TVR: 비디오와 자막을 함께 이해하는 순간 검색을 위한 대규모 데이터셋
TVR (TV show Retrieval)은 비디오의 시각적 내용과 자막 텍스트를 모두 이해해야 하는 새로운 멀티모달 순간 검색 데이터셋입니다. 이 논문은 6개 TV 쇼의 21.8K 비디오에 대한 109K 개의 쿼리를 포함하며, 각 쿼리는 정확한 시간 정보와 연결됩니다. 또한, Cross-modal Moment Localization (XML)이라는 새로운 모델을 제안하여, late fusion 방식과 Convolutional Start-End (ConvSE) detector를 통해 기존의 베이스라인 모델들보다 훨씬 높은 성능과 효율성을 보여줍니다. 논문 제목: TVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval
논문 요약: TVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval
- 논문 링크: [ArXiv/학회 링크 (예: https://arxiv.org/abs/2007.00977)] (유럽 컴퓨터 비전 학회, ECCV 2020)
- 저자: Jie Lei, Licheng Yu, Tamara L. Berg, Mohit Bansal (University of North Carolina at Chapel Hill)
- 발표 시기: 2020년, European Conference on Computer Vision (ECCV)
- 주요 키워드: Multimodal Retrieval, Video Moment Retrieval, Dataset, Deep Learning, NLP, Computer Vision
1. 연구 배경 및 문제 정의
- 문제 정의:
기존 비디오 검색 연구는 주로 단일 모달리티(시각)에만 의존하여 실제 검색 환경(비디오와 자막 텍스트 동시 이해)을 충분히 반영하지 못하는 한계가 있었다. 특히, 대규모 비디오 코퍼스에서 자연어 쿼리를 통해 특정 순간을 효율적이고 정확하게 검색하는 멀티모달 비디오 코퍼스 순간 검색(Video Corpus Moment Retrieval, VCMR) task는 여전히 어려운 문제로 남아있다. - 기존 접근 방식:
기존 순간 검색 데이터셋(DiDeMo, ActivityNet Captions 등)은 비디오 기반으로 시각 정보에만 의존했다. 또한, 기존 방법론들은 미리 정의된 순간 제안(moment proposal)을 랭킹하는 방식에 의존했는데, 이는 시간적으로 정확하지 않고 긴 비디오에 대한 확장성이 부족하며 계산 비용이 높다는 한계가 있었다. Reading comprehension의 start-end predictor를 적용한 early fusion 방식은 단일 비디오에서는 유망했지만, VCMR과 같이 모든 쿼리-비디오 쌍을 융합해야 하는 코퍼스 수준에서는 계산 비용이 비현실적으로 높아지는 문제가 있었다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- TVR (TV show Retrieval) 데이터셋 제안: 비디오의 시각적 내용과 자막 텍스트를 모두 이해해야 하는 새로운 대규모 멀티모달 순간 검색 데이터셋을 구축했다. 이 데이터셋은 6개 TV 쇼의 21.8K 비디오에 대한 109K개의 고품질 쿼리를 포함하며, 언어적 다양성이 높고 더 많은 행동과 인물을 포함한다.
- Cross-modal Moment Localization (XML) 네트워크 제안: VCMR task를 위한 효율적인 late fusion 기반 모델을 제안했다. 이 모델은 새로운 Convolutional Start-End detector (ConvSE) 모듈을 포함하여 기존 베이스라인 모델들보다 훨씬 높은 성능과 효율성을 달성한다.
- 제안 방법:
논문은 VCMR을 해결하기 위해 계층적 Cross-modal Moment Localization (XML) 네트워크를 제안한다. XML은 얕은 레이어에서 비디오 검색(VR)을 수행하고, 깊은 레이어에서 더 세분화된 순간 검색(moment retrieval)을 수행한다.- Late Fusion 설계: 비디오(및 자막)와 쿼리를 독립적으로 인코딩하여, 모든 쿼리-비디오 쌍에 대한 early fusion의 비효율성을 극복한다. 비디오는 미리 인코딩하여 저장할 수 있어 검색 시 사용자 대기 시간을 크게 단축시킨다.
- 입력 표현: 비디오는 ResNet-152(외형) 및 I3D(움직임) feature를 사용하고, 텍스트(쿼리, 자막)는 RoBERTa를 fine-tuning하여 contextualized feature를 추출한다.
- 모듈화된 쿼리 인코딩: 쿼리를 비디오 및 자막에 대한 두 개의 모듈화된 벡터로 동적으로 분해하여 각 모달리티에 대한 쿼리 단어의 중요도를 반영한다.
- Convolutional Start-End detector (ConvSE): 쿼리-클립 유사도 점수로부터 순간 예측을 생성하기 위해, 두 개의 학습 가능한 1D convolution 필터를 사용하여 유사도 신호에서 시작(up) 및 끝(down) 경계(edge)를 학습하여 감지한다. 이는 수작업 규칙에 의존하는 기존 방식의 한계를 극복한다.
- 학습 및 추론: 비디오 검색(VR) 손실과 단일 비디오 순간 검색(SVMR) 손실을 결합하여 학습하며, 추론 시에는 VR 점수를 기반으로 상위 비디오를 검색한 후, SVMR 점수와 VR 점수를 결합한 aggregation function으로 최종 순간을 순위화한다.
3. 실험 결과
- 데이터셋:
TVR 데이터셋은 21.8K개의 비디오에서 추출된 109K개의 쿼리를 포함한다. 데이터는 80% train, 10% val, 5% test-public, 5% test-private으로 분할되며, 비디오와 그에 연관된 쿼리는 오직 하나의 분할에만 포함되도록 한다. 평가는 Recall at K (R@K) 및 temporal Intersection over Union (IoU) 지표를 사용하며, RTX 2080Ti GPU에서 실험이 진행되었다. - 주요 결과:
- XML의 압도적인 성능: VCMR task에서 MCN, CAL, MEE+MCN, MEE+CAL, MEE+ExCL 등 모든 baseline 모델보다 현저히 높은 성능을 달성했다. 특히, R@1 IoU=0.7 기준으로 MEE+ExCL(0.33) 대비 XML(3.25)은 약 9.85배의 성능 향상을 보였다.
- XML의 높은 효율성: MEE+ExCL 대비 51.3배 빠른 속도(25.5초 vs 1307.2초)를 보여주며, 이는 XML의 late fusion 설계의 효과를 입증한다. 대규모 코퍼스(1백만 비디오)에서는 287배까지 속도 향상이 가능함을 시사한다.
- 멀티모달리티의 중요성: 비디오와 자막을 모두 사용하는 XML 모델이 단일 모달리티(비디오 또는 자막)만 사용하는 모델보다 전반적으로 더 나은 성능을 보였으며, 이는 두 모달리티 모두 검색에 유용함을 입증했다.
- ConvSE의 효과: 동일한 XML backbone 네트워크 하에서, ConvSE는 sliding window 및 TAG와 같은 수작업 규칙 기반의 moment 생성 방법보다 VCMR 및 SVMR task 모두에서 모든 IoU 임계값에 걸쳐 일관되게 더 나은 성능을 보였다. 학습된 ConvSE 필터는 이미지 처리의 경계 감지기와 유사하게 시작 및 끝 경계에서 강한 응답을 출력하여 해석 가능성을 보여주었다.
4. 개인적인 생각 및 응용 가능성
- 장점:
실제 TV 쇼 데이터를 활용하여 비디오와 자막이라는 두 가지 중요한 모달리티를 동시에 고려하는 현실적인 멀티모달 순간 검색 데이터셋을 구축한 점이 인상 깊다. 데이터셋의 규모가 크고, 쿼리의 언어적 다양성이 높으며, 정확한 시간 스탬프와 쿼리 유형 레이블링을 통해 심층 분석이 가능하다는 점이 강점이다. XML 모델의 late fusion 설계와 ConvSE 모듈을 통해 기존 early fusion 방식의 한계인 높은 계산 비용과 낮은 확장성을 극복하고, 동시에 높은 성능을 달성한 점이 탁월하다. - 단점/한계:
정성적 분석에서 실패 사례가 'on the shoulder' vs 'around the shoulder'와 같은 미묘한 차이에서 발생했음을 보여주는데, 이는 모델이 여전히 미세한 의미론적 차이를 구분하는 데 어려움을 겪을 수 있음을 시사한다. 더 정교한 의미 이해를 위한 개선의 여지가 있을 수 있다. 또한, TV 쇼라는 특정 도메인에 한정된 데이터셋이므로, 다른 종류의 비디오(예: 스포츠, 뉴스, 사용자 생성 콘텐츠)에 대한 일반화 가능성은 추가 검증이 필요할 수 있다. - 응용 가능성:
대규모 비디오 아카이브(예: 방송사 자료, OTT 서비스 콘텐츠)에서 특정 장면이나 대화를 효율적으로 검색하는 시스템에 적용될 수 있다. 사용자가 자연어 쿼리를 통해 영화나 TV 쇼의 특정 순간을 찾아볼 수 있는 차세대 비디오 검색 엔진 개발에 활용될 수 있으며, 비디오 콘텐츠 기반의 자동 요약, 하이라이트 생성, 특정 이벤트 감지 등 다양한 비디오 이해 및 생성 작업에 기반 기술로 활용될 수 있다.
Lei, Jie, et al. "Tvr: A large-scale dataset for video-subtitle moment retrieval." European Conference on Computer Vision. Cham: Springer International Publishing, 2020.
TVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval
Jie Lei, Licheng Yu, Tamara L. Berg, and Mohit Bansal<br>University of North Carolina at Chapel Hill<br>{jielei, licheng, tlberg, mbansal}@cs.unc.edu
Abstract
우리는 새로운 멀티모달 검색 데이터셋인 **TV show Retrieval (TVR)**을 소개한다. TVR은 시스템이 비디오와 그에 연관된 자막(대화) 텍스트를 모두 이해하도록 요구하여, 더욱 현실적인 검색 환경을 제공한다. 이 데이터셋은 다양한 장르의 6개 TV 쇼에서 추출된 21.8K개의 비디오에 대해 109K개의 쿼리를 포함하며, 각 쿼리는 **정확한 시간적 구간(tight temporal window)**과 연결되어 있다. 또한 쿼리들은 비디오, 자막, 또는 둘 다와 더 관련이 있는지를 나타내는 쿼리 유형(query type)으로 레이블링되어 있어, 데이터셋 및 이를 기반으로 구축된 방법론에 대한 심층 분석이 가능하다. 수집된 데이터의 품질을 보장하기 위해 엄격한 자격 검증 및 후처리 검증 테스트가 적용되었다. 추가적으로, 우리는 멀티모달 순간 검색(moment retrieval) task를 위한 여러 baseline 모델과 새로운 Cross-modal Moment Localization (XML) 네트워크를 제시한다. 제안된 XML 모델은 새로운 Convolutional StartEnd detector (ConvSE)를 포함하는 late fusion 설계를 사용하며, baseline 모델들을 큰 폭으로 능가하고 더 나은 효율성을 보여주어 향후 연구를 위한 강력한 출발점을 제공한다.
1 Introduction
매일 엄청난 수의 멀티모달 비디오(오디오 및/또는 텍스트 포함)가 웹에 업로드되고 있다. 사용자가 이러한 비디오를 검색하고 관련 순간을 찾을 수 있도록, 비디오 데이터 검색을 위한 효율적이고 정확한 방법이 필수적이다. 최근 연구 [138]는 자연어 쿼리를 통해 단일 비디오에서 특정 순간을 검색하는 Single Video Moment Retrieval (SVMR) task를 소개했다. Escorcia et al. [7]은 SVMR을 **Video Corpus Moment Retrieval (VCMR)**로 확장하여, 시스템이 단일 비디오가 아닌 대규모 비디오 코퍼스에서 가장 관련성 높은 순간을 검색하도록 요구했다. 그러나 기존의 순간 검색 데이터셋 [13, 25, 8, 19]이 비디오 기반이기 때문에, 이러한 연구들은 검색을 위한 컨텍스트 소스로 단일 모달리티(시각)에만 의존한다. 실제로는 비디오가 오디오나 텍스트와 같은 다른 모달리티와 연관되는 경우가 많다. 예를 들어, 영화/TV 쇼의 자막이나 라이브 스트림 비디오에 동반되는 시청자 담론 등이 있다. 이러한 연관된 모달리티는 사용자에게 관련성 높은 순간을 검색하는 데 동등하게 중요한 소스가 될 수 있다. Fig. 1은 VCMR task의 쿼리 예시를 보여주는데, 여기서는 비디오와 자막 모두 검색 과정에 필수적이다.
 Fig. 1: VCMR task의 TVR 예시. Ground truth 순간은 녹색 상자로 표시된다. 쿼리의 색상은 단어가 비디오(파란색) 또는 자막(자홍색) 또는 둘 다(검은색)와 관련되어 있는지 나타낸다. 비디오 코퍼스에서 관련 순간을 더 잘 검색하려면 시스템은 비디오와 자막을 모두 이해해야 한다.
Fig. 1: VCMR task의 TVR 예시. Ground truth 순간은 녹색 상자로 표시된다. 쿼리의 색상은 단어가 비디오(파란색) 또는 자막(자홍색) 또는 둘 다(검은색)와 관련되어 있는지 나타낸다. 비디오 코퍼스에서 관련 순간을 더 잘 검색하려면 시스템은 비디오와 자막을 모두 이해해야 한다.
따라서 비디오 및 텍스트 컨텍스트를 모두 포함하는 멀티모달 순간 검색을 연구하기 위해, 우리는 새로운 데이터셋인 **TV show Retrieval (TVR)**을 제안한다. 영화/만화/TV 쇼를 기반으로 멀티모달 데이터셋을 구축한 최근 연구들 [30, 18, 20]에서 영감을 받아, 우리는 TV 쇼를 데이터 리소스로 선택했다. TV 쇼는 일반적으로 배우들 간의 풍부한 사회적 상호작용을 포함하며, 활동과 대화가 모두 포함되기 때문이다. 데이터 수집 과정에서 우리는 어노테이터에게 비디오와 관련 자막을 제공하여 멀티모달 쿼리를 작성하도록 유도했다. 각 비디오-쿼리 쌍에 대해 정확한 시간 스탬프가 레이블링된다. 우리는 미리 정의된 고정 세그먼트([13]에서처럼)를 사용하지 않고, 더 정확한 localization을 위해 시간 스탬프를 자유롭게 어노테이션했다. 또한, 각 쿼리에 대해 쿼리 유형을 수집하여 비디오, 자막 또는 둘 다와 더 관련이 있는지를 나타내어 시스템에 대한 더 깊은 분석을 가능하게 한다. 데이터 품질을 보장하기 위해 엄격한 자격 심사 및 어노테이션 후 품질 검증 테스트를 설정했다. 총 6개의 TV 쇼에서 21,793개의 비디오에 대해 108,965개의 고품질 쿼리를 수집하여, 이 종류의 가장 큰 데이터셋을 구축했다. 기존 데이터셋 [13, 25, 18, 19]과 비교하여, TVR은 더 큰 언어적 다양성(Fig. 3)을 가지며, 쿼리에 더 많은 행동과 사람을 포함(Table 2)함을 보여준다.
TVR 데이터셋을 통해 우리는 순간 검색 task를 비디오와 자막 텍스트를 모두 고려해야 하는 더 현실적인 멀티모달 설정(즉, 'Video-Subtitle Moment Retrieval')으로 확장한다. 본 논문에서는 코퍼스 수준의 VCMR task에 중점을 둔다. SVMR은 ground-truth 비디오가 미리 주어지는 VCMR의 단순화된 버전으로 볼 수 있기 때문이다. 이전 연구들 [13, 8, 14, 32, 9, 7]은 미리 정의된 순간 제안(moment proposal) 집합에 대한 랭킹 문제로 순간 검색 task를 탐구한다. 이러한 제안들은 일반적으로 수작업으로 만든 휴리스틱 [13, 14] 또는 슬라이딩 윈도우 [8, 32, 9, 7]를 사용하여 생성되며, 일반적으로 시간적으로 정확하지 않아 최적의 성능을 내지 못한다. 또한, 이러한 방법들은 긴 비디오에 쉽게 확장되지 않을 수 있다: 제안의 수는 종종 비디오 길이에 따라 제곱으로 증가하여 계산 비용이 비현실적이 된다. 최근 방법들 [10, 21]은 비디오 및 언어(쿼리) feature의 early fusion을 통해 reading comprehension task의 start-end span predictor [28, 3]를 순간 검색에 적용한 다음, 융합된 feature에 신경망을 적용하여 start-end 확률을 예측한다. [10]에서는 span predictor를 사용하는 것이 여러 proposal 기반 방법보다 우수하다는 것을 보여주었다. 또한, start-end predictor는 계산 비용이 선형적으로만 증가하여 긴 비디오로의 확장을 용이하게 한다. [10]은 SVMR에서 유망한 결과를 보여주었지만, early fusion을 사용하기 때문에 VCMR에는 확장성이 떨어진다. 개의 비디오 코퍼스에서 개의 쿼리를 검색하는 것을 고려해보자. 이는 확률을 생성하기 위해 개의 early fused representation에 대해 여러 layer의 LSTM [15]을 실행해야 하므로, 과 의 값이 클 경우 계산 비용이 매우 비싸다.
이러한 문제들을 해결하기 위해 우리는 **VCMR을 위한 late fusion 접근 방식인 Cross-modal Moment Localization (XML)**을 제안한다. XML에서는 비디오(또는 자막)와 쿼리가 독립적으로 인코딩되므로, 개의 신경망 연산만 필요하다. 또한, 비디오는 미리 인코딩하여 저장할 수 있다. 테스트 시에는 새로운 사용자 쿼리만 인코딩하면 되므로 사용자 대기 시간이 크게 단축된다. Late fusion은 비디오와 쿼리 표현을 고도로 최적화된 행렬 곱셈으로 통합하여 비디오의 시간 차원에 걸쳐 1D 쿼리-클립 유사도 점수를 생성한다. 이러한 유사도 점수로부터 순간 예측을 생성하기 위해, 단순한 접근 방식은 앞서 언급한 슬라이딩 윈도우 제안들을 각 제안 영역 내의 유사도 점수 평균으로 계산된 신뢰도 점수로 랭킹하는 것이다. 또는 TAG [37]를 사용하여 상위 점수 클립을 점진적으로 그룹화할 수도 있다. 그러나 이러한 방법들은 수작업으로 만든 규칙에 의존하며 학습이 불가능하다. 이미지 에지 검출기 [29]에서 영감을 받아, 우리는 **두 개의 학습 가능한 1D convolution 필터로 유사도 신호에서 시작(up) 및 끝(down) 에지를 학습하여 검출하는 Convolutional Start-End detector (ConvSE)**를 제안한다. 동일한 backbone net을 사용하여 ConvSE가 두 접근 방식보다 더 나은 성능을 보임을 보여준다. late fusion과 ConvSE를 통해 XML이 이전 방법들 [13, 7, 10]을 능가하며, 더 나은 계산 효율성을 제공함을 추가로 보여준다.
요약하자면, 우리의 기여는 두 가지이다: (i) 우리는 TVR 데이터셋을 소개한다. 이는 언어적 다양성이 뛰어난 109K개의 고품질 쿼리를 포함하는 대규모 멀티모달 순간 검색 데이터셋이다. (ii) 우리는 VCMR task를 위한 late fusion 설계를 사용하는 효율적인 접근 방식인 XML을 제안한다. XML의 핵심은 1D 유사도 신호에서 start-end 에지를 학습하여 검출하는 우리의 새로운 ConvSE 모듈이다. 포괄적인 실험과 분석은 XML이 제시된 모든 baseline을 큰 차이로 능가하며 더 나은 효율성으로 실행됨을 보여준다.
2 Related Work
자연어 기반 moment retrieval의 목표는 단일 비디오 [138] 또는 대규모 비디오 코퍼스 [7]에서 관련 있는 moment를 검색하는 것이다. 다음에서는 이러한 task에 대한 커뮤니티의 노력들을 간략히 살펴보고, 기존 연구와 우리의 연구 간의 차이점을 설명한다.
데이터셋 (Datasets)
이 task를 위해 여러 데이터셋이 제안되었다. 예를 들어, DiDeMo [13], ActivityNet Captions [19], Charades-STA [8], TACoS [25] 등이 있으며, 이들 데이터셋에서는 쿼리가 비디오만으로도 localization될 수 있다. TVR은 쿼리 localization에 추가적인 텍스트(자막) 정보가 필요하다는 점에서 이들과 다르다.
이전 연구들에서는 두 가지 유형의 데이터 어노테이션 방식이 탐구되었다:
(i) 비디오를 균일하게 세그먼트로 분할하고, 어노테이터가 하나(또는 그 이상)를 선택하여 명확한 설명을 작성하는 방식 [13]. 예를 들어, DiDeMo [13]의 moment는 고정된 5초 세그먼트에서 생성된다. 그러나 이러한 거친 시간적 어노테이션은 자연스러운 moment와 잘 일치하지 않는다. TVR에서는 중요한 moment를 더 정확하게 포착하기 위해 시간적 window가 자유롭게 선택된다.
(ii) 전체 비디오를 위해 작성된 단락을 개별 쿼리 문장으로 변환하는 방식 [25, 8, 19]. 사람들이 단락에서 시간적 연결어(예: 'first', 'then')나 대명사(예: 'pronouns') [27]를 사용하는 것은 자연스럽지만, 이러한 단어들은 개별 문장을 검색 쿼리로 사용하기에 덜 적합하게 만든다. 이에 비해, TVR의 어노테이션 프로세스는 어노테이터가 단락의 맥락 없이 개별적으로 쿼리를 작성하도록 권장한다. 또한, TVR은 더 큰 규모와 더 큰 언어적 다양성을 가지고 있으며, 이에 대한 자세한 내용은 Sec. 3.2에서 확인할 수 있다.
방법론 (Methods)
기존 연구들 [138, 14, 32, 9, 7]은 moment retrieval을 미리 정의된 moment proposal 집합을 랭킹하는 문제로 다룬다. 이러한 proposal은 일반적으로 수작업으로 정의된 규칙 [13, 14] 또는 sliding window [8, 32, 9, 7]를 사용하여 생성된다. 일반적으로 이러한 proposal은 시간적으로 정밀하지 않으며, 높은 계산 비용으로 인해 긴 비디오에 확장하기 어렵다. [8, 32, 9]는 proposal의 오프셋을 조정하는 regression branch를 사용하여 첫 번째 문제를 완화한다. 그러나 이들은 여전히 초기 proposal의 거칠기(coarseness)에 의해 제한된다.
reading comprehension [28, 3] 및 action localization [22]의 span predictor에서 영감을 받아, 우리는 start-end predictor를 사용하여 early fused query-video representation으로부터 start-end 확률을 예측한다. 이러한 방법들은 긴 비디오에 더 유연하게 적용될 수 있고 단일 비디오 moment retrieval에서 유망한 성능을 보였지만, 코퍼스 수준의 moment retrieval 문제를 다룰 때는 early fusion의 시간 비용이 감당할 수 없게 된다. 즉, 모든 가능한 query-video 쌍을 early fusing해야 하기 때문이다 [7].
Proposal 기반 접근 방식인 MCN [13]과 CAL [7]은 late fusion 설계를 사용하는데, 이 방식에서는 비디오 representation을 미리 계산하여 저장할 수 있어 검색 효율성이 높아진다. 최종 moment 예측은 주어진 쿼리에 대한 proposal 간의 Squared Euclidean Distance를 랭킹하여 수행된다. 그러나 이들은 미리 정의된 proposal에 의존하기 때문에, MCN과 CAL은 **앞서 언급된 단점들(덜 정밀한 예측, 높은 비용, 특히 긴 비디오의 경우)**을 여전히 겪는다. 최근 연구들 [35, 36]은 비디오와의 단어 수준 early fusion을 고려하는데, 이는 훨씬 더 많은 비용이 들 수 있다.
이와 대조적으로, XML은 새로운 Convolutional Start-End (ConvSE) detector를 사용한 late fusion 설계를 채택하여, 계산 비용을 줄이면서도 더 정확한 moment 예측을 생성한다.
3 Dataset
우리의 TVR 데이터셋은 TVQA [20]에서 제공하는 3가지 장르(시트콤, 의학, 범죄)에 걸쳐 장기 방영된 6개 TV 쇼의 21,793개 비디오를 기반으로 구축되었다. 이 비디오들은 자막과 쌍을 이루며, 평균 길이는 76.2초이다. 다음 섹션에서는 TVR 데이터셋을 어떻게 수집했는지 설명하고, 데이터에 대한 상세한 분석을 제공한다.
3.1 Data Collection
우리는 TVR 데이터 수집을 위해 **Amazon Mechanical Turk (AMT)**를 활용했다. 각 AMT 작업자는 비디오 및/또는 자막 정보를 사용하여 쿼리(query)를 작성한 다음, 작성된 쿼리와 일치하는 순간(moment)을 정의하기 위해 시작 및 종료 타임스탬프를 표시하도록 요청받았다. 이 쿼리-순간 쌍은 주어진 비디오 내에서 고유한 일치(unique match)여야 한다. 즉, 쿼리는 해당 순간을 고유하게 지역화하는 referring expression [17, 13]이어야 한다.
우리는 추가적으로 작업자들에게 세 가지 쿼리 유형 중 하나를 선택하도록 요청했다:
- video-only: 시각적 콘텐츠에만 관련된 쿼리
- sub-only: 자막에만 관련된 쿼리
- video + sub: 비디오와 자막 모두를 포함하는 쿼리
파일럿 연구에서 우리는 작업자들이 sub-only 쿼리를 작성하는 것을 선호한다는 것을 발견했다. 유사한 현상은 TVQA [20]에서도 관찰되었는데, 여기서는 사람들이 자막만 읽고도 72.88%의 QA 정확도를 달성할 수 있었다. 따라서, 하나 또는 두 가지 양식(modality)을 모두 요구하는 쿼리의 균형을 맞추기 위해, 우리는 데이터 어노테이션을 시각 라운드(visual round)와 텍스트 라운드(textual round)의 두 라운드로 분할했다.
- 시각 라운드에서는 작업자들이 video-only 및 video + sub 쿼리를 포함하여 시각적 콘텐츠와 관련된 쿼리를 작성하도록 권장했다.
- 텍스트 라운드에서는 sub-only 및 video + sub 쿼리를 권장했다.
우리는 다음 전략을 통해 데이터 품질을 보장했다.
자격 테스트 (Qualification Test)
우리는 12개의 객관식 질문으로 구성된 자격 테스트를 설계했으며, 최소 9개 이상의 질문에 정확하게 답변한 작업자만 어노테이션 작업에 참여하도록 허용하여, 작업자들이 우리의 작업 요구 사항을 잘 이해하도록 했다. 총 1,055명의 작업자가 테스트에 참여했으며, 합격률은 67%였다. 이 자격 테스트를 추가함으로써 데이터 품질이 크게 향상되었다.
자동 검사 (Automatic Check)
수집 과정에서 우리는 모든 필수 어노테이션(쿼리, 타임스탬프 등)이 수행되었는지, 각 쿼리가 최소 8단어를 포함하고 자막에서 복사되지 않았는지를 확인하는 자동화된 도구를 사용했다.
수동 검사 (Manual Check)
수집 과정 전반에 걸쳐 수집된 데이터에 대한 추가적인 수동 검사가 내부적으로 이루어졌다. 부적격 쿼리(disqualified queries)는 재어노테이션되었고, 부적격 쿼리를 생성한 작업자는 우리의 작업자 목록에서 제외되었다.
어노테이션 후 검증 (Post-Annotation Verification)
수집된 데이터의 품질을 검증하기 위해 어노테이션 후 검증 실험을 수행했다. 우리는 AMT에 또 다른 작업을 설정하여 작업자들이 수집된 쿼리-순간 쌍의 품질을 관련성, 쿼리-순간 쌍이 고유한 일치인지 여부 등을 기준으로 평가하도록 했다. 평가는 5가지 옵션(매우 동의, 동의, 보통, 동의하지 않음, 매우 동의하지 않음)을 가진 Likert 척도 방식으로 이루어졌다. 결과에 따르면 쌍의 92%가 최소 '보통' 이상의 평가를 받았다. 우리는 '매우 동의하지 않음'으로 평가된 쿼리 그룹을 추가로 분석했으며, 그 중 80%가 여전히 허용 가능한 품질임을 발견했다 (예: 타임스탬프가 약간 불일치하는 경우 (1초 이하)). 이 검증은 3,600개의 쿼리-순간 쌍에 대해 수행되었다. 자세한 내용은 보충 파일에 제시되어 있다.
| Dataset | Domain | #Q/#videos | Vocab. size | Avg. Q len. | Avg. len. (s) moment/video | Q video | text | Free st-ed | Q type anno. | Individual Q |
|---|---|---|---|---|---|---|---|---|---|---|
| TACoS 25 | Cooking | 2 K | 10.5 | 5.9 / 287 | - | - | - | |||
| DiDeMo [13] | Flickr | 7.6 K | 8.0 | 6.5 / 29.3 | - | - | - | |||
| ActivityNet Captions 19] | Activity | 12.5 K | 14.8 | 36.2 / 117.6 | - | - | - | |||
| CharadesSTA 8| | Activity | 1.3 K | 7.2 | 8.1 / 30.6 | - | - | - | |||
| TVR | TV show | 57.1 K | 13.4 | 9.1 / 76.2 |
Table 1: TVR과 기존 moment retrieval 데이터셋 비교. Q는 query를 의미한다. Q context는 쿼리가 어떤 양식과 관련되어 있는지를 나타낸다. Free st-ed는 타임스탬프가 자유롭게 어노테이션되었는지 여부를 나타낸다. Individual Q는 쿼리가 단락 내 문장이 아닌 개별 문장으로 수집되었음을 의미한다.
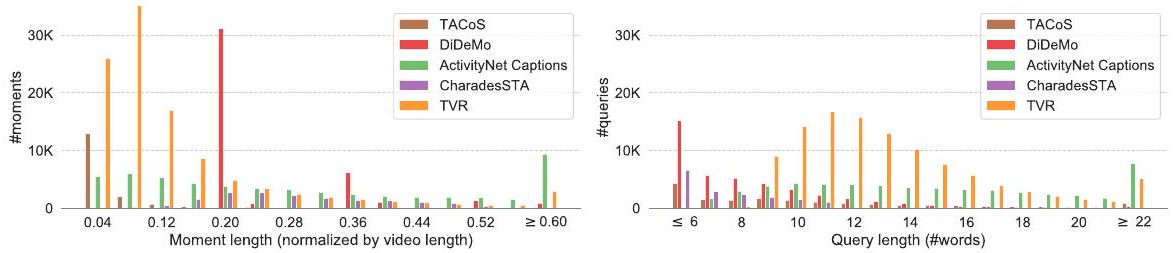
Fig. 2: 순간(moment) (왼쪽) 및 쿼리(query) (오른쪽) 길이 분포. 기존 moment retrieval 데이터셋 [25, 13, 19, 8]과 비교하여 TVR은 상대적으로 더 짧은 순간(정규화됨)과 더 긴 쿼리를 가진다. 확대하여 디지털로 보는 것이 가장 좋다.
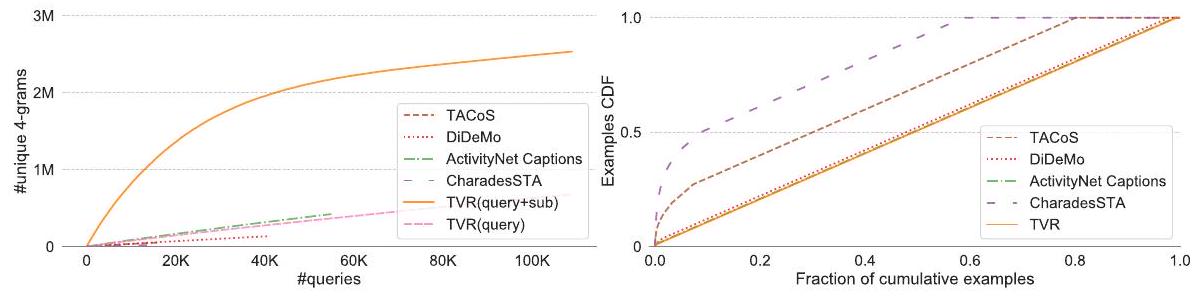
Fig. 3: 왼쪽: 쿼리 수에 따른 고유 4-gram 수. 오른쪽: 빈도순으로 정렬된 쿼리의 CDF. 이 플롯을 얻기 위해 각 데이터셋에서 10K개의 쿼리를 샘플링했으며, [34]에 따라 토큰화 및 표제어 추출 후 정확히 일치하면 두 쿼리를 동일한 것으로 간주했다. 기존 moment retrieval 데이터셋 [25, 13, 19, 8]과 비교하여 TVR은 더 큰 다양성을 가지며, 즉 더 많은 고유 4-gram을 가지고 거의 모든 TVR 쿼리가 고유하다. 확대하여 디지털로 보는 것이 가장 좋다.
3.2 Data Analysis and Comparison
Table 1은 TVR의 개요와 기존 moment retrieval 데이터셋 [25, 8, 19, 3]과의 비교를 보여준다. TVR은 21.8K개의 비디오에 대해 109K개의 사람이 주석한 쿼리-모먼트 쌍을 포함하고 있어, 동종 데이터셋 중 가장 큰 규모이다. 모먼트의 평균 길이는 9.1초이며, 정확한 시작 및 종료 타임스탬프로 주석되어 있어, 더 정밀한 localization에 대한 학습 및 평가를 가능하게 한다. 기존 데이터셋과 비교했을 때, TVR은 상대적으로 짧은 (비디오 길이로 정규화된) 모먼트와 더 긴 쿼리를 가진다 (Fig. 2). 또한 더 큰 언어적 다양성을 보인다 (Fig. 3):
Table 2: 여러 동작을 포함하거나 여러 사람이 관련된 쿼리의 비율. 통계는 각 데이터셋에서 수동으로 라벨링된 100개의 쿼리를 기반으로 한다. 또한 고유한 인물 언급은 밑줄로, 동작은 굵게 표시된 쿼리 예시를 보여준다. 기존 데이터셋과 비교했을 때, TVR 쿼리는 일반적으로 더 많은 인물과 동작을 포함하며, 비디오와 자막(subtitle) 컨텍스트 모두를 필요로 한다.
| Dataset | #actions #people (%) (%) | Query examples (query type) | |
|---|---|---|---|
| TACoS 25 | 20 | 0 | She rinses the peeled carrots off in the sink. (video) <br> The person removes roots and outer leaves and rewashes the leek. (video) |
| CharadesSTA 8 | 6 | 12 | A person is eating food slowly. (video) <br> A person is opening the door to a bedroom. (video) |
| ActivityNet Caption 19 | 44 | 44 | He then grabs a metal mask and positions himself correctly on the floor. (video) <br> The same man comes back and lifts the weight over his head again. (video) |
| DiDeMo 13 | 6 | 10 | A dog shakes its body. (video) <br> A lady in a cowboy hat claps and jumps excitedly. (video) |
| TVR | 67 | 66 | Bert leans down and gives Amy a hug who is standing next to Penny. (video) <br> Taub argues with the patient that fighting in Hockey undermines the sport. (sub) <br> Chandler points at Joey while describing a woman who wants to date him. (video + sub) |
더 많은 고유한 4-gram을 포함하며, 거의 모든 쿼리가 고유하여 TVR의 텍스트 이해를 더 어렵게 만든다. TVR은 TV 쇼에서 수집되었기 때문에, 쿼리-모먼트 매칭은 종종 등장인물 간의 풍부한 상호작용을 이해하는 것을 포함한다. Table 2는 둘 이상의 동작이나 인물을 포함하는 쿼리의 비율을 데이터셋별로 비교하여 보여준다. TVR 쿼리의 66%는 최소 두 명의 인물을 포함하고, 67%는 최소 두 가지 동작을 포함하는데, 이 두 수치 모두 다른 데이터셋보다 현저히 높다. 이는 TVR을 사람들 간의 멀티모달 상호작용을 연구하기 위한 흥미로운 테스트베드로 만든다. 또한, 각 TVR 쿼리에는 쿼리 유형이 라벨링되어 있어, 해당 쿼리가 비디오, 자막 또는 둘 다에 기반하는지를 나타내며, 이는 시스템에 대한 더 깊은 분석에 활용될 수 있다.
4 Cross-modal Moment Localization (XML)
VCMR에서 목표는 쿼리 가 주어졌을 때, 대규모 비디오 코퍼스 에서 특정 순간을 검색하는 것이다. 각 비디오 는 연속적인 짧은 클립들의 리스트, 즉 로 표현된다. TVR에서는 각 짧은 클립이 시간적으로 정렬된 자막 문장과도 연관되어 있다. 검색된 순간은 로 표기된다. VCMR을 해결하기 위해 우리는 계층적 Cross-modal Moment Localization (XML) 네트워크를 제안한다. XML은 얕은(shallower) 레이어에서는 **비디오 검색(VR)**을 수행하고, 깊은(deeper) 레이어에서는 더 세분화된 **순간 검색(moment retrieval)**을 수행한다. 이 네트워크는 새로운 Convolutional Start-End (ConvSE) detector를 포함하는 late fusion 디자인을 사용하여 순간 예측을 효율적이고 정확하게 만든다.
4.1 XML Backbone Network
입력 표현 (Input Representations)
비디오를 표현하기 위해 우리는 외형(appearance) feature와 움직임(motion) feature를 모두 고려한다.
외형 feature의 경우, 3FPS로 2048D ResNet-152 [12] feature를 추출하고, 1.5초마다 feature를 max-pool하여 clip-level feature를 얻는다.
 Fig. 4: Cross-modal Moment Localization (XML) 모델 개요. Self=Self Encoder, Cross=Cross Encoder. XML Backbone은 Sec.4.1에서, ConvSE 모듈은 Sec. 4.2에서 설명하며, XML의 학습 및 추론 절차는 Sec. 4.3에서 보여준다.
Fig. 4: Cross-modal Moment Localization (XML) 모델 개요. Self=Self Encoder, Cross=Cross Encoder. XML Backbone은 Sec.4.1에서, ConvSE 모듈은 Sec. 4.2에서 설명하며, XML의 학습 및 추론 절차는 Sec. 4.3에서 보여준다.
움직임 feature의 경우, 1.5초마다 1024D I3D feature를 추출한다.
ResNet-152 모델은 이미지 인식을 위해 ImageNet [5]에서 사전학습되었고, I3D 모델은 행동 인식을 위해 Kinetics-600 [16]에서 사전학습되었다.
최종 비디오 표현은 두 feature를 L2-normalization 후 연결(concatenation)한 것으로, 로 표기하며, 여기서 은 비디오 길이(클립 수)이다.
우리는 12-layer RoBERTa [23]를 사용하여 contextualized text feature를 추출한다.
구체적으로, 먼저 TVR train-split의 쿼리(query)와 자막(subtitle) 문장을 MLM objective [6]로 RoBERTa를 fine-tuning한 다음, 파라미터를 고정하여 RoBERTa의 두 번째-마지막 layer에서 contextualized token embedding을 추출한다.
쿼리의 경우, 추출된 token embedding을 직접 사용하며, 로 표기한다. 여기서 는 쿼리 길이(단어 수)이다.
자막의 경우, 먼저 token-level embedding을 추출한 다음, 1.5초마다 max-pool하여 768D clip-level feature vector를 얻는다. 자막이 없는 경우에는 768D zero vector를 사용한다. 최종 자막 embedding은 로 표기한다.
추출된 feature들은 ReLU [11]가 적용된 linear layer를 통해 저차원 공간으로 투영된다. 그런 다음, 투영된 feature에 학습된 positional encoding [6]을 추가한다. 모호함 없이, 처리된 feature들을 로 재사용하여 표기하며, 여기서 는 hidden size이다.
쿼리 인코딩 (Query Encoding)
TVR 쿼리는 비디오 또는 자막과 관련될 수 있으므로, 우리는 쿼리를 두 개의 모듈화된 벡터로 동적으로 분해하는 모듈형 설계를 채택한다.
구체적으로, 쿼리 feature는 self-attention layer [31]와 linear layer로 구성된 Self-Encoder를 사용하여 인코딩되며, residual connection [12]과 layer normalization [1]이 뒤따른다.
인코딩된 쿼리는 로 표기한다.
그런 다음, 두 개의 학습 가능한 모듈형 가중치 벡터 를 적용하여 비디오() 또는 자막()에 대한 각 쿼리 단어의 attention score를 계산한다.
이 score는 의 정보를 집계하여 모듈화된 쿼리 벡터 [33]를 생성하는 데 사용된다:
컨텍스트 인코딩 (Context Encoding)
주어진 비디오 및 자막 feature 에 대해, 우리는 두 개의 Self-Encoder를 사용하여 단일 모달리티의 contextualized feature 와 를 계산한다.
그런 다음, Cross-Encoder를 통해 cross-modal 표현을 인코딩한다. Cross-Encoder는 self-modality 및 cross-modality feature를 입력으로 받아 cross-attention [31]과 linear layer, residual connection, layer normalization, 그리고 또 다른 Self-Encoder를 통해 두 feature를 인코딩한다.
최종 비디오 및 자막 표현은 각각 와 로 표기한다.
4.2 Convolutional Start-End Detector
및 가 주어졌을 때, 우리는 query-clip 유사도 점수 를 다음과 같이 계산한다:
로부터 moment prediction을 생성하기 위해, 각 proposal 영역의 점수 평균으로 계산된 confidence score를 사용하여 sliding window proposal의 순위를 매기거나, TAG [37]를 사용하여 상위 점수 영역을 점진적으로 그룹화할 수 있다. 그러나 두 방법 모두 수작업으로 정의된 규칙이 필요하며 학습이 불가능하다. 이미지 처리의 edge detector [29]에서 영감을 받아, 우리는 **점수 곡선에서 시작(up) 및 끝(down) edge를 학습하여 감지하는 두 개의 1D convolution filter를 가진 Convolutional Start-End detector (ConvSE)**를 제안한다. 의미적으로 가까운 span 내의 clip은 외부의 clip보다 query에 대한 유사도가 더 높을 것이며, 이는 자연스럽게 span 주변에 감지 가능한 edge를 형성한다. Fig. 4 (오른쪽) 및 Fig. 7은 학습된 ConvSE filter가 유사도 곡선에 적용된 예시를 보여준다. 구체적으로, 우리는 **두 개의 학습 가능한 filter (bias 없음)**를 사용하여 시작(st) 및 끝(ed) 점수를 생성한다:
이 점수들은 softmax로 정규화되어 확률 를 출력한다. Sec. 5.3에서 우리는 ConvSE가 baseline보다 우수하며 해석 가능함을 보여준다.
4.3 Training and Inference
비디오 검색 (Video Retrieval)
모듈화된 쿼리 와 인코딩된 context 가 주어졌을 때, 우리는 비디오 레벨 검색(VR) 점수를 다음과 같이 계산한다:
이는 본질적으로 각 클립과 쿼리 간의 cosine similarity를 계산하고 최댓값을 선택한다. 최종 VR 점수는 두 modality의 점수를 평균한 것이다.
학습 시, 우리는 각 positive pair 에 대해 두 개의 negative pair 와 를 샘플링하여 [33]과 같이 결합된 hinge loss를 계산한다:
단일 비디오 모먼트 검색 (Single Video Moment Retrieval)
시작 및 종료 확률 가 주어졌을 때, 우리는 단일 비디오 모먼트 검색 손실을 다음과 같이 정의한다:
여기서 와 는 ground-truth 인덱스이다. 추론 시, 예측은 dynamic programming [28]을 사용하여 선형 시간 내에 확률로부터 생성될 수 있다. 예측된 모먼트 의 신뢰도 점수는 다음과 같이 계산된다:
길이 사전 정보(length prior)를 사용하기 위해, 우리는 추가적인 제약 조건 를 추가한다. TVR의 경우, 클립 길이가 1.5초일 때 및 으로 설정한다.
비디오 코퍼스 모먼트 검색 (Video Corpus Moment Retrieval)
우리의 최종 학습 손실은 두 가지를 모두 결합한다: , 여기서 하이퍼파라미터 는 0.01로 설정된다. 추론 시, 우리는 다음 aggregation function을 사용하여 VCMR 점수를 계산한다:
여기서 는 쿼리 에 대한 모먼트 의 검색 점수이다. 지수 항(exponential term)과 하이퍼파라미터 는 두 점수의 중요도를 균형 있게 조절하는 데 사용된다. 값이 높을수록 상위 검색된 비디오에서 더 많은 모먼트를 선호하게 된다. 경험적으로 이 잘 작동함을 확인했다. 추론 시, 각 쿼리에 대해 먼저 을 기반으로 상위 100개 비디오를 검색한 다음, 100개 비디오 내의 모든 모먼트를 로 순위화하여 최종 예측을 제공한다.
5 Experiments
5.1 Data, Metrics and Implementation Details
데이터 (Data)
TVR은 21.8K개의 비디오에서 추출된 109K개의 쿼리를 포함한다. 우리는 TVR을 80% train, 10% val, 5% test-public, 5% test-private로 분할하며, 이때 비디오와 그에 연관된 쿼리는 오직 하나의 분할에만 포함되도록 한다. test-public은 공개 리더보드에 사용될 것이며, test-private은 향후 챌린지를 위해 보존된다.
평가 지표 (Metrics)
[7, 8]을 따라, 우리는 **모든 쿼리에 대한 평균 recall at K (R@K)**를 평가 지표로 사용한다. 예측이 정확하다고 판단되는 경우는 다음과 같다:
(i) 예측된 비디오가 ground truth와 일치하는 경우;
(ii) 예측된 시간 구간(span)이 ground truth와 높은 overlap을 가지는 경우. 이때 **temporal intersection over union (IoU)**이 overlap 측정에 사용된다.
구현 세부 사항 (Implementation Details)
모든 baseline 비교 모델은 XML과 동일한 hidden size를 사용하도록 설정되었다. 우리는 원 논문에 따라 baseline 모델들을 학습시켰다. 모든 모델에 동일한 feature를 사용하였다. baseline 모델들이 자막(subtitle)을 사용하여 retrieval을 지원하도록 하기 위해, 별도의 자막 스트림을 추가하고 두 스트림의 최종 예측을 평균하였다. Non-maximum suppression은 val set에서 일관된 성능 향상을 관찰하지 못했기 때문에 사용하지 않았다.
Table 3: TVR test-public 세트, VCMR task에 대한 Baseline 비교. 모델 참조: MCN [13], CAL [7], MEE [24], ExCL [10]
| Model | w/ video | w/ sub. | Runtime (seconds) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@100 | R@1 | R@5 | R@10 | R@100 | ||||
| Chance | - | - | 0.00 | 0.02 | 0.04 | 0.33 | 0.00 | 0.00 | 0.00 | 0.07 | |
| Proposal based Methods | |||||||||||
| MCN | 0.02 | 0.15 | 0.24 | 2.20 | 0.00 | 0.07 | 0.09 | 1.03 | - | ||
| CAL | 0.09 | 0.31 | 0.57 | 3.42 | 0.04 | 0.15 | 0.26 | 1.89 | - | ||
| Retrieval + Re-ranking | |||||||||||
| MEE+MCN | 0.92 | 3.69 | 5.58 | 17.91 | 0.42 | 1.89 | 2.98 | 10.84 | 66.8 | ||
| MEE+CAL | 0.97 | 3.75 | 5.80 | 18.66 | 0.39 | 1.69 | 2.98 | 11.52 | 161.5 | ||
| MEE+ExCL | 0.92 | 2.53 | 3.60 | 6.01 | 0.33 | 1.19 | 1.73 | 2.87 | 1307.2 | ||
| XML | 7.25 | 16.24 | 21.65 | 44.44 | 3.25 | 8.71 | 12.49 | 29.51 | 25.5 |
5.2 Baselines Comparison
이 섹션에서는 **TVR test-public 세트(5,445개 쿼리, 1,089개 비디오)**에서 XML과 baseline 모델들을 비교한다. 우리는 RTX 2080Ti GPU에서 3회 실행의 평균 런타임을 보고한다. 데이터 로딩, 전처리, 백엔드 모델(예: ResNet-152, I3D, RoBERTa) feature 추출 등에 소요되는 시간은 모든 방법에서 유사할 것이므로 무시한다. 여기서는 주로 VCMR task에 중점을 둔다. 보충 자료(supplementary file)에는 다음 실험들이 포함되어 있다: (1) 단일 비디오 모먼트 검색 및 비디오 검색 task에서의 모델 성능; (2) 1백만 비디오 코퍼스에서의 계산 및 저장 비용 비교; (3) Temporal Endpoint Feature (TEF) 13 모델 결과; (4) feature 및 모델 ablation study; (5) DiDeMo [13] 데이터셋에서의 VCMR 결과 등.
Proposal 기반 방법 (Proposal based Methods)
MCN [13]과 CAL [7]은 모먼트 검색 task를 모든 모먼트 proposal 후보들을 쿼리와의 제곱 유클리드 거리(squared Euclidean Distance)를 기반으로 순위를 매기는 랭킹 문제로 정의한다. VCMR의 경우, 이들은 각 쿼리에 대해 비디오 코퍼스 내의 **모든 proposal(다음 실험에서 95K개)**을 직접 랭킹해야 하므로, 비용이 많이 들고 어렵다. 이와 대조적으로, XML은 계층적 설계를 사용하여 얕은 layer에서는 비디오 검색을 수행하고, 더 깊은 layer에서는 검색된 비디오에 대해 모먼트 검색을 수행한다. Table 3에서 XML은 MCN과 CAL보다 현저히 높은 성능을 보여준다.
 Fig. 5: XML 모델의 성능 분석. 입력으로 비디오, 자막 또는 둘 다를 사용하는 경우에 대해 쿼리 유형별(괄호 안은 쿼리 비율) 성능을 보여준다. 성능은 VCMR에 대한 TVR val 세트에서 평가되었다.
Fig. 5: XML 모델의 성능 분석. 입력으로 비디오, 자막 또는 둘 다를 사용하는 경우에 대해 쿼리 유형별(괄호 안은 쿼리 비율) 성능을 보여준다. 성능은 VCMR에 대한 TVR val 세트에서 평가되었다.
검색+재랭킹 방법 (Retrieval+Re-ranking Methods)
우리는 또한 검색+재랭킹 설정 [7] 하의 방법들과도 비교한다. 이 설정에서는 먼저 주어진 방법으로 후보 비디오 세트를 검색한 다음, 다른 방법을 사용하여 후보 비디오 내의 모먼트 예측을 재랭킹한다. 구체적으로, 우리는 먼저 MEE [24]를 사용하여 각 쿼리에 대해 100개의 비디오를 후보로 검색한다. 그런 다음, MCN과 CAL을 사용하여 후보 비디오 내의 모든 proposal을 랭킹한다. ExCL [10]은 SVMR을 위해 설계된 early fusion 방법으로, start-end predictor를 포함한다. 우리는 Eq. 8을 사용하여 MEE 비디오 레벨 점수와 ExCL 모먼트 레벨 점수를 결합함으로써 이를 VCMR에 적용한다. 결과는 Table 3에 나와 있다. 순수하게 proposal 기반의 방법들(즉, MCN 및 CAL)과 비교하여, MEE+MCN과 MEE+CAL 모두 상당한 성능 향상을 달성했으며, 이는 (비디오 수를 줄임으로써) 랭킹해야 할 proposal 수를 줄이는 것의 이점을 보여준다. 그러나 이들은 매우 coarse-grained하고 미리 정의된 proposal을 사용하기 때문에 여전히 XML보다 훨씬 낮은 성능을 보인다. Sec. 5.3에서는 우리의 start-end detector가 XML 프레임워크에서 미리 정의된 proposal [7/37]보다 일관되게 더 나은 성능을 보임을 보여준다. MEE+ExCL과 비교하여, XML은 **9.85배의 성능 향상(3.25 대 0.33, R@1 IoU=0.7)**과 **51.3배의 속도 향상(25.5초 대 1307.2초)**을 달성한다. 보충 자료에서는 미리 인코딩된 비디오 표현을 사용하여 더 큰 규모의 비디오 코퍼스(1백만 비디오)에서 검색할 때 이 속도 향상이 훨씬 더 중요(287배)할 수 있음을 보여준다. 이 엄청난 속도 향상은 ExCL의 early fusion 설계에 비해 XML의 late fusion 설계의 효과를 보여준다.
5.3 Model Analysis
비디오 vs. 자막 (Video vs. Subtitle)
Fig. 5에서 우리는 비디오 또는 자막만을 사용하는 XML 변형 모델들과 비교하였다. 그 결과, 전체 비디오 + 자막 모델이 단일 모달리티 모델(비디오 및 자막)보다 전반적으로 더 나은 성능을 보였으며, 이는 두 모달리티 모두 유용함을 입증한다. 또한, 한 모달리티로 학습된 모델은 다른 모달리티로 태그된 쿼리에 대해 성능이 좋지 않음을 확인했다. 예를 들어, 비디오 모델은 자막 모델에 비해 자막 전용 쿼리(sub-only queries)에서 훨씬 낮은 성능을 보였다.
ConvSE: 비교 및 분석 (Comparison and Analysis)
쿼리-클립 유사도 신호로부터 moment 예측을 생성하기 위해, 우리는 1D 유사도 신호에서 시작(up) 및 끝(down) 경계(edge)를 감지하도록 학습하는 ConvSE를 제안했다. 그 효과를 보여주기 위해, 우리는 XML backbone 네트워크 하에서 ConvSE를 두 가지 baseline과 비교했다:
(1) Sliding window: 다중 스케일 sliding window로 생성된 proposal들을 순위 매기는 방식이다. 이때 proposal의 신뢰도 점수는 각 proposal 영역 내부 점수의 평균으로 계산된다. 평균적으로 비디오당 87개의 proposal을 생성한다. 여기서 사용된 proposal들은 이전 실험에서 MCN 및 CAL에 사용된 것과 동일하다.
(2) TAG [37]: 고전적인 watershed 알고리즘 [26]을 사용하여 상위 점수 클립들을 점진적으로 그룹화하는 방식이다.
이 두 가지 방법은 시작-끝 확률을 생성하지 않으므로, Equation 6의 objective로 모델을 학습시킬 수 없다. 따라서 우리는 Binary Cross Entropy loss를 사용하여 Equation 2의 쿼리-클립 유사도 점수를 직접 최적화했다. 이때 클립이 ground-truth 영역에 속하면 1, 그렇지 않으면 0의 레이블을 할당했다.
sliding window와 TAG 접근 방식이 수작업으로 정의된 규칙에 의존하는 반면, ConvSE는 데이터로부터 학습한다. Fig. 6 (왼쪽)에서 동일한 XML backbone 네트워크 하에서 ConvSE가 VCMR 및 SVMR task 모두에서 모든 IoU 임계값에 걸쳐 일관되게 더 나은 성능을 보임을 확인할 수 있다.
 Fig. 6: ConvSE 분석. 왼쪽: moment 생성 방법 비교. 오른쪽: ConvSE 필터의 커널 크기()별 비교.
Fig. 6: ConvSE 분석. 왼쪽: moment 생성 방법 비교. 오른쪽: ConvSE 필터의 커널 크기()별 비교.




Fig. 7: 학습된 ConvSE 필터가 쿼리-클립 유사도 점수에 적용된 예시. Ground truth 구간은 로 표시된 두 개의 화살표로 나타낸다. 두 필터가 시작(Start) 및 끝(End) 경계에서 더 강한 응답을 출력하는 것에 주목하라.
Fig. 6 (오른쪽)에서는 ConvSE 필터의 커널 크기()를 변화시켰다. 일 때 성능은 합리적이지만, 일 때 상당한 성능 저하를 관찰했다. 이 경우 필터는 본질적으로 점수에 대한 스케일링 계수로 퇴화한다. 이 비교는 인접 정보가 중요함을 보여준다. Fig. 7은 학습된 convolution 필터를 사용한 예시를 보여준다: 필터는 점수 곡선의 시작(Up) 및 끝(End) 경계에 더 강한 응답을 출력하여 이를 감지한다. 흥미롭게도, Fig. 7에서 학습된 가중치 Conv1D와 Conv1D는 이미지 처리의 경계 감지기 [29]와 유사하다.
 Fig. 8: TVR val 세트에서 VCMR에 대한 XML 예측 예시. 각 쿼리에 대해 상위 3개의 검색된 moment를 보여준다. 상단 행은 쿼리 단어에 대한 모듈형 attention 점수를 보여준다. 왼쪽 열은 올바른 예측을, 오른쪽 열은 실패를 보여준다. 점선 상자 안의 텍스트는 예측된 moment와 관련된 자막이다. 주황색 상자는 예측을, 녹색 막대는 ground truth를 보여준다.
Fig. 8: TVR val 세트에서 VCMR에 대한 XML 예측 예시. 각 쿼리에 대해 상위 3개의 검색된 moment를 보여준다. 상단 행은 쿼리 단어에 대한 모듈형 attention 점수를 보여준다. 왼쪽 열은 올바른 예측을, 오른쪽 열은 실패를 보여준다. 점선 상자 안의 텍스트는 예측된 moment와 관련된 자막이다. 주황색 상자는 예측을, 녹색 막대는 ground truth를 보여준다.
정성적 분석 (Qualitative Analysis)
Fig. 8은 TVR val 세트에서 XML 예측 예시를 보여준다. 상단 행에는 비디오 및 자막에 대한 쿼리 단어 attention 점수도 함께 보여준다. Fig. 8 (왼쪽)은 올바른 예측을 보여준다. 상위 2개의 moment는 동일한 비디오에서 나왔으며 둘 다 올바르다. 세 번째 moment는 다른 비디오에서 검색되었다. 비록 올바르지 않지만, '레스토랑'에서 일어나는 상황이므로 여전히 관련성이 있다. Fig. 8 (오른쪽)은 실패 사례를 보여준다. 잘못된 moment들이 올바른 예측과 'on the shoulder' vs. 'around the shoulder'와 같은 사소한 차이로 매우 가깝다는 점에 주목할 만하다. 또한, 어떤 단어가 비디오나 자막에 중요한지를 확인하는 것도 흥미롭다. 예를 들어, 'waitress', 'restaurant', 'menu', 'shoulder'와 같은 단어는 비디오에 대해 가장 높은 가중치를 얻는 반면, 'Rachel', 'menu', 'Barney', 'Ted'와 같은 단어는 자막에 대해 더 높은 attention 점수를 가진다.
6 Conclusion
본 연구에서는 멀티모달 순간 검색(moment retrieval) task를 위해 설계된 대규모 데이터셋인 TVR을 소개한다. 상세한 분석 결과, TVR은 높은 품질을 가지며 기존 데이터셋보다 더 도전적임을 보여준다. 또한 우리는 **VCMR(Video Corpus Moment Retrieval) task에 적합한 효율적인 모델인 Cross-modal Moment Localization (XML)**을 제안한다.
감사의 글 (Acknowledgements): 유익한 피드백을 제공해주신 심사위원들께 감사드린다. 본 연구는 NSF Award #1562098, DARPA MCS Grant #N66001-19-24031, DARPA KAIROS Grant #FA8750-19-2-1004, ARO-YIP Award #W911NF-18-1-0336, 그리고 Google Focused Research Award의 지원을 받았다.