Switch Transformers: 단순하고 효율적인 희소성을 통한 1조 파라미터 모델 확장
Switch Transformer는 기존의 Mixture of Experts (MoE) 모델을 단순화하여, 각 입력을 단 하나의 expert로 라우팅하는 희소 활성화(sparsely-activated) 모델입니다. 이 접근법은 MoE의 복잡성, 통신 비용, 훈련 불안정성 문제를 해결하면서, 동일한 계산 리소스 내에서 파라미터 수를 극대화합니다. 그 결과, T5-Base 모델 대비 최대 7배의 사전 훈련 속도 향상을 보였으며, bfloat16과 같은 저정밀도 형식에서도 안정적인 훈련이 가능함을 입증했습니다. 본 논문은 이러한 혁신을 통해 최대 1조 개의 파라미터를 가진 언어 모델을 성공적으로 훈련시키고, 다양한 자연어 처리 과제에서 그 효율성과 성능을 입증합니다. 논문 제목: Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Fedus, William, Barret Zoph, and Noam Shazeer. "Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity." Journal of Machine Learning Research 23.120 (2022): 1-39.
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
William Fedus*<br>LIAMFEDUS@GOOGLE.COM<br>Barret Zoph*<br>BARRETZOPH@GOOGLE.COM<br>Noam Shazeer<br>NOAM@GOOGLE.COM<br>Google, Mountain View, CA 94043, USA
Editor: Alexander Clark
Abstract
딥러닝에서 모델은 일반적으로 모든 입력에 대해 동일한 파라미터를 재사용한다. 하지만 Mixture of Experts (MoE) 모델은 이러한 방식을 따르지 않고, 들어오는 각 예시(example)에 대해 다른 파라미터를 선택한다. 그 결과, 엄청난 수의 파라미터를 가지면서도 일정한 연산 비용을 유지하는 sparsely-activated 모델이 탄생한다. 그러나 MoE 모델은 몇몇 주목할 만한 성공에도 불구하고, 복잡성, 통신 비용, 학습 불안정성으로 인해 광범위한 채택이 어려웠다.
우리는 Switch Transformer를 도입하여 이러한 문제들을 해결한다. 우리는 MoE 라우팅 알고리즘을 단순화하고, 통신 및 연산 비용을 줄인 직관적이고 개선된 모델을 설계한다. 우리가 제안하는 학습 기법은 불안정성을 완화하며, 최초로 낮은 정밀도(bfloat16) 형식으로 대규모 sparse 모델을 학습할 수 있음을 보여준다.
우리는 T5-Base 및 T5-Large (Raffel et al., 2019)를 기반으로 모델을 설계하여, 동일한 연산 자원으로 사전학습 속도를 최대 7배까지 향상시킨다. 이러한 개선은 다국어 설정으로도 확장되어, 101개 언어 전체에서 mT5-Base 버전 대비 성능 향상을 측정한다. 마지막으로, 우리는 "Colossal Clean Crawled Corpus"에서 최대 1조 개의 파라미터를 가진 모델을 사전학습하여 언어 모델의 현재 규모를 확장하고, T5-XXL 모델 대비 4배의 속도 향상을 달성한다.
Keywords: mixture-of-experts, natural language processing, sparsity, large-scale machine learning, distributed computing
1. Introduction
대규모 학습은 유연하고 강력한 신경 언어 모델을 구축하는 효과적인 방법으로 입증되었다 (Radford et al., 2018; Kaplan et al., 2020; Brown et al., 2020). 충분한 연산 예산, 데이터셋 크기, 파라미터 수를 기반으로 하는 단순한 아키텍처는 더 복잡한 알고리즘을 능가한다 (Sutton, 2019). Radford et al. (2018); Raffel et al. (2019); Brown et al. (2020)에서 따르는 접근 방식은 densely-activated Transformer (Vaswani et al., 2017)의 모델 크기를 확장한다. 이는 효과적이지만, 연산 집약적이기도 하다 (Strubell et al., 2019). 우리는 모델 규모의 성공에 영감을 받았지만, 더 큰 연산 효율성을 추구하여, 대신 sparsely-activated expert model인 Switch Transformer를 제안한다. 우리의 경우, 희소성(sparsity)은 각 입력 예시에 대해 신경망 가중치의 일부만 활성화하는 방식에서 비롯된다.
 Figure 1: Switch Transformer의 스케일링 및 샘플 효율성.
왼쪽 그래프: 점점 더 희소해지는 (더 많은 expert를 가진) Switch Transformer의 스케일링 특성.
오른쪽 그래프: 동일한 연산 예산을 사용하여 Switch Transformer와 T5 (Raffel et al., 2019) 모델을 비교한 negative log perplexity.
Figure 1: Switch Transformer의 스케일링 및 샘플 효율성.
왼쪽 그래프: 점점 더 희소해지는 (더 많은 expert를 가진) Switch Transformer의 스케일링 특성.
오른쪽 그래프: 동일한 연산 예산을 사용하여 Switch Transformer와 T5 (Raffel et al., 2019) 모델을 비교한 negative log perplexity.
**희소 학습(Sparse training)**은 활발한 연구 및 엔지니어링 분야이지만 (Gray et al., 2017; Gale et al., 2020), 현재까지 머신러닝 라이브러리와 하드웨어 가속기는 여전히 dense matrix multiplication에 맞춰져 있다. 효율적인 희소 알고리즘을 위해 우리는 Mixture-of-Expert (MoE) 패러다임 (Jacobs et al., 1991; Jordan and Jacobs, 1994; Shazeer et al., 2017)에서 시작하여, 학습 안정성과 연산 이점을 얻기 위해 이를 단순화한다. MoE 모델은 기계 번역에서 주목할 만한 성공을 거두었지만 (Shazeer et al., 2017, 2018; Lepikhin et al., 2020), 복잡성, 통신 비용, 학습 불안정성으로 인해 광범위한 채택이 어려웠다.
우리는 이러한 문제들을 해결하고, 번역을 넘어 이러한 종류의 알고리즘이 자연어 처리 전반에 걸쳐 가치 있음을 발견한다. 우리는 다양한 자연어 task와 NLP의 세 가지 영역(pre-training, fine-tuning, multi-task training)에서 우수한 스케일링을 측정한다. 이 연구는 규모에 초점을 맞추지만, Switch Transformer 아키텍처가 슈퍼컴퓨터 영역에서 뛰어날 뿐만 아니라, 소수의 연산 코어만으로도 유용함을 보여준다. 또한, 우리의 대규모 희소 모델은 작은 dense 버전으로 distillation (Hinton et al., 2015)될 수 있으며, 이 과정에서 희소 모델 품질 향상의 30%를 유지한다. 우리의 기여는 다음과 같다:
- Mixture of Experts를 단순화하고 개선한 Switch Transformer 아키텍처.
- 강력하게 튜닝된 T5 모델 (Raffel et al., 2019)과의 스케일링 특성 및 벤치마크 비교. 동일한 FLOPS per token을 사용하면서도 7배 이상의 pre-training 속도 향상을 측정했다. 또한, 두 개의 expert만 사용하는 등 제한된 연산 자원에서도 이러한 개선이 유지됨을 보여준다.
- 희소하게 사전학습되고 전문적으로 fine-tuning된 모델을 작은 dense 모델로 성공적으로 distillation. 모델 크기를 최대 99%까지 줄이면서도, 대규모 희소 teacher 모델의 품질 향상 중 30%를 유지한다.
- 개선된 pre-training 및 fine-tuning 기술: (1) 낮은 bfloat16 정밀도로 학습을 가능하게 하는 selective precision training, (2) 더 많은 expert로 스케일링을 가능하게 하는 초기화 방식, (3) 희소 모델 fine-tuning 및 multi-task training을 개선하는 expert regularization 강화.
- 다국어 데이터에 대한 pre-training 이점 측정. 101개 언어 전체에서 보편적인 개선을 발견했으며, 91%의 언어에서 mT5 baseline (Xue et al., 2020) 대비 4배 이상의 속도 향상을 확인했다.
- 데이터, 모델, expert-parallelism을 효율적으로 결합하여 최대 1조 개의 파라미터를 가진 모델을 생성함으로써 신경 언어 모델의 규모를 증가시켰다. 이 모델들은 강력하게 튜닝된 T5-XXL baseline의 pre-training 속도를 4배 향상시킨다.
2. Switch Transformer
Switch Transformer의 핵심 설계 원칙은 Transformer 모델 (Vaswani et al., 2017)의 파라미터 수를 간단하고 계산 효율적인 방식으로 최대화하는 것이다. 규모의 이점은 Kaplan et al. (2020)에서 철저히 연구되었으며, 이 연구는 모델 크기, 데이터셋 크기, 계산 예산에 따른 power-law scaling을 밝혀냈다. 중요한 점은, 이 연구가 계산적으로 최적의 접근 방식으로 상대적으로 적은 양의 데이터로 대규모 모델을 학습하는 것을 옹호한다는 것이다.
이러한 결과에 주목하여, 우리는 네 번째 축을 탐구한다: 예시당 floating point operations (FLOPs)를 일정하게 유지하면서 파라미터 수를 늘리는 것이다. 우리의 가설은 총 수행된 계산량과 무관하게 파라미터 수가 독립적으로 중요한 확장 축이라는 것이다. 우리는 이를 GPU 및 TPU와 같은 dense matrix multiplication에 최적화된 하드웨어를 효율적으로 사용하는 sparsely activated 모델을 설계함으로써 달성한다. 본 연구는 TPU 아키텍처에 중점을 두지만, 이러한 종류의 모델은 GPU 클러스터에서도 유사하게 학습될 수 있다. 우리의 분산 학습 설정에서, sparsely activated layer는 고유한 가중치를 서로 다른 장치에 분할한다. 따라서 모델의 가중치는 장치 수에 비례하여 증가하며, 동시에 각 장치에서 관리 가능한 메모리 및 계산 footprint를 유지한다.
 Figure 2: Switch Transformer encoder block의 도식. 우리는 Transformer에 존재하는 dense feed forward network (FFN) layer를 **sparse Switch FFN layer (연한 파란색)**로 대체한다. 이 layer는 시퀀스 내의 token들에 대해 독립적으로 작동한다. 우리는 두 개의 token ( "More"와 "Parameters")이 **네 개의 FFN expert에 걸쳐 라우팅되는 과정 (실선)**을 도식화했으며, router는 각 token을 독립적으로 라우팅한다. **Switch FFN layer는 선택된 FFN의 출력에 router gate 값을 곱한 결과 (점선)**를 반환한다.
Figure 2: Switch Transformer encoder block의 도식. 우리는 Transformer에 존재하는 dense feed forward network (FFN) layer를 **sparse Switch FFN layer (연한 파란색)**로 대체한다. 이 layer는 시퀀스 내의 token들에 대해 독립적으로 작동한다. 우리는 두 개의 token ( "More"와 "Parameters")이 **네 개의 FFN expert에 걸쳐 라우팅되는 과정 (실선)**을 도식화했으며, router는 각 token을 독립적으로 라우팅한다. **Switch FFN layer는 선택된 FFN의 출력에 router gate 값을 곱한 결과 (점선)**를 반환한다.
2.1 Simplifying Sparse Routing
Mixture of Expert Routing.
Shazeer et al. (2017)는 자연어 Mixture-of-Experts (MoE) layer를 제안했다. 이 layer는 토큰 표현 를 입력으로 받아, 개의 expert 집합 중에서 가장 적합하다고 판단된 top- expert로 라우팅한다.
**라우터 변수 **은 logits 를 생성하며, 이는 해당 layer에서 사용 가능한 개의 expert에 대한 softmax 분포를 통해 정규화된다.
expert 에 대한 gate-value는 다음과 같이 주어진다:
토큰 를 라우팅하기 위해 top- gate value가 선택된다. 만약 가 선택된 top- 인덱스 집합이라면, layer의 출력 계산은 각 expert가 토큰에 대해 수행한 계산에 gate value를 선형적으로 가중 조합한 형태가 된다:
Switch Routing: Mixture-of-Experts 재고.
Shazeer et al. (2017)은 라우팅 함수에 비자명(non-trivial)한 gradient를 얻기 위해서는 expert로 라우팅하는 것이 필요하다고 추측했다. 저자들은 최소한 두 expert를 비교할 수 있는 능력이 없으면 라우팅 학습이 작동하지 않을 것이라고 직관적으로 판단했다. Ramachandran and Le (2018)는 더 나아가 top- 결정에 대해 연구했으며, 많은 라우팅 layer를 가진 모델의 경우 하위 layer에서 더 높은 값이 중요하다는 것을 발견했다.
이러한 아이디어와는 대조적으로, 우리는 단일 expert로만 라우팅하는 단순화된 전략을 사용한다. 우리는 이러한 단순화가 모델 품질을 유지하고, 라우팅 계산을 줄이며, 더 나은 성능을 보인다는 것을 보여준다. 이 라우팅 전략은 이후 Switch layer라고 불린다.
MoE와 Switch Routing 모두에서, Equation 2의 gate value 는 라우터의 미분 가능성을 허용한다.
Switch layer의 이점은 세 가지이다:
(1) 토큰을 단일 expert로만 라우팅하므로 라우터 계산이 감소한다.
(2) 각 토큰이 단일 expert로만 라우팅되므로, 각 expert의 batch size (expert capacity)를 최소 절반으로 줄일 수 있다.
(3) 라우팅 구현이 단순화되고 통신 비용이 감소한다.
Figure 3은 다른 expert capacity factor를 사용한 라우팅 예시를 보여준다.
 Figure 3: 토큰 라우팅 역학(dynamics)에 대한 설명.
Figure 3: 토큰 라우팅 역학(dynamics)에 대한 설명.
각 expert는 capacity factor에 의해 조절되는 고정된 batch-size의 토큰을 처리한다.
각 토큰은 가장 높은 라우터 확률을 가진 expert로 라우팅되지만, 각 expert는 (총 토큰 수 / expert 수) capacity_factor의 고정된 batch size를 가진다.
만약 토큰이 불균등하게 분배되면 특정 expert는 오버플로우(overflow)될 것이며 (점선 빨간색으로 표시), 이로 인해 해당 토큰들은 이 layer에서 처리되지 않는다.
더 큰 capacity factor는 이러한 오버플로우 문제를 완화하지만, 계산 및 통신 비용도 증가시킨다 (패딩된 흰색/빈 슬롯으로 표시).
2.2 Efficient Sparse Routing
우리는 Mesh-Tensorflow (MTF) (Shazeer et al., 2018)를 사용한다. 이는 Tensorflow (Abadi et al., 2016)와 유사한 의미론 및 API를 가진 라이브러리로, 효율적인 분산 데이터 및 모델 병렬 아키텍처를 용이하게 한다. MTF는 물리적인 코어 세트를 논리적인 프로세서 mesh로 추상화하여 이를 수행한다. 그런 다음 텐서와 계산은 명명된 차원별로 sharding될 수 있어, 모델을 차원별로 쉽게 분할할 수 있다. 우리는 TPU를 염두에 두고 모델을 설계했으며, TPU는 정적으로 선언된 크기를 요구한다. 아래에서는 분산 Switch Transformer 구현에 대해 설명한다.
분산 Switch 구현 (Distributed Switch Implementation)
우리의 모든 텐서 형태는 컴파일 시점에 정적으로 결정되지만, 학습 및 추론 시의 라우팅 결정으로 인해 계산은 동적이다. 이 때문에 중요한 기술적 고려 사항 중 하나는 expert capacity를 설정하는 방법이다. Expert capacity는 각 expert가 계산하는 토큰의 수로, 배치 내 토큰 수를 expert 수로 균등하게 나눈 다음, capacity factor를 곱하여 설정된다.
1.0보다 큰 capacity factor는 토큰이 expert들 사이에 완벽하게 균형을 이루지 못할 때를 대비하여 추가적인 버퍼를 생성한다. 너무 많은 토큰이 한 expert로 라우팅되면 (나중에 dropped tokens라고 지칭), 계산이 건너뛰어지고 토큰 표현은 residual connection을 통해 다음 layer로 직접 전달된다. 그러나 expert capacity를 늘리는 것이 단점만 있는 것은 아니다. 높은 값은 계산 및 메모리 낭비를 초래할 수 있기 때문이다. 이러한 trade-off는 Figure 3에 설명되어 있다. 경험적으로 우리는 dropped tokens의 비율을 낮게 유지하는 것이 sparse expert-model의 확장에 중요하다는 것을 발견했다. 우리의 실험 전반에 걸쳐 dropped tokens의 수(일반적으로 <1%)가 expert 수에 의존한다는 것을 발견하지 못했다. 충분히 높은 계수를 가진 보조 부하 분산 손실(auxiliary load balancing loss)(다음 섹션)을 사용하면 좋은 부하 분산을 보장할 수 있었다. 우리는 이러한 설계 결정이 모델 품질과 속도에 미치는 영향을 Table 1에서 연구한다.
미분 가능한 부하 분산 손실 (A Differentiable Load Balancing Loss)
expert들 간의 균형 잡힌 부하를 장려하기 위해 우리는 **보조 손실(auxiliary loss)**을 추가한다 (Shazeer et al., 2017, 2018; Lepikhin et al., 2020). Shazeer et al. (2018); Lepikhin et al. (2020)에서와 같이, Switch Transformer는 Shazeer et al. (2017)의 원래 설계를 단순화하여 별도의 부하 분산 및 중요도 가중치 손실을 가졌다. 각 Switch layer에 대해 이 보조 손실은 학습 중에 전체 모델 손실에 추가된다. 부터 까지 인덱싱된 개의 expert와 개의 토큰을 가진 배치 가 주어졌을 때, 보조 손실은 벡터 와 사이의 **스케일된 내적(scaled dot-product)**으로 계산된다.
여기서 는 expert 로 전달된 토큰의 비율이며,
는 expert 에 할당된 라우터 확률의 비율이다.
우리는 개의 expert에 걸쳐 토큰 배치의 균일한 라우팅을 추구하므로, 두 벡터 모두 의 값을 갖기를 원한다. Equation 4의 보조 손실은 균일 분포에서 최소화되므로 균일한 라우팅을 장려한다. -벡터는 미분 가능하지만 -벡터는 미분 가능하지 않으므로 목적 함수도 미분될 수 있다. 최종 손실은 expert 수 을 곱하여 expert 수가 변하더라도 손실을 일정하게 유지한다. 이는 균일 라우팅 하에서 이기 때문이다. 마지막으로, 하이퍼파라미터 는 이러한 보조 손실에 대한 곱셈 계수이다. 이 연구 전반에 걸쳐 우리는 ****를 사용했는데, 이는 부하 분산을 보장하기에 충분히 크면서도 주된 cross-entropy objective를 압도하지 않을 만큼 작았다. 우리는 의 하이퍼파라미터 범위를 에서 까지 10의 거듭제곱으로 탐색했으며, 가 학습 손실에 방해되지 않으면서 빠르게 부하를 분산시킨다는 것을 발견했다.
2.3 Putting It All Together: The Switch Transformer
Switch Transformer의 첫 번째 테스트는 (Raffel et al., 2019)에서 소개된 "Colossal Clean Crawled Corpus" (C4)로 사전학습을 시작한다. 사전학습 objective로는 masked language modeling task (Taylor, 1953; Fedus et al., 2018; Devlin et al., 2018)를 사용하며, 모델은 누락된 토큰을 예측하도록 학습된다. Raffel et al. (2019)에서 최적이라고 결정된 사전학습 설정에 따라, 우리는 15%의 토큰을 드롭아웃하고 마스킹된 시퀀스를 단일 sentinel 토큰으로 대체한다. 모델들을 비교하기 위해 negative log perplexity를 기록한다. 본 논문의 모든 표에서 는 해당 metric의 값이 높을수록 좋음을 나타내고, 는 그 반대를 나타낸다. 본 연구에서 다룬 모든 모델의 비교는 Table 9에 있다.
Switch Transformer와 MoE Transformer의 직접적인 비교는 Table 1에 제시되어 있다. 우리의 Switch Transformer 모델은 'T5-Base' (Raffel et al., 2019)와 FLOP-matched되어 있다 (토큰당 동일한 양의 연산이 적용됨). top-2 라우팅을 사용하는 MoE Transformer는 두 개의 expert를 가지며, 각 expert는 각 토큰에 별도의 FFN을 적용하므로 FLOPS가 더 크다. 모든 모델은 동일한 하드웨어에서 동일한 스텝 수로 학습되었다. 위 실험 설정에서 MoE 모델이 capacity factor 2.0에서 1.25로 갈 때 실제로 속도가 느려지는 것(840에서 790으로)은 예상 밖의 결과이다.
Table 1에서 세 가지 주요 발견을 강조한다: (1) Switch Transformer는 속도-품질 측면에서 신중하게 튜닝된 dense 모델과 MoE Transformer 모두를 능가한다. 고정된 연산량과 wall-clock time에서 Switch Transformer는 최고의 결과를 달성한다. (2) Switch Transformer는 MoE 모델보다 연산 footprint가 더 작다. 만약 MoE Transformer의 학습 속도에 맞춰 Switch Transformer의 크기를 늘리면, 스텝당 성능에서도 모든 MoE 및 Dense 모델을 능가함을 발견한다. (3) Switch Transformer는 더 낮은 capacity factor (1.0, 1.25)에서 더 나은 성능을 보인다. 더 작은 expert capacity는 모델 메모리가 매우 부족하고 capacity factor를 가능한 한 작게 만들고자 하는 대규모 모델 환경의 시나리오를 나타낸다.
2.4 Improved Training and Fine-Tuning Techniques
Sparse expert model은 vanilla Transformer에 비해 학습에 어려움을 초래할 수 있다. 각 layer에서의 hard-switching (routing) 결정으로 인해 불안정성이 발생할 수 있으며, bfloat16 (Wang and Kanwar, 2019)과 같은 낮은 정밀도 형식은 이러한 문제를 더욱 악화시킬 수 있다.
| Model | Capacity Factor | Quality after 100k steps ( ) (Neg. Log Perp.) | Time to Quality Threshold ( ) (hours) | Speed ( ) (examples/sec) |
|---|---|---|---|---|
| T5-Base | - | -1.731 | Not achieved | 1600 |
| T5-Large | - | -1.550 | 131.1 | 470 |
| MoE-Base | 2.0 | -1.547 | 68.7 | 840 |
| Switch-Base | 2.0 | -1.554 | 72.8 | 860 |
| MoE-Base | 1.25 | -1.559 | 80.7 | 790 |
| Switch-Base | 1.25 | -1.553 | 65.0 | 910 |
| MoE-Base | 1.0 | -1.572 | 80.1 | 860 |
| Switch-Base | 1.0 | -1.561 | 62.8 | 1000 |
| Switch-Base+ | 1.0 | -1.534 | 67.6 | 780 |
Table 1: Switch와 MoE 벤치마킹. Switch Transformer가 MoE Transformer 및 T5 dense baseline에 비해 단계별(per step) 및 시간별(per time) 이점을 측정하는 직접적인 비교이다. 우리는 **음의 로그 퍼플렉시티(negative log perplexity)**로 품질을 측정하고, 임의로 선택된 품질 임계값(Neg. Log Perp. = -1.50)에 도달하는 시간을 측정한다. 모든 MoE 및 Switch Transformer 모델은 128개의 expert를 사용하며, expert는 격층(every other) feed-forward layer에 배치된다. **Switch-Base+**의 경우, 모델의 hidden-size를 768에서 896으로, head의 수를 14에서 16으로 늘려 MoE 모델의 속도와 일치할 때까지 모델 크기를 증가시켰다. 모든 모델은 동일한 양의 연산(32 cores)과 동일한 하드웨어(TPUv3)에서 학습되었다. 또한, 모든 모델은 -1.50의 임계값에 도달하기 위해 100k step 이상 사전학습이 필요했다. T5-Base는 모델이 학습된 100k step 내에 이 음의 로그 퍼플렉시티를 달성하지 못했다.
특히 라우터의 softmax 계산에서 문제가 발생할 수 있다. 여기서는 학습의 어려움과 이를 극복하여 안정적이고 확장 가능한 학습을 달성하기 위해 사용한 방법들을 설명한다.
대규모 sparse 모델에서의 선택적 정밀도(Selective precision)
모델의 불안정성은 효율적인 bfloat16 정밀도를 사용하여 학습하는 것을 방해하며, 그 결과 Lepikhin et al. (2020)은 MoE Transformer 전체에 걸쳐 float32 정밀도로 학습한다. 그러나 우리는 모델의 특정 부분에서만 선택적으로 float32 정밀도로 캐스팅함으로써, float32 텐서의 비싼 통신 비용을 발생시키지 않고도 안정성을 달성할 수 있음을 보여준다. 이 기술은 모델의 특정 부분과 gradient 업데이트가 더 높은 정밀도로 수행되는 최신 혼합 정밀도 학습(mixed precision training) 전략과 일치한다 (Micikevicius et al., 2017). Table 2는 우리의 접근 방식이 bfloat16 학습과 거의 동일한 속도를 유지하면서 float32의 학습 안정성을 제공함을 보여준다.
이를 위해 우리는 라우터 입력(router input)을 float32 정밀도로 캐스팅한다. 라우터 함수는 토큰을 입력으로 받아 expert 계산의 선택 및 재조합에 사용되는 dispatch 및 combine 텐서를 생성한다 (자세한 내용은 Appendix의 Code Block 15 참조). 중요한 것은 float32 정밀도는 라우터 함수 본문 내에서만 사용된다는 점이다. 즉, 해당 장치에 국한된 계산에서만 사용된다. 결과로 생성되는 dispatch 및 combine 텐서는 함수 끝에서 bfloat16 정밀도로 다시 캐스팅되므로, 비싼 float32 텐서가
| Model (precision) | Quality (Neg. Log Perp.) ( ) | Speed (Examples/sec) ( ) |
|---|---|---|
| Switch-Base (float32) | -1.718 | 1160 |
| Switch-Base (bfloat16) | -3.780 [diverged] | 1390 |
| Switch-Base (Selective precision) | -1.716 | 1390 |
Table 2: 선택적 정밀도(Selective precision). 우리는 로컬 라우팅 연산을 float32로 캐스팅하고 다른 부분에서는 bfloat16 정밀도를 유지하여, 불안정한 bfloat16 정밀도 학습과 거의 동일한 속도를 달성하면서 모델의 안정성을 확보한다. 우리는 학습 초기에 고정된 step 수 이후 32 expert 모델의 품질과 속도 성능을 측정한다. float32 및 선택적 정밀도를 사용한 Switch-Base 모두에서 유사한 학습 동역학을 관찰한다.
all-to-all 통신 작업을 통해 브로드캐스트되지 않지만, 우리는 여전히 float32의 향상된 안정성으로부터 이점을 얻는다.
안정성을 위한 더 작은 파라미터 초기화
적절한 초기화는 딥러닝 학습 성공에 매우 중요하며, 우리는 특히 Switch Transformer에서 이것이 사실임을 관찰한다. 우리는 평균 및 표준 편차 를 갖는 절단 정규 분포(truncated normal distribution)에서 요소를 추출하여 가중치 행렬을 초기화한다. 여기서 는 스케일 하이퍼파라미터이고 은 가중치 텐서의 입력 단위 수(예: fan-in)이다.
불안정성에 대한 추가적인 해결책으로, 우리는 기본 Transformer 초기화 스케일 을 10분의 1로 줄일 것을 권장한다. 이는 우리의 실험에서 품질을 향상시키고 불안정한 학습 가능성을 줄여준다. Table 3은 학습 초기에 모델 품질의 향상과 분산의 감소를 측정한다. 우리는
| Model (Initialization scale) | Average Quality <br> (Neg. Log Perp.) | Std. Dev. of Quality <br> (Neg. Log Perp.) |
|---|---|---|
| Switch-Base (0.1x-init) | ||
| Switch-Base (1.0x-init) | -3.60 | 0.68 |
Table 3: 초기화 스케일 감소가 안정성을 향상시킨다. 초기화 스케일을 줄이면 Switch Transformer의 모델 품질이 향상되고 학습이 더 안정적이 된다. 여기서는 3.5k step 이후 32 expert 모델의 모델 품질(음의 로그 퍼플렉시티로 측정)의 평균과 표준 편차를 기록한다 (각각 3개의 랜덤 시드).
**Neg. Log Perp.**로 측정된 평균 모델 품질이 극적으로 향상되었고, 실행 간 분산이 훨씬 감소했음을 발견한다. 또한, 이 동일한 초기화 방식은 여러 자릿수의 모델에 걸쳐 광범위하게 효과적이다. 우리는 동일한 접근 방식을 사용하여 223M 파라미터 baseline과 같은 작은 모델부터 1조 개 이상의 파라미터를 가진 거대한 모델까지 안정적으로 학습시킨다.
대규모 sparse 모델 정규화
본 논문은 대규모 코퍼스에서 사전학습한 후 요약 또는 질문 응답과 같은 더 작은 다운스트림 task에 fine-tuning하는 일반적인 NLP 접근 방식을 고려한다. 여기서 자연스럽게 발생하는 한 가지 문제는 **과적합(overfitting)**이다. 왜냐하면 많은 fine-tuning task는 예시가 매우 적기 때문이다. 표준 Transformer의 fine-tuning 동안 Raffel et al. (2019)는 과적합을 방지하기 위해 각 layer에서 dropout (Srivastava et al., 2014)을 사용한다. 우리의 Switch Transformer는 FLOP이 일치하는 dense baseline보다 훨씬 더 많은 파라미터를 가지고 있어, 이러한 더 작은 다운스트림 task에서 더 심각한 과적합을 초래할 수 있다.
| Model (dropout) | GLUE | CNNDM | SQuAD | SuperGLUE |
|---|---|---|---|---|
| T5-Base ( ) | 82.9 | 19.6 | 83.5 | 72.4 |
| Switch-Base ( ) | 84.7 | 19.1 | 83.7 | 73.0 |
| Switch-Base ( ) | 84.4 | 19.2 | 83.9 | 73.2 |
| Switch-Base ( ) | 83.9 | 19.6 | 83.4 | 70.7 |
| Switch-Base ( ) | 85.2 | 19.6 | 83.7 | 73.0 |
Table 4: Fine-tuning 정규화 결과. C4 데이터셋의 34B 토큰으로 사전학습된 Switch Transformer 모델을 fine-tuning하는 동안 dropout 비율을 스윕한 결과 (높은 숫자가 더 좋다). 우리는 expert가 아닌 모든 layer에서 더 낮은 표준 dropout 비율을 사용하고, expert feed-forward layer에서는 훨씬 더 큰 dropout 비율을 사용하는 것이 가장 좋은 성능을 보인다는 것을 관찰한다.
따라서 우리는 fine-tuning 동안 이 문제를 완화하는 간단한 방법을 제안한다: expert 내부의 dropout을 증가시키는 것인데, 이를 expert dropout이라고 명명한다. fine-tuning 동안 우리는 각 expert layer의 중간 feed-forward 계산에서만 dropout 비율을 상당히 증가시킨다. Table 4는 우리의 expert dropout 프로토콜에 대한 결과를 보여준다. 우리는 모든 layer에서 dropout을 단순히 증가시키는 것이 성능을 저하시킨다는 것을 관찰한다. 그러나 expert가 아닌 layer에서는 더 작은 dropout 비율(0.1)을 설정하고 expert layer에서는 훨씬 더 큰 dropout 비율(0.4)을 설정하는 것이 4개의 더 작은 다운스트림 task에서 성능 향상을 가져온다.
3. Scaling Properties
우리는 사전학습(pre-training) 과정에서 Switch Transformer 아키텍처의 스케일링 특성에 대한 연구를 제시한다. Kaplan et al. (2020)에 따라, 우리는 모델이 연산 예산이나 데이터 양에 의해 병목 현상을 겪지 않는 환경을 고려한다. 데이터 병목 현상을 피하기 위해, 우리는 180B개 이상의 target token을 포함하는 대규모 C4 코퍼스 (Raffel et al., 2019)를 사용했으며, 수확 체감(diminishing returns)이 관찰될 때까지 학습을 진행했다.
expert의 수는 모델을 스케일링하는 데 가장 효율적인 차원이다. expert의 수를 늘려도 연산 비용은 거의 고정되는데, 이는 모델이 선택할 expert의 수와 관계없이 토큰당 하나의 expert만 선택하기 때문이다. 하지만 router는 더 많은 expert에 대한 확률 분포를 계산해야 한다. 이 계산은 의 비용을 가지는 경량 연산이며, 여기서 은 layer들 사이에서 전달되는 토큰의 embedding dimension이다. 이 섹션에서는 고정된 연산 예산 내에서 step-basis 및 time-basis로 스케일링 특성을 고려한다.
3.1 Scaling Results on a Step-Basis
Figure 4는 모든 모델을 고정된 step 수로 학습했을 때, expert 수가 증가함에 따라 일관된 스케일링 이점을 보여준다. 우리는 FLOPS per token을 고정했을 때, 더 많은 파라미터(expert)를 가질수록 학습 속도가 빨라지는 명확한 경향을 관찰한다.
왼쪽 그림은 **sparse model 파라미터와 test loss 간의 일관된 스케일링 특성(FLOPS per token 고정)**을 보여준다. 이는 sparse model 파라미터라는 추가적인 축을 따라 스케일링하는 것의 이점을 드러낸다.
오른쪽 그림은 dense 모델 변형과 FLOPS가 일치하는 4가지 sparse 모델 변형의 sample efficiency를 측정한다. 우리는 expert 수가 증가할수록 sample efficiency가 더 높은 모델이 된다는 것을 발견했다. 우리의 Switch-Base 64 expert 모델은 T5-Base 모델이 60k step에서 달성하는 동일한 성능을 450k step에서 달성하는데, 이는 step time 측면에서 7.5배의 속도 향상이다. 또한, Kaplan et al. (2020)의 연구 결과와 일관되게, 우리는 더 큰 모델이 더 sample efficient하며, 고정된 수의 관찰된 token에 대해 더 빠르게 학습한다는 것을 발견했다.
 Figure 4: Switch Transformer의 스케일링 특성.
Figure 4: Switch Transformer의 스케일링 특성.
왼쪽 그래프: expert 수를 스케일링하여 파라미터가 증가함에 따라 perplexity로 측정된 품질 개선을 측정한다. 왼쪽 상단 점은 223M 파라미터를 가진 T5-Base 모델에 해당한다. 왼쪽 상단에서 오른쪽 하단으로 이동하면서, expert 수를 2, 4, 8 등으로 두 배씩 늘려 14.7B 파라미터를 가진 256 expert 모델에 이른다. 모든 모델이 동일한 연산 예산을 사용했음에도 불구하고, expert 수를 스케일링함에 따라 일관된 성능 개선을 관찰한다.
오른쪽 그래프: expert 수에 따른 step당 negative log perplexity를 측정한다. dense baseline은 보라색 선으로 표시되며, Switch-Base 모델의 향상된 sample efficiency를 확인할 수 있다.
3.2 Scaling Results on a Time-Basis
Figure 4는 expert의 수를 늘릴수록 step 단위로 성능이 꾸준히 향상됨을 보여준다. 우리의 Switch Transformer 모델은 baseline과 토큰당 FLOPS가 거의 동일하지만, 라우팅 메커니즘의 추가적인 연산과 더불어 디바이스 간의 추가적인 통신 비용이 발생한다. 따라서 step 단위로 관찰된 sample efficiency의 증가는 wall-clock 시간으로 측정했을 때 반드시 더 나은 모델 품질로 이어지는 것은 아니다. 이는 다음과 같은 질문을 제기한다:
고정된 학습 기간과 연산 예산 내에서, dense 모델을 학습시켜야 하는가 아니면 sparse 모델을 학습시켜야 하는가?
 Figure 5: Switch Transformer의 속도 이점. 모든 모델은 32개의 TPUv3 코어에서 예시당 동일한 FLOPs로 학습되었다. 고정된 연산량과 학습 시간 내에서, Switch Transformer는 dense Transformer baseline을 크게 능가한다. 우리의 64 expert Switch-Base 모델은 T5-Base와 유사한 품질을 7분의 1의 시간 내에 달성하며, 계속해서 성능이 향상된다.
Figure 5: Switch Transformer의 속도 이점. 모든 모델은 32개의 TPUv3 코어에서 예시당 동일한 FLOPs로 학습되었다. 고정된 연산량과 학습 시간 내에서, Switch Transformer는 dense Transformer baseline을 크게 능가한다. 우리의 64 expert Switch-Base 모델은 T5-Base와 유사한 품질을 7분의 1의 시간 내에 달성하며, 계속해서 성능이 향상된다.
Figure 5와 6은 이 질문에 답한다. Figure 5는 학습 시간의 함수로서 사전학습 모델의 품질을 측정한다. 고정된 학습 기간과 연산 예산 내에서, Switch Transformer는 상당한 속도 향상을 가져온다. 이 설정에서, 우리의 Switch-Base 64 expert 모델은 T5-Base가 유사한 perplexity를 얻는 데 걸리는 시간의 7분의 1만에 학습된다.
3.3 Scaling Versus a Larger Dense Model
위 분석은 연산량(computationally)이 동일하게 맞춰진 dense 모델이 Switch 모델에 비해 성능이 뒤처짐을 보여준다. Figure 6은 다른 시나리오를 고려한다: 만약 우리가 자원을 더 큰 dense 모델에 할당했다면 어땠을까? 우리는 이제 Switch-Base를 다음으로 강력한 baseline인 T5-Large와 비교한다. 하지만 T5-Large가 토큰당 3.5배 더 많은 FLOPs를 적용함에도 불구하고,
Switch-Base는 여전히 더 sample efficient하며 2.5배의 속도 향상을 보인다. 더욱이, T5-Large와 FLOPs가 동일하게 맞춰진 새로운 대규모 sparse 버전인 Switch-Large를 설계함으로써 더 많은 이득을 얻을 수 있다. 우리는 다음 섹션에서 이를 수행하고 우수한 scaling 및 fine-tuning 성능을 입증한다.
 Figure 6: Switch layer 또는 표준 dense 모델 scaling을 이용한 Transformer 모델 scaling.
왼쪽 그래프: Switch-Base는 T5-Base와 토큰당 3.5배 더 많은 FLOPs를 적용하는 T5-Large 변형 모델 모두보다 더 sample efficient하다.
오른쪽 그래프: 이전과 마찬가지로, 실제 시간(wall-clock basis) 기준으로 Switch-Base는 여전히 더 빠르며, T5-Large에 비해 2.5배의 속도 향상을 보인다.
Figure 6: Switch layer 또는 표준 dense 모델 scaling을 이용한 Transformer 모델 scaling.
왼쪽 그래프: Switch-Base는 T5-Base와 토큰당 3.5배 더 많은 FLOPs를 적용하는 T5-Large 변형 모델 모두보다 더 sample efficient하다.
오른쪽 그래프: 이전과 마찬가지로, 실제 시간(wall-clock basis) 기준으로 Switch-Base는 여전히 더 빠르며, T5-Large에 비해 2.5배의 속도 향상을 보인다.
4. Downstream Results
Section 3에서는 사전학습 시 우수한 **확장성(scaling properties)**을 입증했지만, 이제 이러한 이점이 다운스트림 task에서의 향상된 언어 학습 능력으로 이어지는지를 검증한다.
먼저, 다양한 NLP task에 대해 fine-tuning을 수행한다.
다음으로, sparse model의 메모리 사용량을 90% 이상 줄이는 방법을 연구한다. 이는 작고 배포하기 쉬운 dense baseline으로 지식 증류(distillation)하는 방식을 통해 이루어진다.
마지막으로, 이 섹션에서는 multi-task, multilingual 환경에서의 개선 사항을 측정한다. 여기서 우리는 Switch Transformer가 강력한 multi-task learner이며, 101개 언어 전체에서 multilingual T5-base 모델보다 성능이 향상됨을 보여준다.
4.1 Fine-Tuning
Fine-tuning에 사용된 Baseline 및 Switch 모델
우리의 baseline은 223M 파라미터의 T5-Base 모델과 739M 파라미터의 T5-Large 모델이다 (Raffel et al., 2019). 두 버전 모두에 대해, 우리는 FLOP-matched Switch Transformer를 설계했으며, 이는 훨씬 더 많은 파라미터를 가지고 있고 Table 9에 요약되어 있다. 우리의 baseline은 Raffel et al. (2019)의 모델과 약간 다르다. 이는 우리가 intra-example 텍스트 중복을 제거하여 사전학습 task의 효율성을 높인 개선된 C4 코퍼스로 사전학습을 수행했기 때문이다 (Lee et al., 2021). 우리의 프로토콜에서는 배치당 (1,048,576) 토큰으로 550k 스텝 동안 사전학습을 진행하여 총 576B 토큰을 사용했다. 이후, Switch layer를 제외한 모든 layer에 0.1의 dropout rate를 적용하고, Switch layer에는 0.4의 dropout rate를 적용하여 다양한 task에 대해 fine-tuning을 수행했다 (Table 4 참조). Fine-tuning은 1M의 배치 사이즈로 16k 스텝 동안 진행했으며, 각 task에 대해 200 스텝마다 모델 품질을 평가하고 validation set에서 계산된 최고 성능을 보고한다.
Fine-tuning task 및 데이터셋
우리는 질문 응답, 요약, 세계 지식을 포함한 언어 능력을 측정하는 task들을 선택했다. GLUE (Wang et al., 2018) 및 SuperGLUE (Wang et al., 2019) 언어 벤치마크는 각 task에 존재하는 토큰 양에 비례하여 모든 task를 혼합한 **복합 혼합(composite mixtures)**으로 처리된다. 이 벤치마크들은 다음과 같은 task들로 구성된다:
- 감성 분석 (SST2)
- 단어 의미 중의성 해소 (WIC)
- 문장 유사성 (MRPC, STS-B, QQP)
- 자연어 추론 (MNLI, QNLI, RTE, CB)
- 질문 응답 (MultiRC, RECORD, BoolQ)
- 공동 참조 해소 (WNLI, WSC)
- 문장 완성 (COPA)
- 문장 수용성 (CoLA)
CNNDM (Hermann et al., 2015) 및 BBC XSum (Narayan et al., 2018) 데이터셋은 기사 요약 능력을 측정하는 데 사용된다. 질문 응답은 **SQuAD 데이터셋 (Rajpurkar et al., 2016)**과 **ARC Reasoning Challenge (Clark et al., 2018)**로 측정된다. 그리고 Roberts et al. (2020)에서와 같이, 우리는 세 가지 closed-book 질문 응답 데이터셋인 **Natural Questions (Kwiatkowski et al., 2019), Web Questions (Berant et al., 2013), Trivia QA (Joshi et al., 2017)**에 대해 fine-tuning하여 모델의 지식을 평가한다. Closed-book은 보충 참고 자료나 맥락 정보 없이 질문이 제시되는 경우를 의미한다. 모델의 상식 추론 능력을 측정하기 위해 **Winogrande Schema Challenge (Sakaguchi et al., 2020)**로 평가한다. 마지막으로, **Adversarial NLI Benchmark (Nie et al., 2019)**에서 모델의 자연어 추론 능력을 테스트한다.
Fine-tuning 지표
본 논문 전반에 걸쳐 다음 평가 지표들이 사용된다: GLUE 및 SuperGLUE의 경우, 모든 하위 task에 대한 평균 점수를 보고한다. CNNDM 및 XSum에서는 Rouge-2 지표가 사용된다. **SQuAD 및 closed-book task (Web, Natural, Trivia Questions)**에서는 정답과 정확히 일치하는 답변의 비율을 보고한다 (이 측정치의 세부 사항 및 한계는 Roberts et al. (2020) 참조). 마지막으로, ARC Easy, ARC Challenge, ANLI, Winogrande에서는 생성된 응답의 정확도를 보고한다.
Fine-tuning 결과
우리는 많은 자연어 task에서 상당한 다운스트림 개선을 관찰했다. 특히 SuperGLUE에서 FLOP-matched Switch variant가 T5-Base 및 T5-Large baseline보다 각각 4.4% 및 2% 포인트 향상되었으며, Winogrande, closed-book Trivia QA, XSum에서도 큰 개선을 보였다. 우리의 fine-tuning 연구에서 성능 향상을 관찰하지 못한 유일한 task는 AI2 Reasoning Challenge (ARC) 데이터셋이었다. 이 데이터셋에서는 T5-Base가 challenge 데이터셋에서 Switch-Base를 능가하고, T5-Large가 easy 데이터셋에서 Switch-Large를 능가했다. 전체적으로 볼 때, 우리는 추론 및 지식 중심 task 모두에서 상당한 개선을 관찰했다. 이는 우리의 아키텍처가 사전학습이 잘 될 뿐만 아니라, fine-tuning을 통해 다운스트림 task에서도 품질 개선을 이끌어낼 수 있음을 입증한다.
8. 우리의 T5 및 Switch 모델은 공정한 비교를 위해 수정된 C4 데이터셋에서 배치당 토큰으로 550k 스텝 동안 사전학습되었다.
| Model | GLUE | SQuAD | SuperGLUE | Winogrande (XL) |
|---|---|---|---|---|
| T5-Base | 84.3 | 85.5 | 75.1 | 66.6 |
| Switch-Base | 86.7 | 87.2 | 79.5 | 73.3 |
| T5-Large | 87.8 | 88.1 | 82.7 | 79.1 |
| Switch-Large | 88.5 | 88.6 | 84.7 | 83.0 |
| Model | XSum | ANLI (R3) | ARC Easy | ARC Chal. |
| T5-Base | 18.7 | 51.8 | 56.7 | 35.5 |
| Switch-Base | 20.3 | 54.0 | 61.3 | 32.8 |
| T5-Large | 20.9 | 56.6 | 68.8 | 35.5 |
| Switch-Large | 22.3 | 58.6 | 66.0 | 35.5 |
| Model | CB Web QA | CB Natural QA | CB Trivia QA | |
| T5-Base | 26.6 | 25.8 | 24.5 | |
| Switch-Base | 27.4 | 26.8 | 30.7 | |
| T5-Large | 27.7 | 27.6 | 29.5 | |
| Switch-Large | 31.3 | 29.5 | 36.9 |
Table 5: Fine-tuning 결과.
T5 baseline 및 Switch 모델의 다양한 자연어 테스트 (validation set; 숫자가 높을수록 좋음)에 대한 fine-tuning 결과. 우리는 FLOP-matched Switch 모델을 T5-Base 및 T5-Large baseline과 비교한다. 고려된 대부분의 task에서 Switch variant의 상당한 개선을 발견했다. 우리는 두 모델 크기 모두에서, 그리고 추론 및 지식 중심 언어 task 모두에서 성능 향상을 관찰했다.
4.2 Distillation
수십억 또는 수조 개의 파라미터를 가진 대규모 신경망을 배포하는 것은 불편한 일이다. 이를 완화하기 위해 우리는 대규모 sparse 모델을 소규모 dense 모델로 증류(distilling)하는 연구를 수행한다 (Hinton et al., 2015). 향후 연구에서는 대규모 모델을 더 작은 sparse 모델로 증류하는 방식도 추가적으로 탐구할 수 있을 것이다.
증류 기법 (Distillation techniques)
Table 6에서 우리는 다양한 증류 기법들을 연구한다. 이 기법들은 BERT 모델의 증류 방법을 연구한 Sanh et al. (2019)의 연구를 기반으로 한다.
우리는 dense 모델을 non-expert 가중치로 초기화하는 것이 약간의 성능 향상을 가져온다는 것을 발견했다. 이는 모든 모델이 FLOP이 일치하기 때문에 non-expert layer들이 동일한 차원을 가질 수 있기 때문이다. expert layer는 일반적으로 Transformer의 FFN layer마다 또는 격층으로만 추가되기 때문에, 많은 가중치들이 학습된 파라미터로 초기화될 수 있다.
또한, 우리는 teacher 확률에 0.25, ground truth label에 0.75의 혼합 비율을 사용하여 증류 성능이 향상됨을 관찰했다. 이 두 가지 기법을 결합함으로써, 우리는 더 큰 sparse 모델의 품질 향상분 중 약 30%를 유지하면서도, 파라미터 수는 약 1/20 수준으로 줄일 수 있었다. 여기서 **품질 향상(quality gain)**은 Switch-Base (Teacher)와 T5-Base (Student) 간의 품질 차이 비율을 의미한다. 따라서 100%의 품질 향상은 Student 모델이 Teacher 모델과 동일한 성능을 달성했음을 나타낸다.
| Technique | Parameters | Quality |
|---|---|---|
| T5-Base | 223 M | -1.636 |
| Switch-Base | -1.444 | |
| Distillation | 223 M | |
| + Init. non-expert weights from teacher | 223 M | |
| +0.75 mix of hard and soft loss | 223 M | |
| Initialization Baseline (no distillation) | ||
| Init. non-expert weights from teacher | 223 M | -1.639 |
Table 6: Language Modeling을 위한 Switch Transformer 증류.
T5-Base를 Switch-Base의 non-expert 가중치로 초기화하고, teacher와 ground-truth label의 혼합 loss를 사용했을 때 가장 좋은 성능을 얻는다. 우리는 100배 더 많은 파라미터를 가진 대규모 sparse 모델의 성능 향상분 중 30%를 소규모 dense 모델로 증류할 수 있다. 최종 baseline으로, expert 가중치로 초기화되었지만 증류 없이 일반 학습된 T5-Base에서는 성능 향상이 없음을 확인했다.
달성 가능한 압축률 (Achievable compression rates)
Table 6에 설명된 최고의 증류 기법을 사용하여, 우리는 다양한 sparse 모델을 dense 모델로 증류한다. 우리는 Switch-Base 버전들을 증류하며, expert 수를 증가시켜 1.1B에서 14.7B 파라미터 범위를 탐색했다. 증류를 통해, 1.1B 파라미터 모델의 품질 향상분 중 37%를 유지하면서 82%를 압축할 수 있었다. 극단적인 경우, 모델을 99% 압축했을 때도 teacher 모델 품질 향상분의 28%를 유지할 수 있었다.
Fine-tuned 모델 증류 (Distilling a fine-tuned model)
이 섹션의 결론으로, 우리는 fine-tuned sparse 모델을 dense 모델로 증류하는 연구를 수행한다. Table 8은 SuperGLUE task로 fine-tuned된 7.4B 파라미터 Switch-Base 모델을 223M T5-Base로 증류한 결과를 보여준다. 사전학습 결과와 유사하게, 우리는 FLOP이 일치하는 dense 모델로 증류했을 때 sparse 모델의 성능 향상분 중 30%를 유지할 수 있음을 발견했다. 여기서 고려되지 않은 잠재적인 향후 연구 방향으로는, fine-tuning task에 사용되는 특정 expert들을 분석하고 이를 추출하여 더 나은 모델 압축을 달성하는 방법이 있을 수 있다.
4.3 Multilingual Learning
최종 다운스트림 실험 세트에서는 101개 언어의 혼합 데이터로 사전학습할 때의 모델 품질과 속도 간의 trade-off를 측정한다. 우리는 T5의 다국어 확장 버전인 mT5 (Xue et al., 2020)의 최근 연구를 기반으로 벤치마크를 구축한다. mT5에서 소개된 101개 언어에 걸쳐 있는 Common Crawl 데이터셋의 다국어 변형(mC4)으로 사전학습하지만, 특정 언어 내의 스크립트 변형으로 인해 혼합 데이터는 107개의 task를 포함한다.
Figure 7에서는 FLOP이 일치하는 Switch 모델인 mSwitch-Base와 T5-Base 변형인 mT5-Base의 모든 언어에 대한 negative log perplexity의 품질 향상을 그래프로 나타낸다.
| Dense | Sparse | |||||
|---|---|---|---|---|---|---|
| Parameters | 223 M | 1.1 B | 2.0 B | 3.8 B | 7.4 B | 14.7 B |
| Pre-trained Neg. Log Perp. ( ) | -1.636 | -1.505 | -1.474 | -1.444 | -1.432 | -1.427 |
| Distilled Neg. Log Perp. ( ) | - | -1.587 | -1.585 | -1.579 | -1.582 | -1.578 |
| Percent of Teacher Performance | - | 37% | 32% | 30 % | 27 % | 28 % |
| Compression Percent | - | 82 % | 90 % | 95 % | 97 % | 99 % |
Table 7: Distillation 압축률. 우리는 대규모 sparse 모델을 dense baseline으로 distillation할 때의 품질을 측정한다. 우리의 baseline인 T5-Base는 -1.636의 Neg. Log Perp. 품질을 가진다. 오른쪽 열에서는 점점 더 큰 sparse 모델을 동일한 아키텍처로 distillation한다. 가중치 초기화와 hard 및 soft loss의 혼합을 통해, sparse teacher 모델을 95% 이상 압축하면서도 품질 향상의 30%를 유지할 수 있다. 그러나 훨씬 더 좋고 큰 사전학습된 teacher 모델의 경우, 이러한 압축률을 달성하려면 더 큰 student 모델이 필요할 것으로 예상된다.
| Model | Parameters | FLOPS | SuperGLUE ( ) |
|---|---|---|---|
| T5-Base | 223 M | 124 B | 74.6 |
| Switch-Base | 7410 M | 124 B | 81.3 |
| Distilled T5-Base | 223 M | 124 B |
Table 8: Fine-tuned SuperGLUE 모델 distillation. 우리는 SuperGLUE task에 fine-tuned된 Switch-Base 모델을 T5-Base 모델로 distillation한다. 더 작은 데이터셋에서 우리의 대규모 sparse 모델이 distillation을 위한 효과적인 teacher가 될 수 있음을 관찰한다. 우리는 97% 압축된 모델에서 teacher 성능의 30%를 다시 달성함을 확인한다.
두 버전 모두 1M step 동안 사전학습한 결과, 고려된 101개 언어 모두에서 Switch Transformer가 baseline 대비 최종 negative log perplexity를 증가시켰음을 확인했다. Figure 8에서는 다른 관점을 제시하며, mT5-Base 대비 Switch Transformer 사용 시의 step당 속도 향상을 히스토그램으로 나타낸다. 우리는 mT5-Base 대비 평균 5배의 속도 향상을 확인했으며, 91%의 언어에서 최소 4배의 속도 향상을 달성했다. 이는 Switch Transformer가 효과적인 multi-task 및 multi-lingual 학습자임을 입증하는 증거이다.
5. Designing Models with Data, Model, and Expert-Parallelism
전문가(expert)의 수를 무작정 늘리는 것은 **점점 더 낮은 효율(diminishing returns)**을 가져온다 (Figure 4). 여기서는 보완적인 스케일링 전략들을 설명한다.
Transformer를 스케일링하는 일반적인 방법은 또는 와 같은 차원들을 함께 증가시키는 것이다. 이는 파라미터와 수행되는 연산량 모두를 증가시키며, 궁극적으로는 가속기(accelerator)당 메모리 용량에 의해 제한된다. 가속기 메모리 크기를 초과하면 **단일 프로그램 다중 데이터(SPMD) 모델 병렬화(model-parallelism)**를 사용할 수 있다. 이 섹션에서는 데이터, 모델, 전문가 병렬화(expert-parallelism)를 결합하는 것의 trade-off를 연구한다.
 Figure 7: 101개 언어에 대한 다국어 사전학습. 101개 언어에 대한 multi-task 학습 시 dense baseline 대비 Switch T5 Base 모델의 개선 사항. Switch Transformer가 multi-task 학습 설정에서 매우 잘 작동하며 101개 언어 모두에서 개선을 가져옴을 관찰했다.
Figure 7: 101개 언어에 대한 다국어 사전학습. 101개 언어에 대한 multi-task 학습 시 dense baseline 대비 Switch T5 Base 모델의 개선 사항. Switch Transformer가 multi-task 학습 설정에서 매우 잘 작동하며 101개 언어 모두에서 개선을 가져옴을 관찰했다.
 Figure 8: 101개 언어에 대한 다국어 사전학습. 각 언어에 대해, 동일한 품질에 도달하기 위한 FLOP이 일치하는 T5 dense baseline 대비 Switch Transformer의 step speedup을 히스토그램으로 나타냈다. 101개 언어 전체에서 mT5-Base 대비 평균 5배의 step speedup을 달성했으며, 91%의 언어에서 mT5-Base의 최종 perplexity에 도달하기 위해 4배 이상의 speedup을 기록했다.
Figure 8: 101개 언어에 대한 다국어 사전학습. 각 언어에 대해, 동일한 품질에 도달하기 위한 FLOP이 일치하는 T5 dense baseline 대비 Switch Transformer의 step speedup을 히스토그램으로 나타냈다. 101개 언어 전체에서 mT5-Base 대비 평균 5배의 step speedup을 달성했으며, 91%의 언어에서 mT5-Base의 최종 perplexity에 도달하기 위해 4배 이상의 speedup을 기록했다.
Feed-Forward Network (FFN) Layer 검토
우리는 FFN layer를 Mesh TensorFlow (Shazeer et al., 2018)에서 데이터, 모델, 전문가 병렬화가 어떻게 작동하는지를 설명하는 예시로 사용하며, 여기서 간략하게 검토한다.
배치에는 개의 토큰이 있으며, 각 토큰의 차원은 이라고 가정한다. FFN의 입력()과 출력()은 모두 크기이며, 중간(intermediate) 는 크기이다. 여기서 는 일반적으로 보다 몇 배 더 크다. FFN에서 중간 값은 이고, layer의 출력은 이다. 따라서 과 는 각 토큰에 독립적으로 적용되며, 크기는 각각 와 이다.
우리는 파티셔닝의 두 가지 측면을 설명한다: 가중치와 데이터 배치가 코어에 어떻게 분할되는지를 Figure 9에 나타냈다.
사용 가능한 모든 코어를 으로 표시하며, Mesh Tensorflow는 이를 논리적인 다차원 프로세서 메쉬로 재매핑할 수 있다. 여기서 우리는 두 가지 차원을 가진 논리적인 메쉬를 생성한다. 한 차원은 **데이터 병렬 샤딩(data-parallel sharding) 방식의 수()**를 나타내고, 다른 차원은 **모델 병렬 샤딩(model-parallel sharding) 방식의 수()**를 나타낸다.
총 코어 수는 데이터 및 모델 병렬화에 걸쳐 샤딩하는 방식의 수와 같아야 한다. 예를 들어, 이다.
layer를 코어에 걸쳐 샤딩하기 위해, 개의 토큰을 포함하는 배치 텐서는 개의 데이터 병렬 코어에 걸쳐 샤딩되므로, 각 코어는 개의 토큰을 포함한다.
를 가진 텐서와 변수는 개의 모델 병렬 코어에 걸쳐 샤딩된다.
전문가 layer를 포함하는 변형의 경우, 우리는 개의 전문가를 고려하며, 각 전문가는 최대 개의 토큰을 처리할 수 있다.
| Term | Description |
|---|---|
| 배치 내 토큰 수. | |
| 총 코어 수. | |
| 데이터 병렬 샤딩 방식의 수. | |
| 모델 병렬 샤딩 방식의 수. | |
| Switch layer 내 전문가 수. | |
| 전문가 용량(Expert capacity), 각 전문가의 배치 크기. |
5.1 Data Parallelism
데이터 병렬 모델을 학습할 때, 이는 분산 학습의 표준 방식인데, 모든 코어는 데이터 병렬 차원()에 할당된다. 이 방식은 전체 forward 및 backward pass가 완료되고 모든 코어에 걸쳐 gradient를 집계해야 할 때까지는 통신이 필요 없다는 장점이 있다. 이는 Figure 9의 가장 왼쪽 열에 해당한다.
5.2 Model Parallelism
이제 모든 코어가 모델 병렬(model-parallel) 차원에만 독점적으로 할당되어 인 시나리오를 고려해보자. 이 경우 모든 코어는 전체 토큰을 유지해야 하며, 각 코어는 가중치(weights)의 고유한 슬라이스를 포함하게 된다.
각 forward 및 backward pass마다 **통신 비용(communication cost)**이 발생한다.
각 코어는 두 번째 행렬 곱셈인 을 계산하기 위해 크기의 텐서를 전송한다. 이는 차원이 분할되어 있고, 이 분할된 차원에 대해 합산(sum)이 필요하기 때문이다.
일반적으로, 코어 간에 분할된 차원을 합산해야 할 때마다 forward 및 backward pass 모두에 all-reduce 연산이 추가된다. 이는 순수한 데이터 병렬(pure data parallelism) 방식에서 all-reduce가 전체 forward 및 backward pass의 끝에서만 발생하는 것과 대조된다.
How the model weights are split over cores
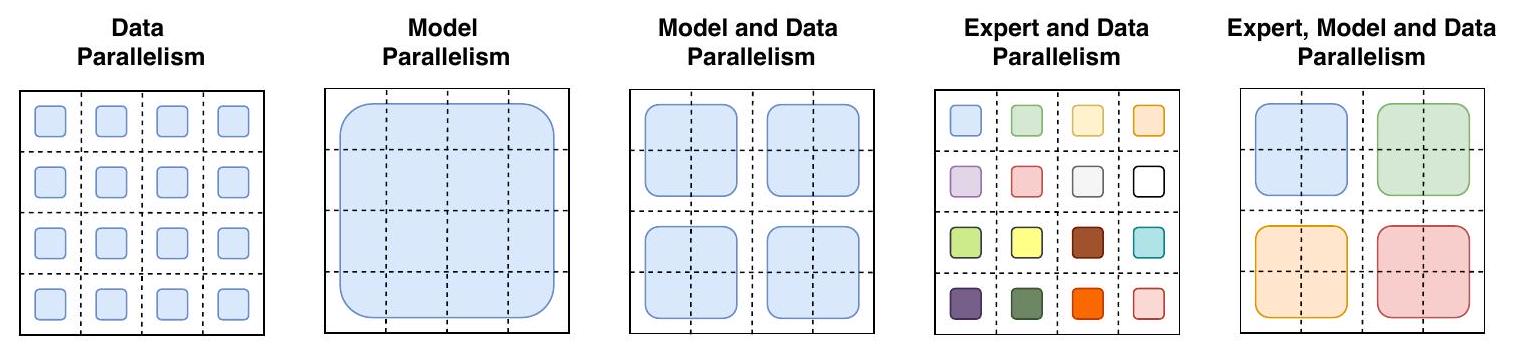
데이터가 코어에 분할되는 방식
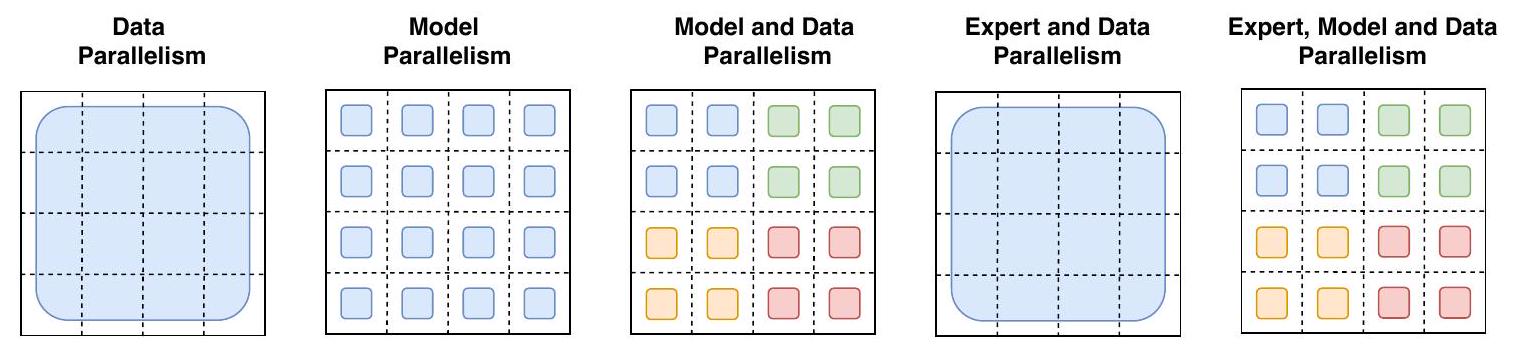
Figure 9: 데이터 및 가중치 분할 전략.
각 점선 격자는 16개의 코어를 나타내며, 음영 처리된 사각형은 **해당 코어에 포함된 데이터(모델 가중치 또는 토큰 배치)**를 의미한다. 우리는 각 전략에 대해 모델 가중치와 데이터 텐서가 어떻게 분할되는지를 보여준다.
첫 번째 행: 모델 가중치가 코어에 어떻게 분할되는지를 보여준다. 이 행의 다양한 크기의 도형은 Feed Forward Network (FFN) layer의 더 큰 가중치 행렬(예: 더 큰 크기)을 나타낸다. 음영 처리된 사각형의 각 색상은 고유한 가중치 행렬을 식별한다. 코어당 파라미터 수는 고정되어 있지만, 더 큰 가중치 행렬은 각 토큰에 더 많은 연산을 적용한다.
두 번째 행: 데이터 배치가 코어에 어떻게 분할되는지를 보여준다. 각 코어는 동일한 수의 토큰을 보유하며, 이는 모든 전략에서 고정된 메모리 사용량을 유지한다. 분할 전략은 각 코어가 동일한 토큰을 가질지 또는 코어마다 다른 토큰을 가질지에 대한 다른 속성을 가지며, 이는 다른 색상으로 상징된다.
5.3 Model and Data Parallelism
대규모 모델의 경우 모델 병렬화(model parallelism)와 데이터 병렬화(data parallelism)를 혼합하는 것이 일반적이며, 이는 가장 큰 T5 모델 (Raffel et al., 2019; Xue et al., 2020)과 GPT-3 (Brown et al., 2020)에서 사용되었다. 총 개의 코어를 사용할 때, 각 코어는 개의 token과 의 가중치 및 중간 활성화(intermediate activation)를 담당하게 된다. forward 및 backward pass에서 각 코어는 all-reduce 연산을 통해 크기의 텐서를 통신한다.
5.4 Expert and Data Parallelism
다음으로 expert 및 데이터 병렬화(data parallelism)를 위한 파티셔닝 전략에 대해 설명한다. Switch Transformer는 모든 코어를 **데이터 파티셔닝 차원 **에 할당하며, 이는 모델의 expert 수와도 일치한다. 각 코어의 토큰에 대해 router는 expert 할당을 로컬에서 계산한다. 출력은 크기의 이진 행렬이며, 이는 첫 번째 차원을 따라 파티셔닝되고 expert 할당을 결정한다. 이 이진 행렬은 크기의 입력 텐서와 행렬 곱셈을 통해 gather하는 데 사용된다.
그 결과 형태의 최종 텐서가 생성되며, 이는 첫 번째 차원을 따라 샤딩된다. 각 코어는 자체 expert를 가지고 있으므로, 이제 차원 대신 차원을 샤딩하기 위해 크기의 all-to-all 통신을 수행한다. forward pass에서는 다른 코어에 위치한 각 expert로부터 토큰을 유사하게 수신하기 위해 크기의 bfloat16 텐서에 대한 추가적인 통신 비용이 발생한다. expert 파티셔닝 코드에 대한 자세한 분석은 Appendix F를 참조하라.
5.5 Expert, Model and Data Parallelism
최적의 모델을 설계할 때, 우리는 토큰당 FLOPS와 파라미터 수의 균형을 맞추고자 한다. expert의 수를 늘리면 파라미터 수는 증가하지만, 토큰당 FLOPS는 변하지 않는다. FLOPS를 늘리려면 차원도 늘려야 하는데 (이는 파라미터도 증가시키지만, 더 느린 속도로 증가한다), 여기서 trade-off가 발생한다. 를 늘리면 코어당 메모리가 부족해지므로 을 늘려야 한다. 그러나 고정된 코어 수 과 이라는 관계 때문에 을 줄여야 하고, 이는 더 작은 batch-size를 사용하도록 강제한다 (코어당 토큰 수를 일정하게 유지하기 위해).
모델 병렬화와 expert 병렬화를 결합할 경우, 토큰을 올바른 expert로 라우팅하는 과정에서 발생하는 all-to-all 통신 비용과 모델 병렬화로 인한 내부 all-reduce 통신 비용이 모두 발생한다. 이 세 가지 방법을 모두 결합할 때 FLOPS, 통신 비용, 코어당 메모리 간의 균형을 맞추는 것은 매우 복잡해지며, 최적의 매핑은 경험적으로 결정된다. expert 수가 다운스트림 성능에 미치는 영향에 대한 추가 분석은 섹션 5.6을 참조하라.
5.6 Towards Trillion Parameter Models
expert, model, data parallelism을 결합하여, 우리는 각각 3,950억 개와 1조 6천억 개의 파라미터를 가진 두 개의 대규모 Switch Transformer 모델을 설계했다. 우리는 이 모델들이 언어 모델로서의 upstream pre-training과 downstream fine-tuning 성능에서 어떻게 작동하는지 연구한다. 두 모델의 파라미터, 시퀀스당 FLOPs, 하이퍼파라미터는 아래 Table 9에 나열되어 있다. Transformer의 표준 하이퍼파라미터인 , head 수, layer 수와 함께, 덜 일반적인 특징인 도 설명되어 있다. 는 확장 행렬이 비선형적으로 결합된 두 세트의 가중치로 대체되는 FFN layer의 변형을 의미한다 (Shazeer, 2020).
Switch-C 모델은 Section 5.4에서 이전에 설명했듯이 expert-parallelism만을 사용하여 설계되었으며, model-parallelism은 사용되지 않았다. 그 결과, 너비, 깊이, head 수 등을 제어하는 하이퍼파라미터는 T5-XXL 모델보다 훨씬 작다. 반대로, Switch-XXL은 T5-XXL 모델과 FLOPs가 일치하도록 설계되어 더 큰 하이퍼파라미터 차원을 허용하지만, model-parallelism으로 인한 추가적인 통신 비용이 발생한다 (자세한 내용은 Section 5.5 참조).
| Model | Parameters | FLOPs/seq | Num. Heads | ||||
|---|---|---|---|---|---|---|---|
| T5-Base | 0.2 B | 124 B | 768 | 2048 | 64 | 12 | |
| T5-Large | 0.7 B | 425B | 1024 | 2816 | 64 | 16 | |
| T5-XXL | 11 B | 6.3 T | 4096 | 10240 | 64 | 64 | |
| Switch-Base | 7B | 124 B | 768 | 2048 | 64 | 12 | |
| Switch-Large | 26B | 425 B | 1024 | 2816 | 64 | 16 | |
| Switch-XXL | 395B | 6.3 T | 4096 | 10240 | 64 | 64 | |
| Switch-C | 1571 B | 890 B | 2080 | 6144 | 64 | 32 | |
| Model | Expert Freq. | Num. Layers | Num Experts | Neg. Log Perp. @250k | Neg. Log Perp. @ 500k | ||
| T5-Base | - | 12 | - | -1.599 | -1.556 | ||
| T5-Large | - | 24 | - | -1.402 | -1.350 | ||
| T5-XXL | - | 24 | - | -1.147 | -1.095 | ||
| Switch-Base | 1/2 | 12 | 128 | -1.370 | -1.306 | ||
| Switch-Large | 1/2 | 24 | 128 | -1.248 | -1.177 | ||
| Switch-XXL | 1/2 | 24 | 64 | -1.086 | -1.008 | ||
| Switch-C | 1 | 15 | 2048 | -1.096 | -1.043 |
Table 9: Switch 모델 설계 및 사전학습 성능. T5 모델과 Switch Transformer 변형 모델의 하이퍼파라미터 및 사전학습 성능을 비교한다. 마지막 두 열은 각각 250k 및 500k 스텝 후 C4 데이터셋에 대한 사전학습 모델 품질을 기록한다. Switch-C Transformer 변형 모델은 T5-XXL 모델보다 고정된 perplexity에 도달하는 데 4배 더 빠르며(동일한 연산 예산으로), 학습이 진행될수록 그 격차는 커진다.
T5-XXL 대비 sample efficiency. Table 9의 마지막 두 열에는 각각 250k 및 500k 스텝 후 C4 코퍼스에 대한 negative log perplexity가 기록되어 있다. 250k 스텝 후, 우리는 두 Switch Transformer 변형 모델 모두 T5-XXL 버전의 negative log perplexity를 0.061 이상 개선했음을 발견했다. 0.061의 격차가 가지는 중요성을 설명하자면, T5-XXL 모델은 0.052를 개선하기 위해 추가로 250k 스텝을 학습해야 했다. 이 격차는 추가 학습과 함께 계속 증가하여, 500k 스텝에서는 Switch-XXL 모델이 T5-XXL을 0.087만큼 능가했다.
학습 불안정성. 그러나 서론에서 설명했듯이, 대규모 sparse 모델은 불안정할 수 있으며, 규모가 커질수록 산발적인 문제가 발생한다. 우리는 1.6T 파라미터와 2048 expert를 가진 더 큰 Switch-C 모델이 전혀 학습 불안정성을 보이지 않음을 발견했다. 대신, 시퀀스당 FLOPs가 거의 10배 더 큰 Switch-XXL 버전은 때때로 불안정하다. 그 결과, 스텝 기준으로는 이 모델이 더 우수하지만, T5의 최종 보고된 결과(Raffel et al., 2019)와 일치하게 전체 1M 스텝 동안 사전학습하지 않았다.
Reasoning fine-tuning 성능. 모델 품질의 예비 평가로, 우리는 T5-XXL 모델이 사용한 텍스트의 약 절반인 503B 토큰으로 부분적으로 사전학습된 Switch-XXL 모델을 사용했다. 이 체크포인트를 사용하여, 개별적으로 fine-tuning하는 대신 모든 task를 함께 학습하는 multi-task training을 효율성을 위해 수행했다. 우리는 SQuAD 검증 세트의 정확도가 89.7로 증가했으며, 이는 state-of-the-art인 91.3과 비교된다. 다음으로, 평균 SuperGLUE 테스트 점수는 87.5로 기록되었으며, T5 버전은 89.3점을 얻었고, state-of-the-art는 90.0점이다 (Wang et al., 2019). ANLI (Nie et al., 2019)에서는 Switch-XXL이 이전 state-of-the-art를 능가하여 65.7의 정확도를 얻었으며, 이전 최고 기록은 49.4였다 (Yang et al., 2020). 우리는 Switch-XXL이 upstream pre-training task에서 state-of-the-art negative log perplexity를 달성했음에도 불구하고, 그 이점이 아직 SOTA downstream 성능으로 완전히 전환되지 않았음을 주목한다. 이 문제는 Appendix E에서 더 자세히 연구한다.
Knowledge-based fine-tuning 성능. 마지막으로, 우리는 Salient Span Masking (Guu et al., 2020)을 사용한 추가 사전학습 없이 세 가지 closed-book knowledge-based task인 Natural Questions, WebQuestions, TriviaQA에 대한 모델의 지식을 조기에 검토했다. 세 가지 경우 모두에서, 우리는 이전 state-of-the-art T5-XXL 모델(SSM 없음)보다 개선된 결과를 관찰했다. Natural Questions의 exact match는 이전 최고 기록인 32.8에서 34.4로 증가했으며, Web Questions는 37.2에서 41.0으로, TriviaQA는 42.9에서 47.5로 증가했다.
요약하자면, 다른 모델의 절반 미만의 데이터로 학습했음에도 불구하고, 우리는 이미 비슷하거나 때로는 state-of-the-art 수준의 모델 품질을 발견했다. 현재 Switch Transformer는 upstream에서의 상당한 이점을 reasoning task보다 knowledge-based task에 더 잘 전환한다 (Appendix E 참조). 대규모 expert 모델에서 더 강력한 fine-tuning 성능을 추출하는 것은 활발한 연구 질문이며, 사전학습 perplexity는 향후 개선 가능성이 있음을 시사한다.
6. Related Work
신경망에서 규모(scale)의 중요성은 널리 인식되어 왔으며, 이를 위한 여러 접근 방식이 제안되었다. 최근 연구들은 모델 병렬화(model parallelism)(예: 여러 코어에 걸쳐 가중치와 텐서를 분할)를 통해 모델을 수십억 개의 파라미터로 확장했다 (Shazeer et al., 2018; Rajbhandari et al., 2019; Raffel et al., 2019; Brown et al., 2020; Shoeybi et al., 2019). 대안적으로, Harlap et al. (2018); Huang et al. (2019)는 파이프라인 기반 모델 병렬화를 제안했는데, 이는 서로 다른 layer를 여러 장치에 분할하고 마이크로 배치(micro-batch)를 각 layer로 파이프라인 처리하는 방식이다. 마지막으로, Product Key network (Lample et al., 2019)는 주어진 layer로 들어오는 토큰 표현(token representation)을 기반으로 학습 가능한 임베딩을 조회(lookup)함으로써 신경망의 용량(capacity)을 확장하는 방법을 제안했다.
우리의 연구는 **조건부 연산(conditional computation)**을 수행하는 방법론 중 특정 모델을 다룬다. 조건부 연산에서는 입력에 따라 연산 결정이 동적으로 이루어진다. Cho and Bengio (2014)는 모델의 hidden-state에 나타나는 특정 비트 패턴을 기반으로 가중치를 적응적으로 선택하는 방법을 제안했다. Eigen et al. (2013)은 dense matrix multiplication과 ReLU activation을 사용하는 stacked expert layer를 구축하여 jittered MNIST 및 monotone speech에서 유망한 결과를 보여주었다. 컴퓨터 비전 분야에서는 Puigcerver et al. (2020)이 업스트림 사전학습(upstream pre-training) 동안 의미론적 클래스(semantic class)를 기반으로 토큰을 수동으로 라우팅하고, 다운스트림 task에 따라 사용될 관련 expert를 선택하는 방식을 사용했다.
현대 딥러닝 아키텍처 맥락에서 **Mixture of Experts (MoE)**는 Shazeer et al. (2017)에 의해 그 효과가 입증되었다. 이 연구는 LSTM (Hochreiter and Schmidhuber, 1997) layer 사이에 MoE layer를 추가하고, 토큰들을 expert 조합으로 개별적으로 라우팅했다. 이는 언어 모델링 및 기계 번역 벤치마크에서 state-of-the-art 결과를 가져왔다. MoE layer는 Mesh Tensorflow 라이브러리 (Shazeer et al., 2018)에 의해 Transformer 아키텍처에 재도입되었는데, 여기서 MoE layer는 FFN layer의 대체재로 도입되었지만, 관련 NLP 결과는 제시되지 않았다. 최근에는 머신러닝 인프라의 발전 덕분에 XLA 컴파일러를 확장한 GShard (Lepikhin et al., 2020)가 MoE Transformer를 사용하여 100개 언어에 걸쳐 기계 번역 성능을 극적으로 향상시켰다. 마지막으로 Fan et al. (2021)은 모델 파라미터를 겹치지 않는 언어 그룹으로 분할하기 위해 다른 결정론적 MoE 전략을 선택했다.
Transformer attention 패턴에서 **시퀀스 길이(L) 차원을 따른 희소성(sparsity)**은 attention 복잡도를 에서 줄이는 성공적인 기술이었다 (Child et al., 2019; Correia et al., 2019; Sukhbaatar et al., 2019; Kitaev et al., 2020; Zaheer et al., 2020; Beltagy et al., 2020). 이는 이전에는 불가능했던 더 긴 시퀀스를 학습할 수 있게 했다. 이 버전의 Switch Transformer는 attention sparsity를 사용하지 않지만, 이러한 기술들은 상호 보완적이며, 향후 연구로 이들을 결합하여 긴 context를 요구하는 task의 학습을 잠재적으로 개선할 수 있을 것이다.
7. Discussion
우리는 Switch Transformer와 희소(sparse) expert model 전반에 걸쳐 질문을 제기하고 논의한다. 여기서 **희소성(sparsity)**은 attention 패턴이 아닌 가중치(weights)에 대한 것이다.
Switch Transformer가 단순히 파라미터 수 때문에 더 나은가요?
네, 그리고 이는 설계 의도입니다! 총 FLOPs 사용량과 무관하게, 파라미터 수는 신경 언어 모델을 확장하는 데 유용한 축입니다. 대규모 모델이 더 나은 성능을 보인다는 것은 이미 철저히 입증되었습니다 (Kaplan et al., 2020). 하지만 이 경우, 우리의 모델은 동일한 연산 자원을 사용하면서도 더 sample efficient하고 더 빠릅니다.
슈퍼컴퓨터에 접근할 수 없는데, 그래도 이 기술이 유용할까요?
본 연구는 극도로 큰 모델에 초점을 맞추었지만, 단 두 개의 expert만으로도 성능이 향상되며, 이는 일반적으로 사용 가능한 GPU나 TPU의 메모리 제약 내에서 쉽게 작동함을 발견했습니다 (자세한 내용은 Appendix D 참조). 따라서 우리는 우리의 기술이 소규모 환경에서도 유용하다고 믿습니다.
희소 모델이 속도-정확도 Pareto 곡선에서 밀집 모델보다 우수한가요?
네, 그렇습니다. 다양한 모델 크기 전반에 걸쳐, 희소 모델은 단계별(per step) 및 실제 시간(wall clock time) 기준으로 밀집 모델보다 우수한 성능을 보입니다. 우리의 통제된 실험은 고정된 연산량과 시간 내에서 희소 모델이 밀집 모델보다 더 나은 성능을 보인다는 것을 보여줍니다.
수조 개의 파라미터를 가진 모델을 배포할 수 없는데, 이 모델들을 축소할 수 있을까요?
모델 품질을 완전히 보존할 수는 없지만, expert 모델의 품질 향상분의 약 30%를 달성하면서도, 희소 모델을 밀집 모델로 증류(distill)하여 10배에서 100배의 압축률을 달성할 수 있습니다.
모델 병렬 밀집 모델 대신 Switch Transformer를 사용하는 이유는 무엇인가요?
시간 기준으로 볼 때, Switch Transformer는 sharded 파라미터를 가진 밀집 모델보다 훨씬 더 효율적일 수 있습니다 (Figure 6). 또한, 이 결정은 상호 배타적이지 않다는 점을 지적합니다. 우리는 Switch Transformer에서 모델 병렬화를 사용할 수 있으며 실제로 사용하고 있으며, 이는 토큰당 FLOPs를 증가시키지만, 기존 모델 병렬화의 속도 저하를 수반합니다.
희소 모델이 아직 널리 사용되지 않는 이유는 무엇인가요?
희소 모델을 시도하려는 동기는 밀집 모델의 엄청난 확장 성공으로 인해 방해받아왔습니다 (이 성공은 Hooker (2020)에서 주장했듯이 딥러닝 하드웨어와의 공동 적응(co-adaptation)에 부분적으로 기인한다). 또한, 희소 모델은 (1) 모델 복잡성, (2) 학습의 어려움, (3) 통신 비용을 포함한 여러 문제에 직면해왔다. Switch Transformer는 이러한 문제들을 완화하기 위해 노력한다.
8. Future Work
본 논문은 단순화된 아키텍처, 개선된 학습 절차, 그리고 sparse 모델의 확장성 연구를 제시한다. 그러나 여전히 많은 미해결된 미래 연구 방향이 남아 있으며, 이를 간략하게 설명한다:
- 가장 큰 모델의 학습 안정성을 더욱 향상시키는 것은 중요한 도전 과제이다. 우리의 안정화 기법은 Switch-Base, Switch-Large, Switch-C 모델에는 효과적이었지만 (불안정성 관찰되지 않음), Switch-XXL에는 충분하지 않았다. 우리는 이러한 모델들을 안정화하기 위한 초기 단계를 밟았으며, 이는 안정성 향상을 위한 regularizer 사용 및 gradient clipping의 변형된 형태 적용 등 대규모 모델에 일반적으로 유용할 수 있다고 생각하지만, 아직 해결되지 않은 문제로 남아 있다.
- 일반적으로 우리는 사전학습(pre-training) 품질이 향상되면 다운스트림 결과도 더 좋아진다는 것을 발견했지만 (Appendix E), 때로는 놀라운 이상 현상에 직면하기도 한다. 예를 들어, C4 데이터셋 모델링에서 유사한 perplexity를 보였음에도 불구하고, 1.6T 파라미터의 Switch-C는 SQuAD에서 87.7의 exact match 점수만을 달성했는데, 이는 더 작은 Switch-XXL 모델의 89.6에 비해 좋지 않은 결과이다. 한 가지 주목할 만한 차이점은 Switch-XXL 모델이 Switch-C 모델보다 토큰당 약 10배 많은 FLOPS를 적용한다는 점이다. 이는 Switch-XXL이 Switch-C보다 약 4배 적은 고유 파라미터(395B vs 1.6T)를 가졌음에도 불구하고 그렇다. 이는 fine-tuning 품질, 토큰당 FLOPS, 그리고 파라미터 수 사이에 아직 잘 이해되지 않은 의존성이 있음을 시사한다.
- 데이터, 모델, expert-parallelism을 혼합한 아키텍처 설계를 안내하기 위한 확장 관계에 대한 포괄적인 연구를 수행해야 한다. 이상적으로는 하드웨어 구성(연산, 메모리, 통신)의 사양이 주어졌을 때, 최적의 모델을 더 빠르게 설계할 수 있을 것이다. 그리고 역으로, 이는 미래 하드웨어 설계에도 도움이 될 수 있다.
- 우리의 연구는 adaptive computation algorithm 계열에 속한다. 우리의 접근 방식은 항상 동일하고 동질적인 expert를 사용했지만, 미래 설계(더 유연한 인프라에 의해 촉진될)는 이질적인 expert를 지원할 수 있을 것이다. 이는 더 많은 연산이 필요할 때(예: 더 어려운 예시의 경우) 더 큰 expert로 라우팅함으로써 더 유연한 적응을 가능하게 할 것이다.
- Transformer의 FFN layer 외부에서 expert layer를 탐구하는 것이다. 우리는 이것이 유사하게 모델 품질을 향상시킬 수 있다는 예비 증거를 발견했다. Appendix A에서 우리는 Self-Attention layer 내부에 expert layer를 추가하여 품질이 향상되었음을 보고했는데, 여기서 우리의 layer는 를 생성하는 가중치 행렬을 대체한다. 그러나 bfloat16 형식에서의 학습 불안정성으로 인해, 이 부분은 미래 연구 영역으로 남겨둔다.
- 새로운 모달리티 및 다양한 모달리티에 걸쳐 Switch Transformer를 검토하는 것이다. 우리는 지금까지 언어만을 고려했지만, 모델 sparsity가 새로운 모달리티뿐만 아니라 멀티모달 네트워크에서도 유사한 이점을 제공할 수 있다고 믿는다.
이 목록은 쉽게 확장될 수 있지만, 우리는 이것이 우리가 고민하고 있는 도전 과제와 유망하다고 생각하는 미래 방향에 대한 아이디어를 제공하기를 바란다.
9. Conclusion
Switch Transformer는 확장 가능하고 효과적인 자연어 학습 모델이다. 우리는 Mixture of Experts를 단순화하여 이해하기 쉽고, 학습이 안정적이며, 동일한 크기의 dense 모델보다 **샘플 효율성(sample efficient)**이 훨씬 뛰어난 아키텍처를 만들었다. 이러한 모델들은 사전학습(pre-training), fine-tuning, multi-task training을 포함한 다양한 학습 환경과 광범위한 자연어 task에서 뛰어난 성능을 보인다. 이러한 발전 덕분에 수천억에서 수조 개의 파라미터를 가진 모델을 학습할 수 있게 되었으며, dense T5 baseline 대비 상당한 속도 향상을 달성했다. 우리는 본 연구가 sparse 모델이 효과적인 아키텍처임을 입증하고, 연구자와 실무자들이 자연어 task뿐만 아니라 다른 분야에서도 이러한 유연한 모델을 고려하도록 장려하기를 바란다.
Acknowledgments
저자들은 수개월간 알고리즘 개선에 대한 핵심적인 통찰력과 경험적 연구에 대한 제안을 제공해 준 Margaret Li에게 감사드린다. 초고에 대한 현명한 조언과 명확한 의견을 제시해 준 Hugo Larochelle, 상세한 의견과 세심한 수정을 해 준 Irwan Bello, 신경망 language model 및 T5 코드베이스에 대한 시기적절한 조언을 해 준 Colin Raffel과 Adam Roberts, adaptive computation 연구에 대한 조언과 격려를 해 준 Yoshua Bengio, 새로운 대규모 모델의 안정화 및 논문 수정에 대한 흥미로운 새로운 방향을 제시해 준 Jascha Sohl-dickstein, 그리고 논문에 대한 유익한 토론을 해 준 Google Brain Team에 감사드린다. 또한, 우리 모델의 학습 성능을 프로파일링하고 개선하는 데 귀중한 도움을 준 Blake Hechtman에게도 감사드린다.
A. Switch for Attention
Shazeer et al. (2018)와 Lepikhin et al. (2020)은 Transformer의 dense feed-forward network (FFN) 연산에 MoE layer를 추가하여 MoE Transformer를 설계했다 (Shazeer et al., 2017). 이와 유사하게, 본 연구도 Transformer의 FFN layer를 대체했지만, 여기서는 대체 설계 방식을 간략하게 탐구한다. 우리는 Transformer의 Self-Attention layer에 Switch layer를 추가한다. 이를 위해, Figure 10에서 볼 수 있듯이 query, key, value를 생성하는 학습 가능한 가중치 행렬을 Switch layer로 대체한다.
Table 10은 고정된 스텝 수 이후의 품질과 여러 변형 모델의 학습 시간을 기록한다. 개선점을 발견했지만, bfloat16 정밀도를 사용할 때 이 layer들이 더 불안정하다는 것을 확인하여 최종 모델에는 포함하지 않았다.
 Figure 10: Attention 내의 Switch layer. Self-Attention Transformer 블록에 Switch layer를 통합하는 방법을 도식화했다. 각 토큰(여기서는 "More"와 "Parameters" 두 개의 토큰을 보여줌)에 대해, 한 세트의 가중치는 query를 생성하고, 다른 세트의 고유한 가중치는 공유된 key와 value를 생성한다. 우리는 각 expert가 선형 연산인 경우와 본 연구 전반에서 사용된 FFN인 경우를 모두 실험했다. 이를 통해 품질 개선을 확인했지만, 낮은 정밀도 숫자 형식과 함께 사용할 때 더 불안정하다는 것을 발견하여 이 부분은 향후 연구로 남겨둔다.
Figure 10: Attention 내의 Switch layer. Self-Attention Transformer 블록에 Switch layer를 통합하는 방법을 도식화했다. 각 토큰(여기서는 "More"와 "Parameters" 두 개의 토큰을 보여줌)에 대해, 한 세트의 가중치는 query를 생성하고, 다른 세트의 고유한 가중치는 공유된 key와 value를 생성한다. 우리는 각 expert가 선형 연산인 경우와 본 연구 전반에서 사용된 FFN인 경우를 모두 실험했다. 이를 통해 품질 개선을 확인했지만, 낮은 정밀도 숫자 형식과 함께 사용할 때 더 불안정하다는 것을 발견하여 이 부분은 향후 연구로 남겨둔다.
그러나 이러한 layer들이 안정적으로 학습될 경우, 예비적인 긍정적 결과는 향후 유망한 방향을 제시한다고 믿는다.
| Model | Precision | Quality @100k Steps ( ) | Quality | Speed |
|---|---|---|---|---|
| Experts FF | float32 | -1.548 | -1.614 | 1480 |
| Expert Attention | float32 | -1.524 | -1.606 | 1330 |
| Expert Attention | bfloat16 | [diverges] | [diverges] | - |
| Experts FF + Attention | float32 | -1.513 | -1.607 | 1240 |
| Expert FF + Attention | bfloat16 | [diverges] | [diverges] | - |
Table 10: Switch attention layer 결과. 모든 모델은 32개의 expert를 가지며, 배치당 524k 토큰으로 학습된다. Experts FF는 expert가 Transformer의 FFN을 대체하는 경우로, 본 논문 전반에 걸친 표준 설정이다. Experts FF + Attention은 expert가 FFN과 Self-Attention layer를 모두 대체하는 경우이다. bfloat16 정밀도로 학습할 때 expert attention을 포함하는 모델은 발산한다.
B. Preventing Token Dropping with No-Token-Left-Behind
TPU 가속기의 소프트웨어 제약으로 인해, 우리 모델의 Tensor 형태는 정적으로(statically) 크기가 결정되어야 한다. 결과적으로, 각 expert는 **token representation을 처리할 수 있는 유한하고 고정된 용량(capacity)**을 갖게 된다. 그러나 이는 런타임에 token을 동적으로 라우팅하는 우리 모델에 문제를 야기할 수 있으며, 이는 expert들 간의 불균등한 분포로 이어질 수 있다.
만약 expert로 전송되는 token 수가 expert 용량보다 적다면, 연산은 단순히 **패딩(padding)**될 수 있다. 이는 하드웨어의 비효율적인 사용이지만, 수학적으로는 올바르다. 하지만 expert로 전송되는 token 수가 용량을 초과할 경우 (expert overflow), 이를 처리하기 위한 프로토콜이 필요하다. Lepikhin et al. (2020)은 Mixture-of-Expert 모델을 수정하여 expert overflow를 처리하는데, 이들은 residual connection을 통해 해당 representation을 다음 layer로 처리 없이 전달하는 방식을 사용하며, 우리도 이 방식을 따른다.
우리는 token에 아무런 연산도 적용되지 않는 것이 매우 비효율적일 수 있다고 생각했다. 특히 한 expert에서 overflow가 발생하면, 다른 expert는 여분의 용량을 가질 것이기 때문이다. 이러한 직관을 바탕으로 우리는 No-Token-Left-Behind라는 방법을 고안했다. 이 방법은 처음에 overflow가 발생한 expert로 라우팅된 모든 token들을 반복적으로 재라우팅한다. Figure 11은 이 방법의 그래픽 설명을 보여주며, 이를 통해 학습 및 추론 과정에서 거의 모든 token이 드롭되지 않도록 보장할 수 있다. 우리는 이 방법이 성능을 향상시키고 학습을 더욱 안정화할 수 있을 것이라고 가설을 세웠지만, 실험적으로는 어떠한 이점도 발견하지 못했다. 우리는 네트워크가 서로 다른 token과 expert 간의 연관성을 학습한 후에는, 이러한 연관성이 변경될 경우 (예: token을 두 번째로 높은 expert로 보내는 경우) 성능이 저하될 수 있다고 추측한다.
C. Encouraging Exploration Across Experts
각 expert-layer에서 router는 토큰을 어떤 expert에게 보낼지 결정한다. 이는 토큰의 표현(representation)에 대한 정보에 기반한, 사용 가능한 expert들에 대한 이산적인 결정이다.
들어오는 토큰 표현에 따라 router는 최적의 expert를 결정하지만, 다른 expert를 선택했을 때 얼마나 잘 수행했을지에 대한 counterfactual 정보는 받지 못한다.
이는 강화 학습(reinforcement learning)에서와 같이 고전적인 탐색-활용(exploration-exploitation) 딜레마를 야기한다 (Sutton and Barto, 2018).
이러한 문제들은 Rosenbaum et al. (2017)에 의해 유사하게 지적되었고, 그들은 multi-task learning에서 성공적인 다른 해결책을 제시했다. 이 특정 설정은 contextual bandit (Robbins, 1952)의 경우와 가장 유사하다.
최고의 expert를 항상 결정론적으로 선택하는 것은 항상 활용(exploitative) 전략에 해당한다. 우리는 더 나은 expert 할당을 찾기 위한 탐색(exploration)의 균형을 고려한다.
탐색을 도입하기 위해 우리는 몇 가지 접근 방식을 고려한다:
- 결정론적(deterministic) 또는 argmax
- softmax 분포에서 샘플링
- 들어오는 표현에 대한 input dropout
- 들어오는 표현에 대한 multiplicative jitter noise
모델 품질에 미치는 결과적인 영향은 Table 11에 보고되어 있다. 본 연구 전반에 걸쳐 우리는 input jitter를 사용하여 노이즈를 주입하는데, 이는 경험적으로 가장 좋은 성능을 보였기 때문이다.
D. Switch Transformers in Lower Compute Regimes
Switch Transformer는 수천 개의 코어와 수조 개의 파라미터를 사용하는 대규모 환경뿐만 아니라 작은 규모에서도 효과적인 아키텍처이다. 우리의 이전 실험 중 상당수는
 Figure 11: No-Token-Left-Behind Routing 다이어그램.
Stage 1은 Switch routing과 동일하며, 토큰들은 router로부터 가장 높은 확률을 가진 expert로 라우팅된다.
Stage 2에서는 overflow된 모든 토큰들을 확인하고, 두 번째로 높은 확률을 가진 expert로 라우팅한다.
두 번째로 높은 expert에도 너무 많은 토큰이 있다면 여전히 overflow될 수 있지만, 이 방식을 통해 대부분의 토큰이 라우팅될 수 있다.
이 과정은 거의 모든 토큰이 드롭되지 않도록 보장하기 위해 반복될 수 있다.
Figure 11: No-Token-Left-Behind Routing 다이어그램.
Stage 1은 Switch routing과 동일하며, 토큰들은 router로부터 가장 높은 확률을 가진 expert로 라우팅된다.
Stage 2에서는 overflow된 모든 토큰들을 확인하고, 두 번째로 높은 확률을 가진 expert로 라우팅한다.
두 번째로 높은 expert에도 너무 많은 토큰이 있다면 여전히 overflow될 수 있지만, 이 방식을 통해 대부분의 토큰이 라우팅될 수 있다.
이 과정은 거의 모든 토큰이 드롭되지 않도록 보장하기 위해 반복될 수 있다.
| Model | Quality (Neg. Log Perp.) ( ) |
|---|---|
| Argmax | -1.471 |
| Sample softmax | -1.570 |
| Input dropout | -1.480 |
| Input jitter |
Table 11: Router 탐색 전략. expert를 선택하는 다양한 무작위성 전략에 따른 Switch Transformer의 품질을 negative log perplexity로 측정하였다 (낮을수록 좋음). 각 변형 간에 실질적인 속도 성능 차이는 없다.
10B+ 파라미터 모델 규모에서 이루어졌지만, Figure 12에서 보듯이 단 2개의 expert만으로도 FLOP이 일치하는 dense 모델 대비 상당한 성능 향상을 보여준다. 설령 슈퍼컴퓨터를 쉽게 사용할 수 없더라도, 2개, 4개 또는 8개의 expert를 가진 Switch Transformer를 학습시키는 것은 (일반적으로 코어당 하나의 expert를 권장) T5 dense baseline 대비 견고한 개선을 가져온다.
Switch Transformers
 Figure 12: 적은 수의 expert를 가진 Switch Transformer.
Figure 12: 적은 수의 expert를 가진 Switch Transformer.
Switch Transformer는 매우 적은 수의 expert를 사용하더라도 baseline 모델보다 성능이 향상된다. 이 그림은 매우 작은 규모에서의 scaling 특성을 보여주며, 2개, 4개, 8개의 expert를 사용하여 T5-Base 모델보다 성능이 개선됨을 나타낸다.
E. Relation of Upstream to Downstream Model Performance
모델의 사전학습(pre-training) objective에서의 품질이 다운스트림 task 결과로 반드시 이어진다는 보장은 없다. Figure 13은 dense 모델과 Switch 모델 모두에 대해 C4 사전학습 task에서의 업스트림 모델 품질과 두 가지 다운스트림 task 측정치(평균 SuperGLUE 성능 및 TriviaQA 점수) 간의 상관관계를 보여준다. 우리는 이 두 task를 선택했는데, 하나는 모델의 추론 능력을, 다른 하나는 사실적 지식을 측정하기 때문이다.
 Figure 13: 업스트림 사전학습 품질과 다운스트림 모델 품질 간의 관계.
Figure 13: 업스트림 사전학습 품질과 다운스트림 모델 품질 간의 관계.
우리는 업스트림 성능과 다운스트림 품질 간의 상관관계를 SuperGLUE와 TriviaQA (SSM 없이 기록된 SOTA) 벤치마크에서 각각 측정하였다. 이들은 각각 추론 및 지식 중심의 벤치마크이다 (validation set 기준).
우리는 baseline 모델과 마찬가지로 Switch 모델도 업스트림 사전학습 task의 개선에 따라 성능이 확장됨을 발견했다.
SuperGLUE의 경우, negative log perplexity와 평균 SuperGLUE 점수 사이에 느슨하게 선형적인 관계가 있음을 확인했다. 그러나 dense 모델은 동일한 perplexity에서 종종 더 나은 성능을 보였으며, 특히 대규모 모델 영역에서 이러한 경향이 두드러졌다.
반대로, 지식 중심 task인 TriviaQA에서는 Switch Transformer가 향상된 스케일링 관계를 따를 수 있음을 발견했다. 즉, 주어진 업스트림 perplexity에서 dense 모델보다 더 나은 성능을 보였다. 이러한 관찰을 확인하기 위해서는 추가적인 통계(수집 비용이 많이 들고 향후 연구로 남겨짐)가 필요할 것이다.
우리는 일관된 상관관계를 발견했으며, 이는 baseline 모델과 Switch 모델 모두에서 사전학습 개선이 더 나은 다운스트림 결과로 이어진다는 것을 시사한다. 또한, 고정된 업스트림 perplexity에서 Switch 모델과 dense 모델 모두 소형에서 중형 모델 크기 영역에서는 유사한 성능을 보였다. 그러나 가장 큰 모델 영역(T5-11B/T5-XXL)에서는 Section 5.6에서 언급했듯이, 우리의 가장 큰 Switch 모델들이 업스트림 perplexity를 SuperGLUE task의 다운스트림 fine-tuning으로 항상 잘 전환하지는 못했다. 이는 sparse 모델의 잠재력을 완전히 실현하기 위한 향후 조사 및 연구를 필요로 한다. expert-model을 사용한 fine-tuning 역학을 이해하는 것은 매우 복잡하며, regularization, load-balancing, fine-tuning 하이퍼파라미터에 따라 달라진다.
F. Pseudo Code for Switch Transformers
Mesh Tensorflow에서 Switch Transformer를 위한 의사 코드 (Shazeer et al., 2018). 아래 코드에서는 모델 병렬화가 사용되지 않았다 (자세한 내용은 5.4 참조).
import mesh_tensorflow as mtf
def load_balance_loss(router_probs, expert_mask):
"""다양한 expert 라우팅을 보장하기 위한 load-balancing loss를 계산한다."""
# router_probs는 각 토큰에 대해 각 expert에 할당된 확률이다.
# router_probs shape: [num_cores, tokens_per_core, num_experts]
# expert_index는 가장 높은 router 확률을 가진 expert를 one-hot 형식으로 포함한다.
# expert_mask shape: [num_cores, tokens_per_core, num_experts]
# 각 코어에 대해, 각 expert로 라우팅된 토큰의 비율을 얻는다.
# density_1 shape: [num_cores, num_experts]
density_1 = mtf.reduce_mean(expert_mask, reduced_dim=tokens_per_core)
# 각 코어에 대해, 모든 토큰에 걸쳐 router로부터 각 expert에 할당된 확률 질량의 비율을 얻는다.
# density_1_proxy shape: [num_cores, num_experts]
density_1_proxy = mtf.reduce_mean(router_probs, reduced_dim=tokens_per_core)
# 단일 코어에 대한 density_l: 합이 1인 num_experts 길이의 벡터.
# 단일 코어에 대한 density_l_proxy: 합이 1인 num_experts 길이의 벡터.
# 두 벡터 모두 모든 num_expert 요소에 걸쳐 균일한 할당 (1/num_experts)을 갖기를 원한다.
# 두 벡터는 내적(dot product)이 최소화될 때 균일한 할당으로 유도된다.
loss = mtf.reduce_mean(density_1_proxy * density_1) * (num_experts ^ 2)
return loss
Figure 14: Mesh Tensorflow에서 Switch Transformer를 위한 load balance loss의 의사 코드.
import mesh_tensorflow as mtf
def router(inputs, capacity_factor):
"""가장 높은 확률을 가진 expert로부터 토큰을 보내고 받기 위해 사용되는
combine 및 dispatch 텐서를 생성한다."""
# 모든 텐서와 연산에 대해 코어 레이아웃은 num_cores로 분할된다.
# inputs shape: [num_cores, tokens_per_core, d_model]
router_weights = mtf.Variable(shape=[d_model, num_experts])
# router_logits shape: [num_cores, tokens_per_core, num_experts]
router_logits = mtf.einsum([inputs, router_weights], reduced_dim=d_model)
if is_training:
# expert 간 탐색을 위한 노이즈를 추가한다.
router_logits += mtf.random_uniform(shape=router_logits.shape, minval=1-eps, maxval=1+eps)
# 안정성을 위해 입력을 bfloat16에서 float32로 변환하여 softmax 연산을 수행한다.
router_logits = mtf.to_float32(router_logits)
# 각 토큰이 어떤 expert로 보내져야 하는지에 대한 확률.
router_probs = mtf.softmax(router_logits, axis=-1)
# 각 토큰에 대한 top-1 expert를 얻는다. expert_gate는 각 토큰에 대한
# router의 top-1 확률이다. expert_index는 각 토큰이 라우팅될 expert이다.
# expert_gate shape: [num_cores, tokens_per_core]
# expert_index shape: [num_cores, tokens_per_core]
expert_gate, expert_index = mtf.top_1(router_probs, reduced_dim=num_experts)
# expert_mask shape: [num_cores, tokens_per_core, num_experts]
expert_mask = mtf.one_hot(expert_index, dimension=num_experts)
# load balancing loss를 계산한다.
aux_loss = load_balance_loss(router_probs, expert_mask)
# expert는 고정된 capacity를 가지므로, 이를 초과하지 않도록 한다.
# 각 expert로의 배치 인덱스를 position_in_expert와 함께 구성한다.
# expert_capacity를 초과하는 예시가 각 expert로 라우팅되지 않도록 한다.
position_in_expert = mtf.cumsum(expert_mask, dimension=tokens_per_core) * expert_mask
# expert_capacity 내에 맞는 토큰만 유지한다.
expert_mask *= mtf.less(position_in_expert, expert_capacity)
expert_mask_flat = mtf.reduce_sum(expert_mask, reduced_dim=experts_dim)
# expert capacity를 초과한 expert들을 마스킹한다.
expert_gate *= expert_mask_flat
# expert 출력을 결합하고 router 확률로 스케일링하는 데 사용되는 combine_tensor.
# combine_tensor shape: [num_cores, tokens_per_core, num_experts, expert_capacity]
combine_tensor = (
expert_gate * expert_mask_flat *
mtf.one_hot(expert_index, dimension=num_experts) *
mtf.one_hot(position_in_expert, dimension=expert_capacity))
# 나머지 layer를 위해 출력을 bfloat16으로 다시 캐스팅한다.
combine_tensor = mtf.to_bfloat16(combine_tensor)
# 토큰이 해당 expert로 라우팅되면 1인 이진 dispatch 텐서를 생성한다.
# dispatch_tensor shape: [num_cores, tokens_per_core, num_experts, expert_capacity]
dispatch_tensor = mtf.cast(combine_tensor, tf.bool)
return dispatch_tensor, combine_tensor, aux_loss
Figure 15: Mesh Tensorflow에서 Switch Transformer를 위한 router의 의사 코드.
Switch Transformers
import mesh_tensorflow as mtf
def switch_layer(inputs, n, capacity_factor, num_experts):
"""Distributed switch transformer feed-forward layer."""
# num_cores (n) = total cores for training the model (scalar).
# d_model = model hidden size (scalar).
# num_experts = total number of experts.
# capacity_factor = extra buffer for each expert.
# inputs shape: [batch, seq_len, d_model]
batch, seq_len, d_model = inputs.get_shape()
# 각 코어는 tokens_per_core 개수의 토큰을 올바른 expert로 라우팅한다.
tokens_per_core = batch * seq_len / num_cores
# 각 expert는 [num_cores, expert_capacity, d_model] 형태를 가진다.
# 각 코어는 expert_capacity 개수의 토큰을 각 expert로 보내는 역할을 한다.
expert_capacity = tokens_per_core * capacity_factor / num_experts
# 코어별 expert dispatching을 위해 reshape한다.
# shape: [batch, seq_len, d_model] -> [num_cores, tokens_per_core, d_model]
# Core layout: [n, 1, 1] -> [n, 1, 1]
inputs = mtf.reshape(inputs, [num_cores, tokens_per_core, d_model])
# Core Layout: [n, 1, 1] -> [n, 1, 1, 1], [n, 1, 1, 1]
# dispatch_tensor (boolean) shape: [num_cores, tokens_per_core, num_experts, expert_capacity]
# dispatch_tensor는 토큰을 올바른 expert로 라우팅하는 데 사용된다.
# combine_tensor (float) shape: [num_cores, tokens_per_core, num_experts, expert_capacity]
# combine_tensor는 expert 출력을 결합하고 router 확률로 스케일링하는 데 사용된다.
dispatch_tensor, combine_tensor, aux_loss = router(inputs, expert_capacity)
# 큰 boolean tensor와의 행렬 곱셈을 통해 토큰을 올바른 expert에 할당한다.
# Core Layout: [n, 1, 1], -> [1, n, 1, 1]
# expert_inputs shape: [num_experts, num_cores, expert_capacity, d_model]
expert_inputs = mtf.einsum([inputs, dispatch_tensor], reduce_dims=[tokens_per_core])
# All-to-All 통신. 코어는 num_cores에 걸쳐 분할되어 있으며, 이제 num_experts에 걸쳐 분할하고자 한다.
# 이는 로컬에서 라우팅된 토큰을 이제 다른 코어에 걸쳐 분할된 올바른 expert로 보낸다.
# Core layout: [1, n, 1, 1] -> [n, 1, 1, 1]
expert_inputs = mtf.reshape(expert_inputs, [num_experts, num_cores, expert_capacity, d_model])
# 표준 feed forward 계산으로, 각 expert는 고유한 파라미터 세트를 가진다.
# 생성된 총 고유 파라미터: num_experts * (d_model * d_ff * 2).
# expert_outputs shape: [num_experts, num_cores, expert_capacity, d_model]
expert_outputs = feed_forward(expert_inputs)
# All-to-All 통신. 코어는 현재 experts 차원에 걸쳐 분할되어 있으며,
# 이를 다시 num_cores에 걸쳐 분할되도록 전환해야 한다.
# Core Layout: [n, 1, 1, 1] -> [1, n, 1, 1]
expert_outputs = mtf.reshape(expert_outputs, [num_experts, num_cores, expert_capacity, d_model])
# 입력 shape으로 다시 변환하고 expert의 출력을 라우팅 확률로 곱한다.
# expert_outputs shape: [num_experts, num_cores, tokens_per_core, d_model]
# expert_outputs_combined shape: [num_cores, tokens_per_core, d_model]
# Core Layout: [1, n, 1, 1] -> [n, 1, 1]
expert_outputs_combined = mtf.einsum([expert_outputs, combine_tensor], reduce_dims=[tokens_per_core])
# 로컬 라우팅 dispatching에 사용된 tokens_per_core shape을 제거하여 입력 shape과 일치시킨다.
# Core Layout: [n, 1, 1] -> [n, 1, 1]
outputs = mtf.reshape(expert_outputs_combined, [batch, seq_len, d_model])
return outputs, aux_loss
Figure 16: Mesh Tensorflow에서 Switch Transformer layer의 pseudo code.