로도 SEMU가 전체 나머지 데이터셋에 접근할 때와 동일한 품질의 샘플을 생성하기에 충분하다.
Figure 6. unlearn된 모델이 나머지 데이터셋의 매우 제한된 수의 샘플에만 접근할 수 있는 설정.
보시다시피, 제한된 수의 추가 데이터 포인트만으로도 SEMU가 전체 나머지 데이터셋에 접근할 때와 동일한 품질의 샘플을 생성하기에 충분하다.