VisCPM: 다국어 모델을 활용한 제로샷 멀티모달 학습
이 논문은 비영어권 국가에서 대규모 멀티모달 모델을 효과적으로 훈련하기 위한 새로운 패러다임인 MpM (Multilingual models can Pivot Multimodal learning)을 제안합니다. MpM은 강력한 다국어 LLM (Large Language Model)을 기반으로, 영어 이미지-텍스트 데이터만으로 훈련된 멀티모달 모델이 다른 언어에서도 뛰어난 (준)zero-shot 성능을 보이도록 합니다. 중국어를 예시로 개발된 VisCPM 모델은 image-to-text 및 text-to-image 생성 작업에서 기존 중국어 모델들을 능가하는 SOTA 성능을 달성했으며, 이는 비영어권 멀티모달 데이터 부족 문제를 해결할 새로운 가능성을 제시합니다. 논문 제목: Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages
논문 요약: VisCPM: 다국어 모델을 활용한 제로샷 멀티모달 학습
- 논문 링크: https://arxiv.org/abs/2308.12038
- 저자: Jinyi Hu, Yuan Yao, Chongyi Wang, Shan Wang, Yinxu Pan, Qianyu Chen, Tianyu Yu, Hanghao Wu, Yue Zhao, Haoye Zhang, Xu Han, Yankai Lin, Jiao Xue, Dahai Li, Zhiyuan Liu, Maosong Sun (Tsinghua University, Beijing University of Posts and Telecommunications, Shanghai Artificial Intelligence Laboratory, Renmin University of China, Zhihu Inc., ModelBest Inc.)
- 발표 시기: 2023년 (arXiv preprint)
- 주요 키워드: Multilingual Model, Multimodal Learning, LLM, Zero-shot Learning, Image-to-Text, Text-to-Image
1. 연구 배경 및 문제 정의
- 문제 정의: 대규모 멀티모달 모델의 발전은 주로 영어권에 집중되어 있으며, 비영어권 언어는 대규모의 고품질 이미지-텍스트 데이터 부족(저자원 특성)으로 인해 멀티모달 능력 개발이 현저히 뒤처져 있습니다. 기존 모델들은 수억에서 수십억 개의 이미지-텍스트 쌍을 필요로 하지만, 비영어권에서는 이러한 데이터 자원이 극히 부족합니다.
- 기존 접근 방식: 기존 멀티모달 모델들은 방대한 양의 언어별 이미지-텍스트 데이터를 기반으로 학습되었으며, 비영어권 언어의 경우 데이터 부족으로 인해 경쟁력 있는 모델을 구축하기 어려웠습니다. 일부 연구에서는 영어 데이터를 번역하여 사용하기도 했으나, 이는 상당한 컴퓨팅 자원을 소모하고 번역 품질 문제가 발생할 수 있습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 멀티모달 자원이 부족한 비영어권 언어를 위해 특별히 설계된 효과적인 학습 패러다임인 **MpM (Multilingual models can Pivot Multimodal learning)**을 제안합니다. 이를 통해 전 세계 연구자들이 영어의 고급 멀티모달 학습 방법을 각자의 언어에 빠르게 적용할 수 있습니다.
- MpM의 실제 적용 사례로 일련의 오픈 소스 중국어 대규모 멀티모달 모델인 VisCPM을 개발했으며, 이는 오픈 소스 중국어 멀티모달 모델 중 State-of-the-Art (SOTA) 성능을 달성합니다.
- VisCPM의 모델 가중치와 실험 세부 사항을 오픈 소스로 공개하여 다른 연구자들에게 귀중한 참고 자료가 되도록 합니다.
- VisCPM의 다양한 언어(총 6개 언어)에 대한 일반화 능력을 검증하고 다국어 멀티모달 대화 모델을 개발합니다.
- 제안 방법:
- MpM (Multilingual models can Pivot Multimodal learning) 패러다임: 강력한 **다국어 LLM (Large Language Model)**을 기반으로, 영어 전용 이미지-텍스트 데이터로 사전학습된 멀티모달 모델이 (준) zero-shot 방식으로 다른 언어에도 잘 일반화될 수 있음을 보여줍니다. 이는 시각적 의미론이 언어에 크게 독립적이라는 Bilingual Dual-coding Theory에서 영감을 받았습니다.
- 두 단계 학습 과정:
- 다국어 정렬 (Multilingual Alignment): 사전학습된 다국어 LLM을 백본으로 활용하여 다양한 언어에 대한 정렬된 표현을 구축합니다.
- 멀티모달 정렬 (Multimodal Alignment): 다국어 LLM을 기반으로 시각 모듈을 오직 영어 이미지-텍스트 쌍으로만 학습시켜 영어와 시각적 의미론을 정렬합니다. 다국어 LLM이 pivot 역할을 하여, 결과적인 멀티모달 모델은 다른 비영어권 언어에서 자연스럽게 zero-shot 멀티모달 능력을 습득합니다.
- VisCPM 구현: MpM의 실제 사례로 중국어를 대상 언어, 영어를 피벗 언어로 사용하여 중국어-영어 이중 언어 LLM인 CPM-Bee를 백본으로 활용했습니다.
- VisCPM-Chat (Image-to-Text): Muffin 아키텍처를 이미지 인코더로, CPM-Bee를 LLM으로 사용합니다. 영어 데이터로 사전학습 후, 소량의 번역된 중국어 데이터를 포함한 다국어 instruction tuning 데이터셋으로 파인튜닝하여 중국어 응답을 유도합니다.
- VisCPM-Paint (Text-to-Image): Stable Diffusion의 UNet을 이미지 디코더로, CPM-Bee를 LLM으로 사용합니다. 방대한 영어 이미지-텍스트 쌍 데이터셋(Laion-2B)으로 학습하여 텍스트-이미지 생성 능력을 확보합니다.
3. 실험 결과
- 데이터셋:
- 사전학습: COCO, Visual Genome, CC3M, CC12M, Laion-COCO, Laion-2B 등 주로 영어 이미지-텍스트 데이터셋을 사용했습니다. VisCPM-Chat+ 및 VisCPM-Paint+는 추가적으로 필터링된 Wukong, Zero (중국어 원어민 데이터) 및 번역된 Laion-COCO (중국어)를 포함했습니다.
- Instruction Tuning: LLaVA-Instruct-150K, UniMM-Chat (중국어-영어 이중 언어 버전), M3IT (영어 부분)을 활용했습니다.
- 평가: 이미지-텍스트 모델은 LLaVA Test Set 및 UniMM-Bench (GPT-4 평가)로, 텍스트-이미지 모델은 MSCOCO validation set (FID/CLIP score) 및 새로 구축된 Chinese Drawbench (인간 평가)로 평가했습니다.
- 주요 결과:
- VisCPM-Chat (이미지-텍스트):
- 중국어: LLaVA Test Set 및 UniMM-Bench에서 모든 기존 중국어 멀티모달 모델을 능가하며 SOTA 성능을 달성했습니다. 특히, 사전학습에 중국어 멀티모달 데이터를 전혀 사용하지 않았음에도 뛰어난 성능을 보였습니다.
- 영어: 기존의 강력한 영어 모델들(LLaVA, Qwen-VL-Chat 등)과 비교할 만한 성능을 유지했습니다.
- 문화 고유 지식 전이: 영어 데이터로만 사전학습했음에도 불구하고, 중국 문화 고유 지식(예: 중국 고전 시)을 성공적으로 연관 짓는 능력을 시연했습니다.
- 다국어 확장: LLaMA를 백본으로 사용하여 독일어, 프랑스어, 스페인어, 이탈리아어, 포르투갈어를 포함한 6개 언어에서 강력하고 일관된 멀티모달 대화 능력을 입증했습니다.
- VisCPM-Paint (텍스트-이미지):
- 중국어: MSCOCO validation set에서 가장 우수한 FID 성능을 달성하며, 기존 중국어 text-to-image 모델 대비 상당한 우위를 보였습니다.
- 인간 평가: 새로 구축된 Chinese Drawbench에서 인간 평가자들이 VisCPM-Paint가 생성한 이미지에 대해 Overall, Alignment, Fidelity 측면에서 가장 높은 선호도를 보였습니다.
- Ablation Study:
- 중국어 원어민 데이터셋만으로는 이미지-텍스트 및 텍스트-이미지 태스크 모두에서 좋은 성능을 달성하기에 불충분했습니다.
- 영어 데이터는 instruction tuning 단계에서 모델의 중국어 채팅 능력을 향상시키는 데 결정적인 역할을 했습니다.
- 원어민 데이터셋에 적용된 필터링 과정은 중국어 성능에 필수적이며, 필터링되지 않은 데이터는 성능을 저하시켰습니다.
- 중국어 원어민 데이터셋과 번역된 중국어 데이터셋을 통합하면 모델 성능에 미미한 개선이 나타났으나, 소량의 대상 언어 데이터가 응답 언어를 조정하는 데 중요함을 확인했습니다.
- VisCPM-Chat (이미지-텍스트):
4. 개인적인 생각 및 응용 가능성
- 장점:
- 혁신적인 저자원 문제 해결: 영어 데이터와 강력한 다국어 LLM을 활용하여 비영어권 언어의 멀티모달 모델 개발이라는 난제를 효과적으로 해결한 점이 가장 인상 깊습니다. 이는 데이터 부족으로 어려움을 겪는 많은 언어권에 새로운 가능성을 제시합니다.
- 뛰어난 제로샷/준제로샷 전이 능력: 영어 데이터로만 사전학습했음에도 중국어에서 SOTA 성능을 달성하고, 추가적인 5개 언어로도 성공적으로 확장된 것은 MpM 패러다임의 강력한 일반화 능력을 보여줍니다.
- 문화 고유 지식 전이: 학습 데이터에 명시적으로 포함되지 않은 중국 문화 관련 지식까지 성공적으로 전이하여 활용하는 능력은 다국어 LLM의 잠재력과 모델의 견고성을 입증합니다.
- 오픈 소스 공개: 모델 가중치와 코드를 공개하여 연구의 투명성과 재현성을 높이고, 후속 연구 및 실제 응용 개발에 크게 기여할 것입니다.
- 단점/한계:
- 완전한 제로샷이 아닌 "준-제로샷"이라는 점: 응답 언어를 대상 언어로 조정하기 위해 소량의 번역된 대상 언어 데이터가 instruction tuning 단계에서 필요하다는 한계가 있습니다.
- 다국어 LLM의 성능 의존성: MpM 패러다임은 강력한 다국어 LLM을 백본으로 활용하므로, 해당 언어에 대한 고품질 다국어 LLM이 부족한 경우에는 적용이 어려울 수 있습니다.
- 번역된 데이터의 품질 문제: 번역된 데이터의 품질이 모델 성능에 미치는 영향에 대한 추가적인 심층 분석이 필요할 수 있습니다.
- 응용 가능성:
- 다국어 멀티모달 챗봇 및 가상 비서: 다양한 언어를 지원하는 고성능 멀티모달 챗봇 및 가상 비서 개발에 직접적으로 활용될 수 있습니다.
- 글로벌 콘텐츠 생성 및 편집 도구: 비영어권 사용자를 위한 이미지 생성, 이미지 캡션 생성, 시각 자료 기반의 다국어 콘텐츠 자동 생성 및 편집 도구 개발에 기여할 수 있습니다.
- 교육 및 정보 접근성 향상: 시각 자료를 기반으로 다양한 언어로 정보를 제공하여 교육 콘텐츠의 접근성을 높이고, 언어 장벽을 넘어선 지식 공유를 촉진할 수 있습니다.
- 글로벌 비즈니스 및 고객 지원: 다국어 고객 지원 시스템, 제품 설명, 마케팅 자료 생성 등 글로벌 시장 확장을 위한 다양한 비즈니스 응용 분야에 적용될 수 있습니다.
5. 추가 참고 자료
Hu, Jinyi, et al. "Large multilingual models pivot zero-shot multimodal learning across languages." arXiv preprint arXiv:2308.12038 (2023).
Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages
Jinyi Hu Yuan Yao Chongyi Wang Shan Wang Yinxu Pan Qianyu Chen Tianyu Yu Hanghao Wu Yue Zhao Haoye Zhang Xu Han Yankai Lin Jiao Xue Dahai Li Zhiyuan Liu Maosong Sun <br> Tsinghua University Beijing University of Posts and Telecommunications<br> Shanghai Artificial Intelligence Laboratory Renmin University of China<br> Zhihu Inc. ModelBest Inc.<br>hu-jy21@mails.tsinghua.edu.cn
Abstract
최근 이미지-텍스트 및 텍스트-이미지 생성 분야에서 멀티모달 학습이 크게 발전하고 있다. 그러나 이러한 성공은 일반적으로 영어에 국한되어 있으며, 다른 언어들은 크게 뒤처져 있다. 비영어권 멀티모달 데이터의 저자원 특성(low-resource nature), 즉 대규모의 고품질 이미지-텍스트 데이터 부족으로 인해 다른 언어에서 경쟁력 있는 모델을 구축하는 것은 매우 어렵다.
본 연구에서는 비영어권 언어에서 대규모 멀티모달 모델을 학습하기 위한 효과적인 학습 패러다임인 MpM을 제안한다. MpM은 다국어 language model이 언어 간 zero-shot 멀티모달 학습을 Pivot할 수 있음을 보여준다. 구체적으로, 강력한 다국어 대규모 language model을 기반으로, 영어 전용 이미지-텍스트 데이터로 사전학습된 멀티모달 모델이 (준) zero-shot 방식으로 다른 언어에도 잘 일반화될 수 있으며, 심지어 해당 언어의 이미지-텍스트 데이터로 학습된 모델보다도 뛰어난 성능을 보일 수 있다.
MpM의 실제 적용 사례로 중국어를 택하여, 이미지-텍스트 및 텍스트-이미지 생성 분야에서 대규모 멀티모달 모델 VISCPM을 구축하였다. VISCPM은 중국어에서 state-of-the-art (오픈 소스) 성능을 달성한다. 향후 연구를 촉진하기 위해 코드와 모델 가중치를 https://github.com/OpenBMB/VisCPM 에 공개한다.
1 Introduction
GPT-4 (OpenAI, 2023) 및 Stable Diffusion (Rombach et al., 2022)과 같은 강력한 모델들이 멀티모달 능력에서 빠르게 발전함에 따라, 대규모 멀티모달 모델은 **AGI(Artificial General Intelligence)**를 추구하는 최신 연구 분야로 부상했다. 일반적으로 이미지와 텍스트를 아우르는 멀티모달 생성 능력은 두 가지 범주로 나눌 수 있다: (i) 이미지-텍스트 생성 분야에서는 GPT-4 (OpenAI, 2023), LLaVA (Liu et al., 2023a), InstructBLIP (Dai et al., 2023)과 같은 저명한 멀티모달 large language model들이 이미지를 기반으로 뛰어난 멀티모달 대화 및 추론 능력을 보여준다. (ii) 텍스트-이미지 생성 분야에서는 Imagen (Saharia et al., 2022) 및 Stable Diffusion (Rombach et al., 2022)과 같은 모델들이 텍스트 prompt를 기반으로 매우 사실적이고 관련성 높은 이미지를 생성하는 데 탁월하다. 이러한 모델들은 이미지와 텍스트를 처리하는 탁월한 능력을 보유하고 있으며, 학계와 산업계 모두에서 멀티모달 AI의 지형을 심오하게 재편하고 있다.
그러나 대규모 멀티모달 모델의 성공은 주로 영어권 커뮤니티 내에서 달성되었으며, 다른 비영어권 언어에서의 멀티모달 능력은 현저히 뒤처져 있다. 이러한 격차를 해소하는 것은 멀티모달 모델 학습에 필요한 방대한 이미지-텍스트 쌍 데이터 요구 사항 때문에 어렵다. 예를 들어, BLIP-2 (Li et al., 2023a)의 pretraining은 1억 개 이상의 고품질 이미지-텍스트 쌍을 포함하며, Stable Diffusion (Rombach et al., 2022)은 20억 개 이상의 쌍을 활용한다. 비영어권 언어에서는 이러한 멀티모달 데이터 자원이 부족하여, 이들 언어에서의 멀티모달 연구 진행이 계속해서 지연되고 있다.
이러한 도전을 해결하기 위해 우리는 비영어권 언어의 대규모 멀티모달 모델을 위한 효과적인 학습 패러다임인 MpM을 제안한다. MpM은 Multilingual language model을 활용하여 언어 간 멀티모달 학습을 Pivot하며, 상당한 멀티모달 데이터 자원을 포함하는 영어를 시각 신호와 멀티모달 데이터가 일반적으로 부족한 비영어권 언어 사이의 pivot으로 간주한다. MpM은 시각적 의미론이 언어에 크게 독립적이라고 주장하는 Bilingual Dual-coding Theory (Paivio, 2014; Clark & Paivio, 1991)에서 영감을 얻었다. 직관적으로, Fig. 1a에 묘사된 바와 같이, 다국어 학습자는 확립된 멀티모달 및 다국어 정렬을 기반으로 시각적 의미론을 새로 습득한 언어와 효과적으로 정렬할 수 있다. 인간의 학습 과정을 모방하여, MpM 또한 비영어권 멀티모달 학습을 **다국어 정렬(multilingual alignment)**과 **멀티모달 정렬(multimodal alignment)**의 두 가지 연속적인 단계로 나눈다. 전자는 다국어 모델 구축에 중점을 두는 반면, 후자는 여러 언어를 아우르는 멀티모달 모델로 귀결된다.
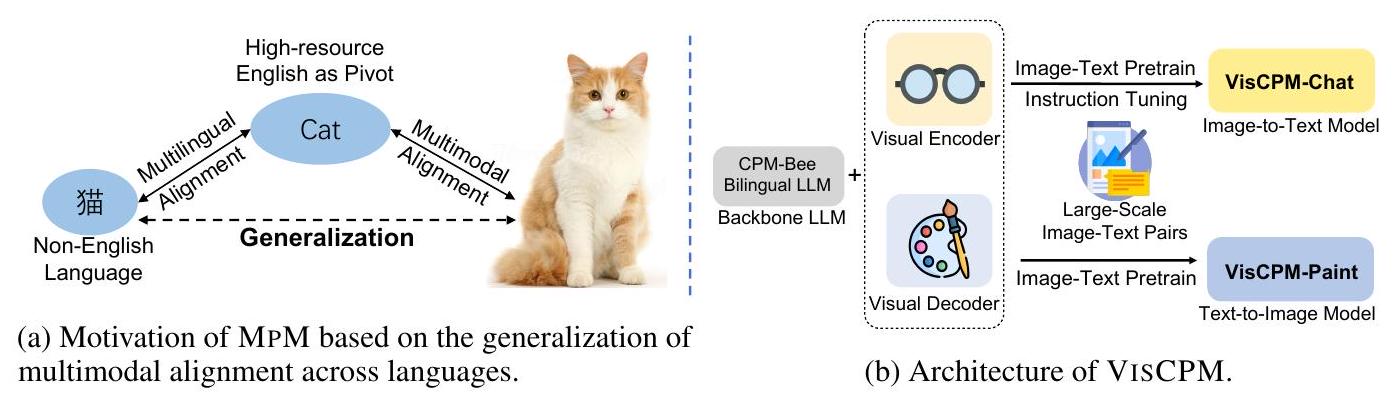
Figure 1: MpM과 VisCPM의 동기 및 아키텍처 개요.
구체적으로, 다국어 정렬을 위해 MpM은 사전학습된 multilingual large language model (LLM)을 backbone language model로 활용하여, 다양한 언어에 대한 정렬된 표현(aligned representation)을 제공한다. 다음으로, 멀티모달 정렬을 위해 MpM은 multilingual model을 기반으로 visual module을 오직 영어 이미지-텍스트 쌍으로만 학습시켜 영어와 시각적 의미론을 정렬한다. 인간이 학습하는 방식과 유사하게, multilingual model을 pivot 지점으로 사용함으로써, 결과적인 멀티모달 모델은 다른 비영어권 언어에서 자연스럽게 zero-shot 멀티모달 능력을 습득한다.
MpM의 실제 사례로 중국어를 택하여, 우리는 영어-중국어 이중 언어 large language model인 CPM-Bee (Zhang et al., 2021)를 기반으로 VisCPM이라는 중국어 대규모 멀티모달 모델을 개발했다. 주목할 점은, 오직 영어 이미지-텍스트 쌍으로만 사전학습했음에도 불구하고, VISCPM의 중국어 zero-shot 성능이 기존의 중국어 이미지-텍스트 쌍으로 학습된 중국어 멀티모달 모델들의 성능을 능가한다는 것이다. MpM의 중국어에서의 유망한 성능은 더 넓은 언어에서의 잠재적 적용 가능성을 시사한다. 동일한 학습 과정을 따라, 우리는 LLaMA (Touvron et al., 2023)를 기반으로 영어, 독일어, 프랑스어, 스페인어, 이탈리아어, 포르투갈어를 포함한 6개 언어를 지원하는 multilingual multimodal conversation model을 개발하여 MpM을 더욱 확장했다.
요약하면, 본 논문의 기여는 다음과 같다: (i) 우리는 멀티모달 자원이 부족한 비영어권 언어를 위해 특별히 설계된 효과적인 학습 패러다임인 MpM을 제안한다. 전 세계 연구자들은 MpM을 활용하여 영어의 고급 멀티모달 학습 방법을 각자의 언어에 빠르게 적용할 수 있다. (ii) 우리는 MpM의 실제 적용 사례로 일련의 중국어 대규모 멀티모달 모델인 VISCPM을 개발했으며, 이는 오픈 소스 중국어 멀티모달 모델 중 state-of-the-art 성능을 달성한다. (iii) 우리는 VISCPM의 모델 가중치를 오픈 소스로 공개하고 실험 세부 사항을 제공하여 다른 연구자들에게 귀중한 참고 자료가 되도록 한다. (iv) 우리는 다양한 언어에서 VISCPM의 일반화 능력을 검증하고 6개 언어를 아우르는 multilingual multimodal conversation model을 개발한다.
2 Related Work
Image-to-text Models
기존의 image-to-text 생성 모델은 주로 이미지 캡션(image caption) 및 visual question answering task에 중점을 두었다 (Yuan et al., 2021, Yu et al., 2022a, Wang et al., 2022b). 최근에는 image-to-text의 주류가 멀티모달 LLM으로 전환되어, LLM이 사용자와 멀티모달 상호작용을 할 수 있도록 하는 데 초점을 맞추고 있다. 이러한 모델들은 visual module과 LLM을 perceiver(예: BLIP-2 (Li et al., 2023a) 및 InstructBLIP (Dai et al., 2023)) 또는 linear projector(예: LLaVA (Liu et al., 2023a) 및 PandaGPT (Su et al., 2023))로 연결한다. VPGTrans (Zhang et al., 2023)는 **LLM 간 visual module의 전이성(transferability)**을 탐구한다. 한편, 많은 노력이 멀티모달 instruction following 데이터셋 구축에 집중되었다. LLaVA (Liu et al., 2023a)와 MiniGPT-4 (Zhu et al., 2023)는 GPT-4를 사용하여 이미지 캡션을 대화 데이터로 변환함으로써 시각 콘텐츠 관련 대화를 구축한다. InstructBLIP (Dai et al., 2023) 및 IT (Li et al., 2023b)는 다운스트림 vision-language 데이터셋을 통합하여 instruction 데이터를 구성한다. LLaVA-RLHF (Sun et al., 2023) 및 RLHF-v (Yu et al., 2023b)는 신뢰할 수 있는 행동을 위한 멀티모달 RLHF를 제안한다.
Text-to-image Models
text-to-image 모델 개발 초기 단계에서는 생성적 적대 신경망(generative adversarial networks) (Zhu et al., 2019; Li et al., 2019)과 자기회귀 생성(auto-regressive generation) (Esser et al., 2021)이 text-to-image 합성 모델 (Li et al., 2019)에 널리 선택되는 아키텍처였다. 최근에는 DALLE-2 (Ramesh et al., 2022), Imagen (Saharia et al., 2022), Stable Diffusion (Rombach et al., 2022)과 같은 대규모 diffusion 기반 text-to-image 모델이 중심에 서서 탁월한 생성 능력을 보여주고 있다.
Multilingual Multimodal Models
멀티모달 모델을 더 많은 언어로 확장하는 것은 지난 몇 년간 핵심 연구 초점이 되었다. 연구자들은 지식 증류(knowledge distillation) (Carlsson et al., 2022, Hu et al., 2023) 또는 contrastive learning (Bianchi et al., 2021; Chen et al., 2023) 기술을 사용하여 강력한 이미지-텍스트 모델인 CLIP (Radford et al., 2021)을 더 많은 언어를 처리하도록 확장하기 위해 노력해왔다. 다른 연구들은 다국어 vision-language 사전학습을 위한 범용 프레임워크를 만들고 다국어 및 멀티모달 정렬을 동시에 달성하는 것을 목표로 했다 (Ni et al., 2021; Zhou et al., 2021; Zeng et al., 2023). LLM 시대에는 PaLI (Chen et al., 2022)가 100개 언어에 걸친 10B 이미지-텍스트 쌍을 기반으로 17B 다국어 언어-이미지 모델을 개발했다. Ying-VLM (Li et al., 2023b)은 영어에서의 instruction tuning이 다른 언어로 일반화될 수 있음을 보여준다. MultiFusion (Bellagente et al., 2023)은 다국어 언어 모델이 text-to-image 생성에서 cross-lingual transfer에 도움이 될 수 있음을 발견했다. 이에 비해 본 연구는 다국어 멀티모달 모델 학습을 위한 보다 체계적인 공식화를 제공하고, 이러한 모델의 zero-shot transfer 성능이 native-language 멀티모달 데이터로 학습된 모델의 성능을 능가할 수 있음을 보여준다.
3 MpM Training Paradigm
이 섹션에서는 먼저 다국어 멀티모달 학습(multilingual multimodal learning)의 공식화를 제시하고, MPM의 학습 절차에 대한 개요를 제공한다. 이어서, 이미지-텍스트 생성(image-to-text generation)과 텍스트-이미지 생성(text-to-image generation)을 위한 MPM의 구체적인 학습 절차를 상세히 설명한다.
3.1 Problem Formulation and Overview
멀티모달 학습은 이미지()와 텍스트() 간의 관계를 특정 대상 언어()로 모델링하는 것으로 정식화될 수 있다. 이러한 맥락에서,
- **이미지-텍스트 생성(image-to-text generation)**은 입력 이미지에 대한 설명을 생성하는 것으로, 에 의해 parameterized된 조건부 분포 를 학습하는 것이다.
- **텍스트-이미지 생성(text-to-image generation)**은 입력 텍스트 prompt가 주어졌을 때 관련 이미지를 합성하는 것으로, 에 의해 parameterized된 를 학습하는 것이다.
일반적인(vanilla) 설정에서 이러한 조건부 분포는 일반적으로 대상 언어 의 이미지-텍스트 쌍 을 사용하여 학습된다 (Radford et al., 2021, Yang et al., 2022). 그러나 대부분의 언어에서 고품질 이미지-텍스트 쌍은 극히 부족하다. 원어 이미지-텍스트 쌍에 대한 의존성을 완화하기 위해, 우리는 풍부한 멀티모달 쌍 을 포함하는 pivot language 를 도입한다. 여기서 이다. 시각적 개념을 다양한 학습된 언어와 자연스럽게 정렬할 수 있는 인간의 학습 메커니즘을 모방하여, MPM은 pivot language에서 학습된 시각적 개념을 대상 언어로 전이(transfer)하는 것을 목표로 한다.
MpM은 대상 언어 에서의 멀티모달 학습 과정을 두 가지 연속적인 단계로 나눈다: 다국어 정렬(multilingual alignment)과 멀티모달 정렬(multimodal alignment).
- 다국어 정렬을 위해 MpM은 와 간의 cross-lingual alignment를 구축하는 것을 목표로 한다. 이는 **사전학습된 다국어 LLM(로 표기)**을 직접 활용하여 달성된다. 이 LLM은 유사한 의미를 가진 텍스트 쌍 와 에 대해 유사한 hidden representation을 제공할 수 있다. 즉, 이다.
- 멀티모달 정렬을 위해 MpM은 pivot language의 충분한 멀티모달 자원 를 활용하여 이미지-텍스트 목표 와 텍스트-이미지 목표 를 최적화한다.
다음 섹션에서는 멀티모달 정렬 단계의 학습 과정을 소개한다. MPM은 특정 모델 아키텍처나 학습 방법에 구애받지 않으므로, 각 task에서 기존의 매우 효과적인 모델 아키텍처와 학습 기술을 유연하게 활용할 수 있다는 점에 주목할 필요가 있다.
3.2 Image-to-text Generation
이미지-텍스트 생성에서는 **이미지 인코더 모듈 **를 통합하여 시각적 feature 를 제공한다. 이 시각적 feature 는 텍스트 임베딩과 연결되어 다국어 LLM의 입력으로 사용된다.
최근 멀티모달 대화 모델 학습 연구(Zhu et al., 2023, Liu et al., 2023a)를 따라, MpM의 이미지-텍스트 생성 학습 과정은 두 가지 하위 단계로 구성된다: Multimodal Pretraining과 Instruction Tuning.
Multimodal Pretraining. 이 하위 단계에서는 시각 모듈을 사전학습하여 대규모 이미지-텍스트 쌍 데이터셋에서 언어 모델링 objective를 사용하여 LLM과 정렬시킨다:
여기서 우리는 LLM의 강력한 능력이 이미지-텍스트 쌍의 짧은 텍스트에 의해 영향을 받는 것을 방지하기 위해 LLM의 파라미터()를 고정한다.
Instruction Tuning. 모델이 인간의 지시를 따르는 능력을 향상시키기 위해, 우리는 기존 멀티모달 instruction tuning 데이터셋을 피벗 언어(pivot language)와 대상 언어(target language)로 번역된 버전을 혼합하여 정교하게 큐레이션된 멀티모달 instruction tuning 데이터셋으로 instruction tuning을 수행한다. 이 다국어 instruction tuning 데이터셋을 로 표기하며, 여기서 는 특정 언어 의 지시(instruction)이고 는 해당 언어의 응답(response)이다. 시각 모듈과 다국어 LLM 모두 fine-tuning되며, 즉 , 응답의 확률을 최대화한다:
흥미롭게도, 우리는 이 시나리오에서 **다국어 멀티모달 모델의 준-zero-shot 전이 능력(quasi-zero-shot transfer capability)**을 발견했다. 만약 대상 언어로 번역된 변형을 제외하고 피벗 언어만을 사용하여 instruction tuning을 수행한다면, 대상 언어로 된 이미지 와 질문 또는 지시 가 주어졌을 때, 결과 모델은 정확하게 응답하지만 대부분 피벗 언어로 응답한다. 이는 다국어 LLM이 제공하는 두 언어의 지시의 hidden representation이 매우 유사하기 때문으로 설명할 수 있다. 즉, 이다. 결과적으로, 우리는 를 얻는다. 사전학습 및 instruction tuning 단계 모두 피벗 언어로만 텍스트 구성 요소를 사용하기 때문에, LLM은 대상 언어로 된 질문을 이해할 수 있지만, 동일한 언어로 응답을 조정할 수는 없다.
모델이 대상 언어로 응답하도록 유도하기 위해, MPM은 instruction tuning 동안 소수의 대상 언어 번역 쌍을 통합한다. 이러한 방식으로 MpM은 모델의 지시 따르기 능력(instruction-following capability)을 동시에 향상시키고 응답 언어를 조정하여, 궁극적으로 대상 언어로 된 멀티모달 챗봇을 구현한다.
3.3 Text-to-image Generation
**텍스트-이미지 생성(text-to-image generation)**에서는 **Stable Diffusion (Rombach et al., 2022)**과 유사한 아키텍처를 채택한다. 이 아키텍처는 **UNet 구조 (Ronneberger et al., 2015)**를 가진 **denoising network **를 포함하며, 이는 입력 prompt가 주어졌을 때 이미지를 생성하는 image decoder 역할을 한다. LLM 와 image decoder 는 cross-attention 메커니즘 (Vaswani et al., 2017)으로 상호 연결된다.
**Diffusion model (Ho et al., 2020; Song et al., 2020)**은 가우시안 노이즈를 데이터 분포로 denoising하는 반복적인 과정을 학습한다. denoise network는 LLM이 제공하는 텍스트 입력의 hidden state를 조건으로 하여, 노이즈가 추가된 이미지 의 노이즈를 제거하도록 최적화된다. 학습 목표는 다음과 같이 정의된다:
이 단계에서 이며, 즉 image decoder는 frozen된 LLM에 맞춰 학습된다. 이러한 방식으로, 타겟 언어의 새로운 prompt 가 입력되었을 때, 다국어 LLM 는 유사한 의미를 가진 pivot 언어 prompt의 학습된 표현 에 가까운 표현 을 본질적으로 제공할 수 있다. 따라서 타겟 언어에서의 텍스트-이미지 생성 능력은 zero-shot 방식으로 pivot 언어로부터 원활하게 전이될 수 있으며, 이는 로 표현된다.
4 VisCPM
MpM의 실천으로서, 우리는 VisCPM이라는 일련의 대규모 중국어 멀티모달 모델을 개발한다. 우리는 **중국어를 목표 언어(target language)**로, **영어를 피벗 언어(pivot language)**로 사용한다. **중국어-영어 이중 언어 모델인 CPM-Bee (Zhang et al., 2021)**는 백본 다국어 LLM 역할을 한다.
우리는 모델의 두 가지 변형을 가지고 있다:
- VISCPM-Chat: 이미지-텍스트 멀티모달 대화를 위한 모델
- VISCPM-Paint: 텍스트-이미지 합성을 위한 모델
다음 섹션에서는 기존 중국어 멀티모달 데이터셋에 대한 개요를 제공한 다음, VisCPM-Chat 및 VisCPM-Paint의 학습 절차를 소개한다.
4.1 Are Chinese Multimodal Datasets Enough To Train A Multimodal Model?
현재 공개된 중국어 멀티모달 데이터셋 중 가장 큰 규모는 Wukong (Gu et al. 2022)으로, 1억 개의 이미지-텍스트 쌍으로 구성되어 있다. 그러나 Figure 2에서 볼 수 있듯이, Chinese-CLIP (Yang et al., 2022)으로 계산된 CLIP score를 시각화하고, Appendix G에서 소개된 대로 수동으로 검사한 결과, Wukong 데이터셋의 이미지-텍스트 쌍 중 의미적으로 일치하는 내용은 극히 일부에 불과하다는 것을 발견했다. 이러한 데이터셋의 낮은 품질은 기존 데이터 자원 부족 문제를 더욱 심화시킨다.
중국어 이미지-텍스트 쌍의 수를 늘리는 간단한 방법은 영어 이미지-텍스트 쌍을 중국어로 번역하는 것이며, 이는 이전 연구 (Wang et al., 2022a, Qiu et al., 2022)에서도 활용되었다. 그러나 번역에는 외부 기계 번역 모델이 필요하며, 사전학습에 사용되는 대규모 데이터셋을 번역하는 데는 상당한 컴퓨팅 자원이 소모된다.
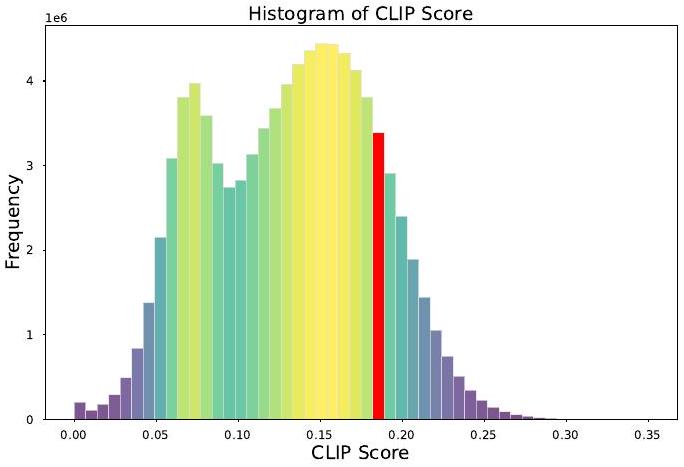
Figure 2: Wukong 데이터셋의 1억 개 중국어 이미지-텍스트 쌍에 대한 CLIP score 히스토그램. 우리는 0.18을 적절한 필터링 임계값으로 설정했다.
또한, Section 5.3에서 논의했듯이, 우리는 강력한 cross-lingual generalization 능력을 이미 갖춘 강력한 multimodal LLM을 backbone language model로 사용할 때, 번역된 이미지-텍스트를 포함하는 것이 성능에 미미한 개선만을 가져온다는 것을 실질적으로 확인했다. 이러한 분석을 바탕으로, 우리는 멀티모달 정렬(alignment)에서 기존 영어 데이터를 효과적으로 활용하여 지식 전이(knowledge transfer)를 달성하는 것이 강력한 중국어 대규모 멀티모달 모델을 개발하는 데 핵심이라고 주장한다.
4.2 6d VISCPM-CHAT
VISCPM-Chat은 입력 이미지에 기반하여 사용자의 지시에 응답할 수 있는 중국어-영어 이중 언어 멀티모달 챗봇이다. VISCPM-Chat은 Muffin 아키텍처 (Yu et al., 2023a)를 이미지 인코더로 활용한다. 특히, Muffin은 사전학습된 vision-language model인 BEiT-3 (Wang et al., 2023)를 비전과 언어 사이의 내재적인 브릿지 모듈로 직접 활용한다.
멀티모달 사전학습 단계에서, visual module은 1억 개의 이미지-텍스트 쌍으로 180K 스텝 동안 학습되어 **frozen LLM과 정렬(align)**된다. instruction tuning 서브 단계에서는 LLaVA 150K (Liu et al., 2023a) 및 UniMM-Chat (Yu et al., 2023a)의 이중 언어 버전과 MIT (Li et al., 2023b)의 영어 부분을 활용하여 이미지 인코더와 LLM을 80K 스텝 동안 fine-tune한다. 이 데이터셋에 대한 자세한 내용은 Appendix B.2에 제시되어 있다. Sec. 3.2에서 소개된 중국어의 quasi-zero-shot 현상 때문에, 우리는 LLaVA 150K와 UniMM-Chat을 기계 번역을 사용하여 중국어로 번역하여 특정 중국어 데이터를 통합하였다.
중국어 이미지-텍스트 쌍의 효과를 입증하기 위해, 우리는 VisCPM-Chat의 추가 버전을 학습시켰다. 이 버전은 사전학습 단계에서 추가적인 중국어 이미지-텍스트 쌍을 포함한다. 여기에는 1억 개의 Wukong (Gu et al., 2022) 데이터셋에서 CLIP 점수 임계값 0.18 이상으로 필터링된 2천만 개의 원어 중국어 이미지-텍스트 쌍과 2천만 개의 Zero-Chinese (Xie et al., 2022) 데이터셋, 그리고 Laion-COCO 데이터셋에서 번역된 1억 3천 6백만 개의 이미지-텍스트 쌍이 포함된다. 우리는 이 모델을 **VisCPM-Chat+**라고 명명한다.
Table 1: GPT-4로 접근한 LLaVA Test Set에 대한 실험 결과. Con: Conversation, DD: Detailed Description, CR: Complex Reasoning, AVG: 세 가지 task의 평균 점수. 최고/두 번째 최고 결과는 각각 굵게(bold) 및 밑줄(underlined)로 표시되어 있다.
| Model | LLM Backbone | English | Chinese | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Con | DD | CR | AVG | Con | DD | CR | AVG | |||
| MiniGPT-4 (Zhu et al., 2023) | Vicuna-13B | 65.0 | 67.3 | 76.6 | 69.7 | - | - | - | ||
| English Model | InstructBLIP (Dai et al., 2023) | Vicuna-13B | 81.9 | 68.0 | 91.2 | 80.5 | - | - | - | - |
| LLaVA (Liu et al., 2023a | Vicuna-13B | 89.5 | 70.4 | 96.2 | 85.6 | - | - | - | - | |
| En-Zh Bilingual Model | mPLUG-Owl (Ye et al., 2023 | BLOOMZ-7B | 64.6 | 47.7 | 80.1 | 64.2 | 76.3 | 61.2 | 77.8 | 72.0 |
| VisualGLM (Du et al., 2022 | ChatGLM-6B | 62.4 | 63.0 | 80.6 | 68.7 | 76.6 | 87.8 | 83.6 | 82.7 | |
| Ziya-Visual (Wang et al., 2022a) | Ziya-LLaMA-13B | 82.7 | 69.9 | 92.1 | 81.7 | 85.0 | 74.7 | 82.4 | 80.8 | |
| Qwen-VL-Chat (Bai et al., 2023 | Qwen-7B | 82.4 | 76.9 | 91.9 | 82.3 | 93.4 | 89.5 | 88.2 | ||
| VisCPM-Chat | CPM-Bee-10B | 81.4 | 69.2 | 93.1 | 81.4 | 87.4 | 90.9 | |||
| VisCPM-Chat+ | CPM-Bee-10B | 80.1 | 67.1 | 97.1 | 81.5 | 91.3 | 90.7 | 95.4 | 92.5 |
4.3 VisCPM-PAINT
VISCPM-Paint는 중국어와 영어 프롬프트를 모두 받아들일 수 있는 text-to-image 합성 모델이다. VISCPM-Paint는 Stable Diffusion [Rombach et al., 2022]의 UNet을 이미지 decoder로 활용한다. UNet의 생성 능력을 유지하기 위해, 학습 과정에서는 UNet의 cross-attention layer와 다국어 LLM과 UNet 사이의 linear transblock만을 포함한다. 우리는 방대한 영어 이미지-텍스트 쌍 데이터셋인 Laion-2B [Schuhmann et al., 2022]를 사용하여 300K 스텝 동안 이 파라미터들을 최적화한다.
**VISCPM-Chat+**와 유사하게, 우리는 중국어 이미지-텍스트 쌍으로 fine-tuning된 VISCPM-Paint의 추가 버전을 학습시킨다. 이 쌍들의 구성 요소는 ViSCPM-Chat+가 사용하는 것과 동일하다. 우리는 이 모델을 **VisCPM-Paint+**라고 명명한다.
5 Experiments
5.1 Evaluation of VisCPM-Chat
5.1.1 Evaluation Setting
Baselines. 우리는 VISCPM-Chat을 기존 멀티모달 대화 모델들과 비교하였다. 여기에는 영어 전용 모델인 MiniGPT-4 (Zhu et al., 2023), InstructBLIP (Dai et al., 2023), LLaVA (Liu et al., 2023a)가 포함되며, 중국어-영어 이중 언어 모델로는 mPLUG-Owl (Ye et al., 2023), VisualGLM (Du et al., 2022), Ziya-Visual (Wang et al., 2022a), Qwen-VL-Chat (Bai et al., 2023)이 포함된다. 이 모든 중국어-영어 모델들은 중국어 및 영어 멀티모달 데이터셋에 대해 대규모 학습을 수행하였다. Baseline에 대한 더 자세한 내용은 Appendix C에 제시되어 있다.
Evaluation Benchmark. 우리는 VisCPM-Chat의 멀티모달 대화 능력을 영어와 중국어 모두에서 LLaVA Test Set (Liu et al., 2023a)과 UniMM-Bench (Yu et al., 2023a)을 사용하여 평가하였다. 우리는 CPM-Bee를 사용하여 이들을 중국어로 번역하고 번역 결과를 수동으로 확인하였다. 구체적으로, LLaVA는 "conversation", "detailed description", "complex reasoning" 측면에서 모델의 멀티모달 대화 능력을 종합적으로 평가한다. UniMM-Bench는 일반적으로 사용되는 visual question-answering 데이터셋(OKVQA (Marino et al., 2019), AOKVQA (Schwenk et al., 2022), GQA (Hudson & Manning, 2019), VQAv2 (Antol et al. 2015) 포함)에서 추출되었으며, 특히 **추론(reasoning), 상식(commonsense), 세계 지식(world knowledge)**과 관련된 능력을 평가하기 위해 설계되었다. 멀티모달 대화 모델이 질문에 대해 완전한 문장으로 응답을 생성하는 것이 일반적이므로, VQAScore (Antol et al., 2015)와 같은 전통적인 문자열 일치 기반 metric은 이 맥락에서 적합하지 않다. 따라서 LLaVA Test Set과 UniMM-Bench의 경우, Liu et al. (2023a); Yu et al. (2023a)의 방식을 따라 GPT-4를 사용하여 모델이 생성한 응답과 참조 답변을 평가하였다. LLaVA Test Set과 UniMM-Bench에 대한 더 자세한 내용은 Appendix D.3에 제시되어 있다.
Table 2: UniMM-Bench에서 이중 언어 멀티모달 모델의 중국어 평가 결과. 영어 결과는 Table 6에서 확인할 수 있다.
| Model | OKVQA | AOKVQA | GQA | VQAv2 | AVG |
|---|---|---|---|---|---|
| mPLUG-Owl | 52.8 | 55.8 | 60.8 | 56.7 | 56.5 |
| VisualGLM | 53.7 | 57.5 | 64.8 | 62.5 | 59.6 |
| Ziya-Visual | 59.2 | 58.1 | 61.9 | 59.1 | 59.6 |
| Qwen-VL-Chat | 58.5 | 58.5 | 70.6 | 72.0 | 64.9 |
| VisCPM-Chat | 62.8 | 64.9 | 68.3 | 71.8 | 67.0 |
Table 3: Vicuna 기반의 더 많은 언어로의 확장 결과.
| Lang | Con | DD | CR | AVG |
|---|---|---|---|---|
| 87.6 | 76.8 | 101.0 | 88.6 | |
| 90.8 | 80.8 | 93.6 | 88.7 | |
| 87.6 | 81.9 | 94.6 | 88.2 | |
| 87.1 | 79.6 | 102.3 | 89.8 | |
| 84.5 | 79.5 | 93.3 | 85.9 | |
| 81.3 | 81.6 | 92.4 | 85.1 |
5.1.2 Experimental Results
정량적 결과 (Quantitative Results)
LLaVA Test Set과 UniMM-Bench에 대한 평가 결과는 Table 1과 Table 2에 제시되어 있다.
중국어의 경우, VISCPM-Chat은 두 벤치마크 모두에서 뛰어난 결과를 달성하며 모든 baseline 모델을 능가한다.
주목할 점은, VisualGLM과 Qwen-VL-Chat이 사전학습 과정에서 상당수의 중국어 이미지-텍스트 쌍을 활용한 것과 달리, VISCPM-Chat은 사전학습 과정에 어떠한 중국어 멀티모달 데이터도 포함하지 않았다는 것이다.
그럼에도 불구하고, VISCPM-Chat은 대화 능력, 상식, 그리고 세계 지식 측면에서 우수한 성능을 보여준다.
이러한 결과는 MPM이 시각적 지식을 영어에서 중국어로 전이하는 데 효과적임을 강력하게 입증한다.
영어의 경우, VisCPM-Chat의 성능은 mPLUG-Owl, VisualGLM, InstructBLIP, MiniGPT-4를 능가하며, Ziya-Visual 및 Qwen-VL-Chat과 거의 동등한 수준을 보이고, 강력한 baseline인 LLaVA와도 비교할 만한 성능을 유지한다.
사례 연구 (Case Study)
광범위한 세계 지식과 상식을 습득하는 것 외에도, MPM 학습은 VISCPM-Chat의 중국 문화 고유 지식 전이 능력을 암묵적으로 자극했다.
예를 들어, Fig. 3에서 볼 수 있듯이, VISCPM-Chat은 보름달과 정자를 보고 소식(苏轼)의 "수조가두(水调歌头)"에 나오는 중국 고전 시를 연관 지을 수 있다.
이 이미지-텍스트 쌍은 중국 문화와 깊이 연관되어 있으며 학습 데이터에 포함되지 않았음에도 불구하고, VISCPM-Chat은 MPM 학습을 통해 이러한 비범한 지식 전이를 성공적으로 수행한다.
VISCPM-Chat과 관련된 사례에 대한 더 자세한 분석은 Appendix B.3을 참조하라.

Figure 3: VisCPM-Chat의 중국어 멀티모달 대화 사례.
5.1.3 Generalization to More Languages
VISCPM-Chat이 중국어 MpM에서 보여준 놀라운 결과는 더 다양한 언어로의 잠재적인 광범위한 적용 가능성을 보여준다. 특히, 우리는 다국어 LLM인 LLaMA (Touvron et al., 2023)를 LLM backbone으로 활용하고, 독일어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어를 대상 언어로 고려한다. VISCPM-Chat과 동일한 학습 절차를 따라, 우리는 6개 언어를 능숙하게 지원하는 다국어 멀티모달 챗봇을 개발한다.
먼저, 영어 이미지-텍스트 쌍에서 시각 feature 정렬(alignment)을 달성하기 위해 LLaMA와 함께 visual encoder를 사전학습한다. 다음으로, M2M-100 (Fan et al., 2021)을 사용하여 LLaVA의 instruction training set을 5개 대상 언어로 번역한다. 원본 영어 instruction training set과 5개의 번역된 세트를 병합하고 섞은 다음, visual module과 LLM을 fine-tuning하는 데 사용한다.
Table 3은 LLaVA Testset에 대한 영어 및 5개 대상 언어의 평가 결과를 보여준다. IGLUE 벤치마크 (Bugliarello et al., 2022) 결과는 Appendix D.5에서 확인할 수 있다. 특히, 독일어, 프랑스어, 스페인어와 같이 비교적 인기 있는 언어의 평균 점수는 88점을 초과한다. 또한, 이탈리아어와 포르투갈어의 평균 점수는 85점 이상이다. 이러한 결과는 5개 대상 언어가 instruction tuning 과정에서 단순히 혼합되었음에도 불구하고, 챗봇이 6개 언어 모두에서 시각 관련 질문에 대해 일관되고 정확한 응답을 제공함을 보여주므로 매우 고무적이다. 이들 언어에서의 결과는 다양한 언어적 맥락에서 강력한 멀티모달 모델을 구축하는 데 있어 MPM의 일반화 능력과 견고성을 입증한다.
Table 4: MSCOCO 데이터셋에 대한 Zero-shot FID
| Model | FID | |
|---|---|---|
| En | Ch | |
| GLIDE (Nichol et al., 2022, | 12.2 | - |
| Make-A-Scene (Gafni et al., 2022, | 11.8 | - |
| DALL-E-2 (Ramesh et al., 2022 | 10.4 | - |
| UniDiffuser (Bao et al., 2023 | 9.7 | - |
| CogView2 (Ding et al., 2022, | - | 24.0 |
| Stable Diffusion (Rombach et al., 2022) | 8.6 | - |
| AltDiffusion (Chen et al., 2023 | 17.2 | 16.1 |
| TaiyiDiffusion (Wang et al., 2022a | - | 15.6 |
| VISCPM-Paint | 9.5 | |
| VISCPM-Paint+ | 9.9 | 9.6 |
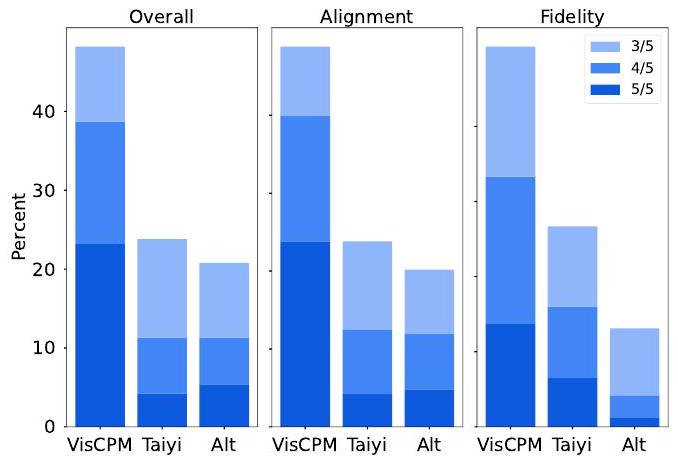
Figure 4: Chinese Drawbench에 대한 text-to-image 인간 평가 결과.
5.2 Evaluation of Viscpm-Paint
5.2.1 Evaluation Setting
우리는 VISCPM-Paint를 여러 강력한 text-to-image 모델들과 비교한다. 여기에는 영어 전용 모델들인 GLIDE (Nichol et al., 2022), Make-A-Scene (Gafni et al., 2022), DALL·E-2 (Ramesh et al., 2022), UniDiffuser (Bao et al., 2023)와, 중국어 또는 중영 혼합 text-to-image 모델들인 CogView2 (Ding et al., 2022), AltDiffusion (Chen et al., 2023), TaiyiDiffusion (Wang et al., 2022a)가 포함된다. 우리는 주로 VISCPM-Paint를 AltDiffusion (Chen et al., 2023)과 TaiyiDiffusion (Wang et al., 2022a)과 비교한다. 각 baseline 모델에 대한 더 자세한 내용은 Appendix C에 제시되어 있다.
5.2.2 Automatic Evaluation
텍스트-이미지 task의 경우, 우리는 MSCOCO validation set (Lin et al., 2014)을 사용하여 zero-shot Frechet Inception Distance (FID) (Heusel et al. 2017)와 CLIP score (Ramesh et al., 2021)를 평가한다. MSCOCO에서 3만 개의 prompt를 샘플링하며, 중국어 평가를 위해서는 원문 영어 caption을 중국어 텍스트 prompt로 번역한다. VisCPM-Paint, AltDiffusion, TaiyiDiffusion에 대해 동일한 샘플링 설정을 유지하고, 8개의 classifier guidance scale에 걸쳐 최적의 FID를 grid search한다.
Table 4는 MSCOCO validation set에서의 zero-shot FID 결과를 보여준다. 중국어의 경우, VisCPM-Paint가 가장 우수한 FID 성능을 달성한다. 영어 이미지-텍스트 쌍으로만 학습되었음에도 불구하고, VisCPM-Paint는 AltDiffusion (Chen et al., 2023) 및 TaiyiDiffusion (Wang et al., 2022a)에 비해 상당한 우위를 보인다. 영어의 경우, VisCPM-Paint의 성능은 Stable Diffusion (Rombach et al., 2022) 및 UniDiffuser (Bao et al., 2023)와 같은 기존의 강력한 text-to-image 모델들과 비교할 만한 수준이다. 충실도(fidelity)와 정렬(alignment) 간의 trade-off에 대한 더 자세한 분석은 Appendix E.2를 참조하라.
5.2.3 Human Evaluation
이전 연구(Yu et al., 2022b; Chang et al., 2023)에 따라, 우리는 모델 성능에 대한 보다 포괄적인 이해를 위해 **인간 평가(human evaluation)**를 수행했다. 중국어에는 인간 평가 벤치마크가 부족하기 때문에, 우리는 Chinese Drawbench라는 중국어 text-to-image 인간 평가 벤치마크를 새로 만들었다. Chinese Drawbench는 174개의 prompt로 구성되어 있으며, text-to-image 모델의 다양한 측면에서의 숙련도를 평가한다. 우리는 Chinese Drawbench에서 **VISCPM-Paint, AltDiffusion (Chen et al., 2023), TaiyiDiffusion (Wang et al., 2022a)**에 대한 인간 평가를 수행했다. 우리는 5명의 독립적인 평가자에게 각 prompt에 대해 세 모델이 생성한 이미지 중 가장 좋은 이미지를 판단하도록 요청했다. 평가 기준에는 Overall, Alignment, Fidelity가 포함되었다. 인간 평가 및 Chinese Drawbench에 대한 자세한 내용은 Appendix E.3에 제공되어 있다.
Figure 4는 인간 평가 결과를 보여준다. 이 그림은 세 가지 측면에서 합의에 대한 다른 마진을 가진 각 생성 이미지에 대한 5명의 평가자의 선호도 점유율을 보여준다. 특히, VISCPM-Paint는 세 가지 평가 측면 모두에서 가장 강력한 선호도를 얻었다. 각 측면에서 VISCPM-Paint가 생성한 이미지의 40% 이상이 선호되는 선택이었다. 인상 깊게도, Overall과 Alignment라는 보다 객관적인 지표에서 VISCPM-Paint는 20% 이상의 5/5 선호도를 얻었다. 이러한 결과는 VISCPM-Paint가 생성한 이미지의 품질이 두 baseline 모델에 비해 우수함을 강력하게 보여준다.
Table 5: 각 학습 단계에서 데이터셋 언어의 다양한 조합에 따른 중국어 성능. IT는 instruction tuning을 의미한다. (a) Image-to-text: LLaVA Test Set에 대한 평가 결과.
| Dataset Language | Con | DD | CR | AVG | |
|---|---|---|---|---|---|
| Pretrain | IT | ||||
| Native Chinese | Chinese | 82.4 | 81.8 | 91.7 | 85.5 |
| English | Chinese | 84.0 | 83.6 | 91.2 | 86.3 |
| English | Bilingual | 85.4 | 81.4 | 96.6 | 88.0 |
| English+ Native Chinese | Bilingual | 89.1 | 82.3 | 91.4 | 87.8 |
| English+ Native Chinese+ Translated Chinese | Bilingual | 90.3 | 81.4 | 92.1 | 88.2 |
(b) Text-to-image: MSCOCO에 대한 zero-shot FID.
| Dataset Language | FID | |
|---|---|---|
| Pretrain | Finetune | |
| Native Chinese | - | 15.1 |
| English | - | 10.9 |
| English | Native Chinese w/o Filter | 12.8 |
| English | Native Chinese | 10.7 |
| English | Native Chinese + Translated Chinese | 9.6 |
5.3 Ablation Study
우리는 데이터셋 언어 ablation study를 수행하여, 다양한 데이터셋 언어 조합이 이미지-텍스트 및 텍스트-이미지 task에서 멀티모달 모델의 성능에 미치는 영향을 조사하였다. 효율성을 높이기 위해, 이미지-텍스트 task에서는 LLaVA 150K만을 instruction tuning에 사용하였다. 각 실험의 상세 설정은 Appendix F에 보고되어 있다. Table 5a와 Table 5b에 제시된 결과를 바탕으로 다음과 같은 관찰을 할 수 있었다:
(i) 중국어 원어민 데이터셋에만 의존하는 것은 이미지-텍스트 및 텍스트-이미지 task 모두에서 좋은 성능을 달성하기에 불충분하다. 중국어 원어민 데이터셋만으로 학습된 모델은 더 낮은 점수를 보였는데, 이미지-텍스트 모델은 평균 85.5점, 텍스트-이미지 모델은 15.1 FID를 기록했다.
(ii) 영어 데이터는 instruction tuning 단계에서 모델의 중국어 채팅 능력을 향상시키는 데 결정적인 역할을 한다. 이미지-텍스트 모델이 대규모 영어 데이터셋으로 사전학습된 후, 단일 언어 중국어 instruction tuning 데이터셋으로 fine-tuning될 경우, 이중 언어 instruction tuning 데이터셋을 활용한 모델과 비교하여 평균 성능이 88.0에서 86.3으로 하락하는 것을 경험했다.
(iii) 원어민 데이터셋에 적용된 필터링 과정은 중국어 성능에 필수적이다. 텍스트-이미지 task에서, 영어 데이터로 사전학습한 후 필터링되지 않은 중국어 원어민 멀티모달 쌍으로 fine-tuning했을 때, FID는 zero-shot 시나리오의 10.9에서 12.8로 악화되었다.
(iv) 중국어 원어민 데이터셋과 번역된 중국어 데이터셋을 통합하면 모델 성능에 미미한 개선이 나타난다. 구체적으로, 이미지-텍스트 모델의 사전학습 단계 또는 텍스트-이미지 모델의 fine-tuning 단계에 중국어 원어민 데이터를 추가하는 것은 지표에서 0.2의 변화만을 가져왔지만, 번역된 데이터셋을 추가로 혼합하면 FID가 10.7에서 9.6으로 향상되었다. Table 1에 나타난 VISCPM-Chat에서 VISCPM-Chat+로의 개선 또한 동일한 결과를 확인시켜준다. 우리는 Appendix D.4에서 중국어 instruction tuning 데이터셋의 다양한 비율이 응답 언어 정확도 및 내용 품질에 미치는 영향에 대한 보다 체계적인 탐구를 제시한다.
6 Conclusion
본 연구에서는 비영어권 언어에서 대규모 멀티모달 모델을 효과적으로 학습시키기 위해 설계된 혁신적인 학습 패러다임인 MPM을 소개한다. MPM은 다국어 LLM을 시각 신호와 목표 언어 사이의 핵심적인 중개자로 활용함으로써, 멀티모달 정렬(alignment) 지식을 다양한 언어에 걸쳐 효율적으로 전이시킨다.
MPM을 기반으로 우리는 오픈소스 중국어 대규모 멀티모달 모델인 VisCPM을 개발했으며, 이 모델은 중국어 이미지-텍스트 및 텍스트-이미지 task에서 뛰어난 능력을 보여준다.
실험 결과에 따르면, VisCPM은 오직 영어 멀티모달 데이터에만 의존하여 중국어 오픈소스 멀티모달 모델 중 SOTA 성능을 달성할 수 있음을 입증하였다.
나아가 우리는 6개 언어를 지원하는 다재다능한 멀티모달 챗봇을 구축하여 언어 범위를 확장하였다.
우리는 MPM의 효과가 전 세계 대규모 멀티모달 모델 개발에 기여하여, 다양한 언어와 문화권에서 정교한 멀티모달 모델의 발전을 촉진할 것이라고 믿는다.
Appendix
A Contributions
저자들의 기여는 다음과 같이 요약할 수 있다:
프로젝트 준비 단계:
- Jinyi Hu와 Yuan Yao는 모델 아키텍처를 설계했다.
- Xu Han, Yankai Lin, Jiao Xue, Dahai Li, Zhiyuan Liu, Maosong Sun은 모델 아키텍처를 개선하는 데 귀중한 지침을 제공했다.
- Shan Wang, Chongyi Wang, Jinyi Hu는 사전학습에 필요한 방대한 멀티모달 데이터셋을 수집하고 처리하는 역할을 담당했다.
- Hanghao Wu, Yue Zhao, Haoye Zhang, Yuan Yao는 instruction tuning 데이터 구축에 협력했다.
- Jinyi Hu, Chongyi Wang, Tianyu Yu, Qianyu Chen, Shan Wang은 학습 코드베이스를 공동으로 구현했다.
모델 학습 단계:
- Chongyi Wang, Tianyu Yu, Yinxu Pan은 VISCPM-Chat 학습을 담당했다.
- Jinyi Hu, Shan Wang, Qianyu Chen은 VisCPM-Paint 학습을 담당했다.
모델 평가 단계:
- Jinyi Hu와 Yuan Yao는 평가 프레임워크를 설계했다.
- Chongyi Wang과 Tianyu Yu는 VisCPM-Chat을 평가했다.
- Jinyi Hu와 Shan Wang은 VISCPM-Paint의 자동 평가를 수행하고, VisCPM-Paint의 인간 평가를 조직했다.
논문 작성 단계:
- Jinyi Hu와 Yuan Yao는 본 논문의 주요 내용을 작성했다.
- Yankai Lin, Zhiyuan Liu, Maosong Sun은 논문 작성을 다듬는 데 제안을 제공했다.
공개 활용성 단계:
- Jinyi Hu, Yinxu Pan, Chongyi Wang, Shan Wang, Yuan Yao는 VISCPM의 오픈 소스화를 추진했다.
- Yinxu Pan은 VISCPM의 온라인 데모 및 API를 개발했다.
- Chongyi Wang과 Yinxu Pan은 VISCPM의 저자원 추론(low-resource inference)을 구현했다.
프로젝트 전반에 걸쳐 Xu Han, Yankai Lin, Jiao Xue, Dahai Li, Zhiyuan Liu, Maosong Sun은 귀중한 기술적 지침과 조언을 제공했다.
B Dataset
B. 1 Pretraining Dataset
COCO (Lin et al., 2014): COCO 데이터셋은 일상적인 장면과 일반적인 객체를 포함하는 세심하게 구성된 이미지 캡션 데이터셋이다. 이 데이터셋은 118,287개의 이미지로 구성된 학습 세트를 포함하며, 각 이미지에는 5개의 고유한 캡션이 제공된다. 데이터셋을 한 번 통과할 때마다 우리는 하나의 캡션을 무작위로 선택하여, 총 이미지 수의 5배에 해당하는 591,435개의 이미지-텍스트 쌍을 생성한다.
Visual Genome (Krishna et al., 2017): Visual Genome은 객체에 대한 상세한 주석으로 풍부하게 레이블링된 이미지 데이터셋이다. 우리가 사용한 학습 세트는 약 10만 개의 이미지를 포함하며, 각 이미지에는 평균 8개의 고유한 캡션이 함께 제공된다.
CC3M (Sharma et al., 2018): Conceptual Captions으로도 알려진 CC3M 데이터셋은 약 330만 개의 이미지-텍스트 쌍을 포함한다. CC3M은 웹에서 수집되었으며, 캡션의 품질과 정보성을 높이기 위해 신중하게 처리되었다. 일부 손상된 이미지 링크로 인해 최종적으로 성공적으로 다운로드된 데이터셋은 약 280만 개의 쌍을 포함한다.
CC12M (Changpinyo et al., 2021): CC12M 데이터셋은 CC3M (Sharma et al., 2018)의 확장 버전으로, 거의 1,200만 개의 이미지-텍스트 쌍을 포함한다. 이 데이터셋을 생성하기 위해 더 완화된 수집 파이프라인이 사용되었다. 다운로드 후, 우리의 데이터셋은 약 600만 개의 쌍으로 구성된다.
Laion2B (Schuhmann et al. 2022): Laion-2B는 인터넷의 공개적으로 접근 가능한 영역에서 수집된 이미지 데이터로 구성된 대규모 데이터셋이다. 우리가 성공적으로 다운로드한 결과, 약 13억 개의 방대한 이미지 컬렉션을 얻었다.
Laion-COCO (Christoph et al., 2022): Laion-COCO는 Laion-2B 데이터셋의 하위 집합으로, 6억 개의 이미지 항목을 포함한다. 이 이미지들은 BLIP (Li et al., 2022)을 사용하여 MS COCO 스타일을 모방한 고품질 설명을 생성하도록 캡션되었다.
Wukong (Gu et al., 2022): Wukong은 중국어 이미지-텍스트 쌍 1억 개로 구성된 데이터셋으로, 이미지는 이미지 크기에 따라 필터링되고, 텍스트는 언어, 길이, 빈도에 따라 필터링된다.
Table 6: UniMM-Bench 영어 버전에서 이중 언어 멀티모달 챗 모델 평가 결과.
| Model | OKVQA | AOKVQA | GQA | VQAv2 | AVG |
|---|---|---|---|---|---|
| mPLUG-Owl | 66.7 | 62.5 | 63.0 | 66.0 | 64.6 |
| VisualGLM | 57.6 | 62.8 | 58.1 | 63.9 | 60.6 |
| Ziya-Visual | 66.1 | 68.7 | 67.4 | 67.3 | 67.4 |
| Qwen-VL-Chat | 71.4 | 77.9 | 77.9 | 74.0 | |
| VISCPM-Chat | 65.4 | 75.5 | 71.5 | 76.6 | 72.3 |
Table 7: 멀티모달 챗 모델의 아키텍처, 파라미터, 학습 데이터 요약. 여기서 mPlug-Owl의 학습 데이터 크기와 Ziya-Visual의 학습 데이터에서 중국어 및 영어의 비율은 해당 모델 카드에 보고된 내용이다.
| Model | Visual Module | LLM | Training Data |
|---|---|---|---|
| mPlug-Owl | ViT-L/14 (0.3B) | BLOOMZ-7B | - |
| VisualGLM | Q-Former (1.6B) | ChatGLM-6B | English: 300M; Chinese 30M |
| Ziya-Visual | Q-Former (1.1B) | Ziya-LLaMA-13B-v1 | 20M |
| Qwen-VL-Chat | ViT-bigG (1.9B) | Qwen-7B | English: 1.1B; Chinese: 300M |
| VisCPM-Chat | Muffin (0.7B) | CPM-Bee-10B | English: 140M; Chinese: 1M |
Zero (Xie et al., 2022): 검색 엔진에서 수집된 Zero 데이터셋은 2천만 개의 이미지와 해당 텍스트 설명으로 구성되며, 이는 사용자 클릭률을 기반으로 50억 개의 이미지-텍스트 쌍 풀에서 선택되었다.
B. 2 Instruction Tuning Dataset
LLaVA-Instruct-150K (Liu et al., 2023a)
LLaVA-Instruct-150K는 GPT4에 의해 생성된 멀티모달 instruction-following 데이터셋이다. 이 데이터셋을 생성할 때, 이미지 캡션과 해당 bounding box를 활용하여 이미지를 텍스트 시퀀스로 인코딩한 후, 텍스트 전용 GPT4 모델에 입력하였다. LLaVA-Instruct-150K는 데이터셋을 Conversation, Detailed Description, Complex Reasoning의 세 가지 유형으로 나눈다. 각 유형에 대해 수동으로 설계된 예시들을 prompt에 포함시켜 GPT4의 in-context learning에 활용하였다.
(Li et al., 2023b)
IT 데이터셋은 captioning, reasoning, visual question-answering을 포함한 다양한 vision-language task를 다루는 downstream 데이터셋을 활용하여 큐레이션된 대규모 멀티모달 instruction tuning 데이터셋 모음이다. 이 데이터셋들은 통합된 이미지-텍스트 스키마로 재구성되었다. 주요 데이터셋에서 파생된 특정 구성된 인스턴스들은 총 100개 언어로 번역되었다. 데이터셋의 비중국어 부분에 대해서는 추가 번역을 진행하지 않았다는 점에 유의해야 한다.
UniMM-Chat (Yu et al., 2023a)
UniMM-Chat은 맞춤형 지식 집약 멀티모달 대화 데이터셋이다. UniMM-Chat은 MSCOCO (Lin et al., 2014)의 이미지와 관련 labeled 데이터셋을 데이터 생성의 기반으로 활용한다. 관련 데이터셋에는 **VQAv2 (Antol et al., 2015), Visual Dialogue (Das et al., 2017), OKVQA (Marino et al., 2019), AOKVQA (Schwenk et al., 2022)**가 포함된다. 초기 단계에서는 동일한 이미지에 대한 다양한 데이터셋의 어노테이션 정보(질문-답변 쌍, 대화, rationale 정보, 이미지 캡션 등)를 병합한다. 이러한 다양한 텍스트 어노테이션은 이미지 콘텐츠에 대한 다각적인 시각을 제공하여 ChatGPT가 이미지를 포괄적으로 해석할 수 있도록 돕는다.
Table 8: 텍스트-이미지 모델의 아키텍처 및 학습 데이터 요약.
| Model | Visual Module | Text Encoder | Training Data |
|---|---|---|---|
| AltDiffusion | UNet | AltCLIP | - |
| TaiyiDiffusion | UNet | Taiyi-CLIP-RoBERTa | English: 0; Chinese: 20M |
| VISCPM-Paint | UNet | CPM-Bee | English: 1.3 B ; Chinese: 0 |
Table 9: Chinese Drawbench의 다양한 카테고리에 대한 설명 및 예시.
| Category | Description | Example |
|---|---|---|
| Relation | Ability to generate objects with specific interaction relationship between them | "挂在衣架上的一个帽子" (옷걸이에 걸린 모자.) |
| Compositional | Ability to multiply kinds of objects | "一个盘子上放有黄色的梨和紫色的苹果" (접시 위에 노란 배와 보라색 사과가 있다.) |
| Attribute | Ability to accurately generate objects with given attributes,such as size,color,and action. | "一件蓝色的天鹅绒晚礼服" (파란색 벨벳 이브닝 드레스.) |
| Counterintuitive | Ability to generate unusual scene against common sense | "穿着宇航服的李白开宇宙飞船" (우주복을 입은 이백이 우주선을 조종한다.) |
| Rare Word | Ability to understand rare expression | 窗台上的一盆剑兰 (창턱 위의 글라디올러스 화분.) |
| Count | Ability to generate given numbers of objects | 三块涂有黄油的面包 (버터 바른 빵 세 조각.) |
| Long Input | Ability to understand long and complex input | 平静的湖面上,船夫划着船桨在湖面上划过,泛起涟漪,一只鸟飞过水面,抓起来一只鱼 (잔잔한 호수 위에서 뱃사공이 노를 저어 지나가며 잔물결을 일으키고, 새 한 마리가 물 위를 날아 물고기를 잡는다.) |
| Chinese Culture | Ability to generate scene related to Chinese Culture | 海上生明月,天涯共此时 (바다 위로 밝은 달이 떠오르니, 멀리서도 이 순간을 함께하네.) |
Table 10: VISCPM-Chat의 사전학습에 사용된 이미지-텍스트 데이터셋 상세 정보. "bil"은 영어와 번역된 중국어의 혼합 버전을 의미한다.
| Datasets | Size | Weight | Epoch |
|---|---|---|---|
| VISCPM-Chat | |||
| COCO+Visual Genome | 626 K | 12.50% | 27.60 |
| CC3M+CC12M | 8.4 M | 25.00% | 16.40 |
| Laion-COCO | 390 M | 62.50% | 0.35 |
| VISCPM-Chat+ | |||
| COCO+VG | 626 K | 12.50% | 15.33 |
| CC12M | 5.6 M | 25.00% | 3.43 |
| Zero+Wukong | 20 M | 12.50% | 0.48 |
| CC3M-bil | 5.6 M | 12.50% | 1.72 |
| Laion-COCO-bil | 780 M | 37.50% | 0.04 |
B. 3 Case Study
Fig. 7과 Fig. 8은 VisCPM-Chat의 광범위한 글로벌 지식 습득 능력을 생생하게 보여준다. Fig. 7의 두 가지 사례 연구에서 볼 수 있듯이, VisCPM-Chat은 초현실주의 스타일로 각색된 모나리자 그림을 식별하고, 얼룩진 뉴욕시 지도를 인식하며, 나아가 그것의 실제 의미를 해석할 수 있다. Fig. 8에서 예시된 바와 같이, VisCPM-Chat은 중국어-영어 멀티모달 대화에 대한 균형 잡힌 능력과 강력한 텍스트 인식 기술을 보여준다. VisCPM-Chat은 다양한 주제에 대해 영어로 유창한 멀티모달 대화를 나눌 수 있으며, 시각 입력으로부터 "Starbucks", "Avengers: Endgame"이라는 단어와 개봉일인 "April 26th"를 효과적으로 식별할 수 있다.
C Details of Baselines
기존의 중국어-영어 이중 언어 멀티모달 챗 모델에 대한 세부 정보는 Table 7에 요약되어 있으며 다음과 같이 소개된다:
- mPLUG-Owl (Ye et al., 2023): mPLUG-Owl은 vision encoder, vision abstractor module, 그리고 BLOOMZ (Muennighoff et al., 2023)를 language model backbone으로 구성한다. 이 모델은 LAION-400M, COYO, CC3M, MSCOCO 데이터셋으로 학습되었다.
Table 11: IGLUE 벤치마크에서 MpM의 성능. MpM을 mUNITER, xUNITER (Liu et al., 2021), (Zhou et al., 2021), (Ni et al., 2021)와 비교한다.
| Model | xNLI | xGQA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ARB | SPA | FRA | RUS | BEN | DEU | IND | KOR | POR | RUS | CMN | |
| mUNITER | 46.7 | 57.0 | 59.4 | 51.7 | 3.1 | 24.0 | 9.4 | 4.2 | 13.7 | 8.5 | 7.0 |
| xUNITER | 52.0 | 58.9 | 63.3 | 59.7 | 10.8 | 34.8 | 33.7 | 12.1 | 22.1 | 18.8 | 19.6 |
| 56.2 | 57.5 | 69.5 | 64.9 | 20.0 | 42.9 | 28.7 | 21.4 | 30.4 | 31.0 | 31.2 | |
| 55.2 | 58.9 | 56.4 | 62.5 | 18.6 | 33.4 | 32.5 | 25.1 | 31.4 | 27.5 | 28.7 | |
| MPM | 55.8 | 75.9 | 78.1 | 75.0 | 6.6 | 51.0 | 37.1 | 36.9 | 49.8 | 47.9 | 46.1 |
- VisualGLM (Du et al., 2022): VisualGLM은 Q-Former를 image encoder로, ChatGLM-6B (Du et al., 2022)를 language model backbone으로 사용한다. VisualGLM-6B의 사전학습에는 3천만 개의 고품질 중국어 이미지-텍스트 쌍과 3억 개의 필터링된 영어 이미지-텍스트 쌍이 포함된다. fine-tuning 단계에서는 VisualGLM이 long VQA 데이터로 학습된다.
- Ziya-Visual (Wang et al., 2022a): Ziya-Visual은 Q-Former (Li et al., 2023a)를 image encoder로, Ziya-LLaMA-13B-v1을 language model backbone으로 활용한다. 이들은 2천만 개의 중국어 이미지-텍스트 쌍을 사용하는데, 이는 오픈 소스 데이터에서 고품질 데이터를 정제하고, 영어 데이터셋을 번역하며, BLIP (Li et al., 2022) 및 Grounded SAM (Kirillov et al., 2023; Liu et al., 2023c)을 사용하여 캡션에서 coarse-grained 정보를 추출하여 구축되었다.
- Qwen-VL-Chat (Bai et al., 2023): Qwen-VL-Chat은 Openclip의 bigG (Ilharco et al., 2021)로 초기화된 1.9B 파라미터의 대형 ViT (Dosovitskiy et al., 2020)를 image encoder로, Qwen-7B를 language model backbone으로 활용한다. image encoder와 language model은 positional encoding이 추가된 1-layer cross-attention module로 연결된다. Qwen-VL-Chat은 p
기존의 중국어-영어 이중 언어 text-to-image 모델에 대한 세부 정보는 Table 8에 요약되어 있으며 다음과 같이 소개된다:
- AltDiffusion (Chen et al., 2023): AltDiffusion은 Stable Diffusion과 이중 언어 vision-language encoder인 AltClip (Chen et al., 2023)을 기반으로 하는 중국어-영어 이중 언어 text-to-image 모델이다. 학습 데이터는 Laion (Schuhmann et al., 2021)에서 수집되었다.
- TaiyiDiffusion (Wang et al., 2022a): TaiyiDiffusion은 중국어 text encoder를 Stable Diffusion에 적용한 중국어 text-to-image 모델이다. 학습 중 visual 부분은 frozen된다. 학습 데이터셋에는 2천만 개의 필터링된 중국어 이미지-텍스트 쌍이 포함된다.
D Details of VisCPM-Chat
D. 1 Multimodal Pretraining
시각 feature 정렬 사전학습 단계에서는 CC3M (Sharma et al., 2018), CC12M (Changpinyo et al., 2021), COCO (Lin et al., 2014), Visual Genome (Krishna et al., 2017), Laion-COCO (Christoph et al., 2022)를 포함한 이미지-텍스트 쌍 데이터셋의 혼합으로 visual encoder를 학습시킨다. VISCPM-Chat은 180K 스텝, **VISCPM-Chat+**는 480K 스텝 동안 학습을 진행했으며, 배치 크기는 768, 학습률은 로 설정했다. VISCPM-Chat과 **VISCPM-Chat+**의 사전학습에 사용된 각 데이터셋의 분포는 Table 10에 제시되어 있다. 이 단계에서는 visual module의 파라미터만 최적화된다.
D. 2 Instruction Tuning
Instruction tuning 단계에서 최적화 과정은 visual module과 LLM을 포함한다. 우리는 VISCPM-Chat을 LLaVA-Instruct-150K, UniMM-Chat, 그리고 M³IT의 혼합 데이터셋으로 학습시켰으며, 이 중 LLaVA-Instruct-150K와 UniMM-Chat은 중국어-영어 이중 언어 버전이다. Instruction tuning은 80K 스텝 동안 batch size 64로 진행되었다. VISCPM-Chat+의 학습 설정은 이 단계에서 VISCPM-Chat과 동일하다. 추론(inference) 단계에서 VisCPM-Chat은 beam size 3의 beam search decoding을 사용한다.
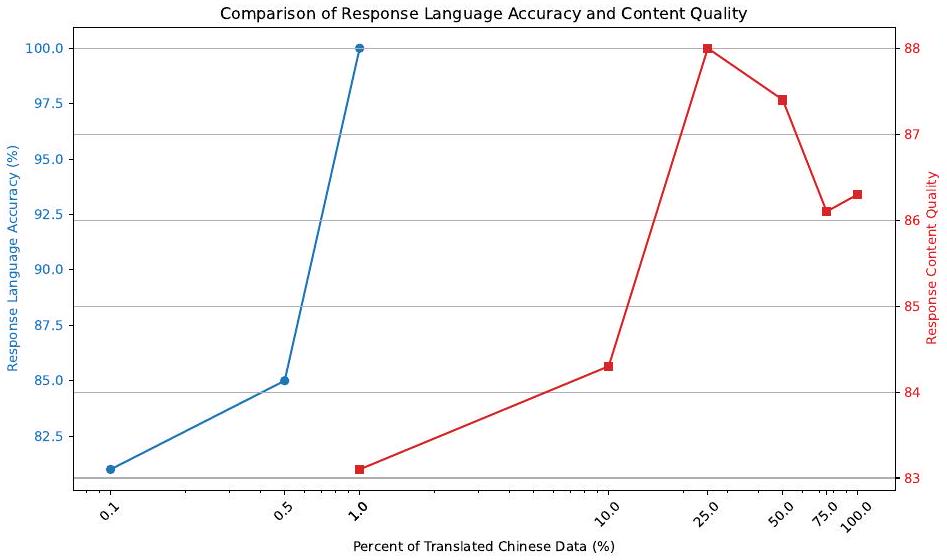
Figure 5: Instruction tuning 시 번역된 중국어 데이터의 비율을 다르게 사용했을 때의 응답 언어 정확도 및 내용 품질 변화 추이.
D. 3 Evaluation Benchmark
LLaVA Test Set (Liu et al., 2023a)
LLaVA Test Set은 90개의 인스턴스로 구성되며, 각 인스턴스에는 이미지, 질문, 답변이 포함되어 있어 대화, 상세 설명, 복합적인 추론 등 모델의 성능을 종합적으로 평가한다. LLaVA (Liu et al., 2023a)에 따라, 우리는 GPT-4를 사용하여 모델이 생성한 답변과 참조 답변을 1-10점 범위로 평가한다. 각 인스턴스의 평균 점수는 1-100점 범위로 정규화된다.
UniMM-Bench (Yu et al., 2023a)
UniMM-Bench는 400개의 테스트 인스턴스로 구성되며, 이는 OKVQA (Marino et al., 2019), AOKVQA (Schwenk et al., 2022), GQA (Hudson & Manning, 2019), VQAv2 (Antol et al., 2015) 등 4개의 일반적으로 사용되는 VQA 벤치마크에서 균일하게 샘플링되었으며, 이들의 어노테이션은 세심한 검토를 거쳤다.
기존의 visual question answering 평가에서는 모델이 생성한 답변이 참조 답변과 정확히 일치하는지 여부를 계산하는 방식으로 metric이 산출되었다. 그러나 LLM이 일반적으로 완전한 문장으로 질문에 답하는 경향이 있음을 고려하여, UniMM-Bench는 추론, 상식, grounding, 세계 지식 (Schwenk et al., 2022) 등 visual question-answering 맥락에서 멀티모달 챗 모델의 능력을 종합적으로 평가하도록 구축되었다. GPT-4를 평가에 사용하는 비용을 고려하여, 400개의 테스트 인스턴스는 신뢰할 수 있는 VQA 벤치마크에서 샘플링되었다.
D. 4 The Trend of Using Different Number of Chinese Translated Data
instruction tuning 과정에서 준-zero-shot transfer 임계값을 넘어서는, 모델이 목표 언어로 응답하는 능력에 중국어 데이터 양의 변화가 미치는 영향을 조사하기 위해, 우리는 번역된 중국어 데이터의 비율을 체계적으로 변화시켰다. Figure 5에 나타난 우리의 분석은 instruction tuning 동안 사용된 중국어 데이터 비율에 따른 응답 언어 정확도와 내용 품질의 경향을 명확히 보여준다.
놀랍게도, 번역된 중국어 데이터의 단 0.1%만 도입해도 응답 언어 정확도에서 80% 이상의 정확도를 달성하기에 충분하며, 이는 모델이 최소한의 언어별 데이터 입력에도 높은 민감도를 보임을 의미한다. 이 비율을 1%로 높이면 모든 응답이 중국어로 생성되는 결과를 가져온다.
내용 품질에 관해서는, 번역된 중국어 데이터의 25%에서 50% 범위가 최적의 균형을 이루어 고품질의 내용 응답을 생성한다는 것을 우리의 연구 결과는 시사한다. 응답 내용 품질을 극대화하기 위한 번역된 중국어 데이터의 보다 정확한 최적 비율을 결정하는 탐구는 향후 연구로 남겨둔다.
D. 5 Additional Results on IGLUE
우리는 MPM의 다국어 이미지 이해 능력을 평가하기 위해 IGLUE의 두 가지 벤치마크인 **xVNLI (Bugliarello et al., 2022)**와 **xGQA (Pfeiffer et al., 2022)**를 사용한다. 우리는 LLaMA를 backbone language model로 사용하여 오직 영어 이미지-텍스트 쌍으로만 사전학습된 모델을 선택하고, IGLUE의 영어 학습 데이터셋으로 fine-tuning한 다음, IGLUE의 공식 설정에 따라 zero-shot 평가를 수행한다.
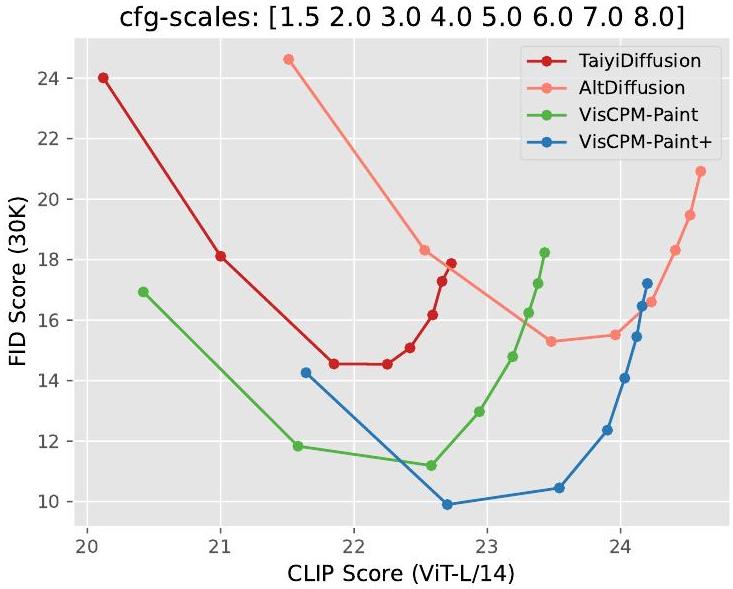
Figure 6: 다양한 classifier guidance scale에 따른 FID 대 CLIP score 곡선.
Table 11에서 볼 수 있듯이, MPM의 성능은 baseline 모델 대비 현저한 향상을 보인다. 특히, 중국어-영어 이중 언어 LLM인 CPM-Bee를 backbone language model로 사용했을 때, MPM은 CMN (중국어 표준어)에 대해 xGQA에서 56.05점을 달성한다. 위 결과를 바탕으로, 스페인어, 프랑스어, 러시아어, 독일어와 같이 다국어 LLM이 숙련도를 보이는 언어의 경우, 다국어 능력이 대상 언어에서 강력한 멀티모달 능력으로 효과적으로 일반화될 수 있음을 확인할 수 있다.
E Details of Viscpm-Paint
E. 1 Training and Sampling
VISCPM-Paint는 Stable Diffusion으로 초기화된 UNet과 이중 언어 LLM인 CPM-Bee (Zhang et al., 2021)로 구성된다. 우리는 VISCPM-Paint를 영어 이미지-텍스트 쌍 데이터셋인 Laion-2B (Schuhmann et al., 2022)에서 300k 스텝 동안 배치 크기 4096으로 사전학습한다. 이 300k 스텝은 256x256 해상도에서의 200k 스텝 학습과 512x512 해상도에서의 100k 스텝 학습으로 이루어진다. 우리는 UNet의 cross-attention layer와 LLM과 UNet 사이의 linear transblock만 최적화한다. Linear transblock은 linear layer와 layer-norm layer로 구성되며, 여기서 linear layer는 LLM의 hidden state 차원을 UNet의 차원으로 변환한다.
Laion-2B에서의 사전학습 후, 우리는 **VISCPM-Paint+**를 2천만 개의 필터링된 원어 중국어 이미지-텍스트 쌍과 Laion-COCO (Christoph et al., 2022)에 있는 1억 3천 6백만 개의 번역된 이미지-텍스트 쌍으로 계속 학습시킨다. 우리는 DDPM scheduler (Ho et al., 2020)를 사용하여 50 스텝으로 이미지를 생성한다. 각 prompt에 대해 우리는 세 가지 모델을 실행하여 네 개의 이미지를 생성하고, Chinese-CLIP (Yang et al., 2022)으로 평가된 가장 높은 CLIP 점수를 가진 이미지를 선택한다.
E. 2 Trade Off of Fidelity and Alignment
충실도(fidelity)와 정렬(alignment) 간의 trade-off를 시각화하기 위해, Figure 6은 다양한 classifier guidance scale에서 FID와 CLIP score의 곡선을 보여준다. 결과는 VISCPM-Paint와 **VISCPM-Paint+**가 이미지 품질과 의미론적 정렬 간의 균형 측면에서 전반적으로 우수한 성능을 제공함을 나타낸다. AltDiffusion의 CLIP score가 VISCPM-Paint 및 VISCPM-Paint+보다 약간 우수하지만, AltDiffusion의 FID는 현저히 낮다. 생성된 이미지의 **차선책 품질(sub-optimal quality)**은 아래의 인간 평가에서 보여지듯이 실제 사용에 영향을 미칠 것이다.
E. 3 Human Evaluation
중국어 텍스트-이미지 생성 모델의 성능을 더 잘 이해하기 위해, 우리는 Chinese Drawbench라는 중국어 prompt 종합 세트를 구축했다. Chinese Drawbench는 174개의 prompt로 구성되며, Relation, Compositional, Attribute, Counterintuitive, Rare Word, Count, Long Input, Chinese Culture의 8가지 카테고리를 포함한다. 각 카테고리에 대한 설명과 예시는 Table 9에 제시되어 있다. Chinese Drawbench를 구축하는 동안, 우리는 7명의 annotator에게 주어진 카테고리에 따라 각자 25개의 prompt를 생성하도록 요청했다. prompt의 다양성을 확보하기 위해, 우리는 동물, 식물, 음식, 우주 등 9가지 일반적인 클래스에서 20개의 prompt를 제한하고, 나머지 5개의 prompt는 제한 없이 생성하도록 했다. 이 과정을 거친 후, 우리는 prompt들을 다시 확인하고 미세하게 다듬었다.
우리는 5명의 독립적인 인간 평가자들을 초청하여 VISCPM-Paint, TaiyiDiffusion (Wang et al., 2022a), AltDiffusion의 Chinese Drawbench 성능을 평가하도록 했다. 각 인스턴스에 대해, 무작위로 섞인 세 장의 이미지와 입력 prompt가 인간 평가자들에게 제시되었다. 우리는 평가자들에게 **세 가지 측면(Overall, Alignment, Fidelity)**에서 세 이미지 중 가장 좋은 것을 선택하도록 요청했다. Alignment는 생성된 이미지와 입력 prompt 간의 일관성을 측정한다. Fidelity는 이미지의 선명도, 미적 매력, 객체 사실성을 측정한다. Overall은 생성된 이미지의 종합적인 품질을 측정한다. Figure 10은 Chinese Drawbench의 각 카테고리에 대한 상세한 결과를 제공한다.
F Detail of Ablation Study
우리는 ablation study에서 상세한 실험 구성을 소개한다.
Table 5a에 제시된 image-to-text task의 경우, native Chinese 데이터셋은 Wukong (Gu et al., 2022) 및 Zero (Xie et al., 2022)에서 필터링된 2천만 개의 이미지-텍스트 쌍으로 구성된다. Table 5a의 "Pretrain" 열에서 "Native Chinese"는 Wukong (Gu et al., 2022) 및 Zero (Xie et al., 2022)에서 필터링된 2천만 개의 native Chinese 이미지-텍스트 쌍을 의미한다. "English"는 VISCPM-Chat에서 사용된 데이터셋, 즉 COCO, Visual Genome, CC3M, CC12M, 그리고 Laion-COCO에 해당한다. "Translated Chinese"는 Laion-COCO의 캡션이 영어에서 중국어로 번역된 3억 9천만 개의 중국어 이미지-텍스트 쌍으로 구성된다.
instruction tuning, 즉 **supervised fine-tuning (SFT)**에서는 ablation study의 계산 시간을 줄이기 위해 LLaVA와 그 번역된 중국어 버전만을 활용한다. 구체적으로, Table 5a의 "SFT" 열에 있는 "Chinese"는 번역된 중국어 LLaVA instruction tuning 데이터셋을 의미한다. "Bilingual"은 영어와 번역된 중국어 LLaVA의 혼합 버전을 의미한다.
Table 5b에 제시된 text-to-image task의 경우, "English"는 Laion-2B를 의미한다. 다른 설정은 위에서 소개된 image-to-text task와 동일하다.
G Detail of CLIP Score
우리는 중국어 이미지-텍스트 쌍에서 CLIP score를 계산하기 위해 **Chinese-CLIP (Yang et al., 2022)**을 사용한다. Chinese CLIP 모델은 데이터 필터링 및 텍스트 인코딩을 위해 여러 중국어 text-to-image 모델에서 사용되어 왔다 (Wang et al., 2022a; Liu et al., 2023b; Yang et al., 2023). 우리는 중국어 text-to-image 모델 학습 시 **Taiyidiffusion의 데이터 볼륨 및 필터링 기준(CLIP score 포함)**을 참고하였다. 우리는 Wukong 데이터셋의 캡션을 수동으로 확인하였다. 그 결과, Wukong의 텍스트 콘텐츠 전반적인 품질이 만족스럽지 않음을 발견하였다. 낮은 CLIP score에 대한 몇 가지 발견 사항은 다음과 같다:
- 손상된 이미지 (Broken Images): 일부 이미지 URL이 손상되었거나, 다운로드를 위해 동일한 기본 이미지로 리디렉션된다.
- 무관한 캡션 (Unrelated captions): 일부 캡션 내용은 이미지 내용과 전혀 관련이 없다.
- 불완전한 문장 (Incomplete sentences): 일부 캡션은 잘려 있거나 구두점이 누락되어 있다.

Figure 7: VISCPM-Chat의 중국어 멀티모달 대화 사례. VISCPM-Chat은 초현실주의 스타일로 각색되었지만 모나리자와 같은 예술 작품과 뉴욕시의 상세하고 얼룩진 지도를 인식할 수 있다.
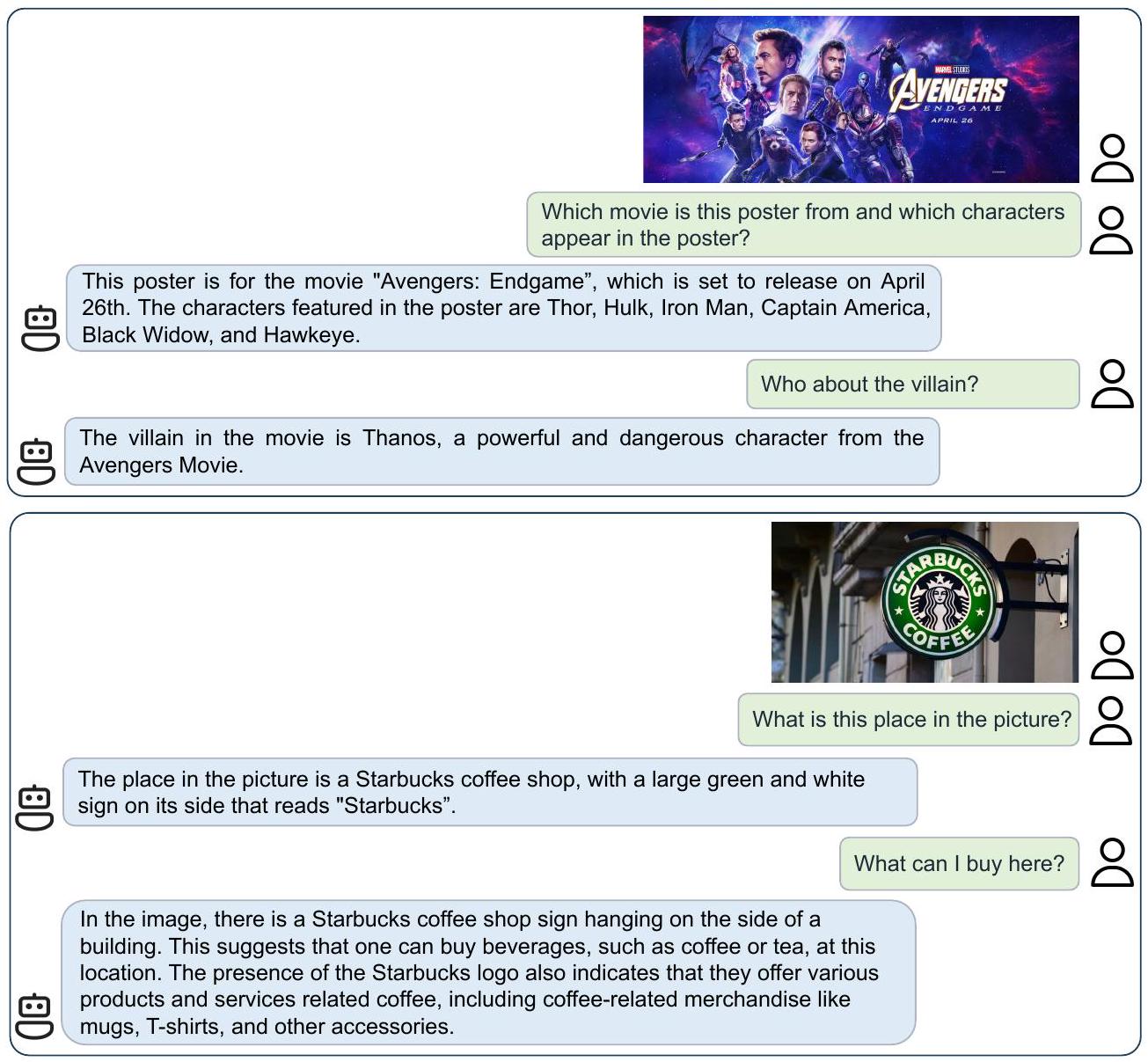
Figure 8: VisCPM-Chat의 영어 멀티모달 대화 사례. VisCPM-Chat은 영어로 다양한 주제에 대해 유창한 멀티모달 대화를 수행할 수 있으며, 이미지에서 "Starbucks", "Avengers: Endgame"이라는 단어와 개봉일인 "April 26th"를 인식할 수 있다.

Figure 9: VISCPM-Paint로 생성된 이미지.
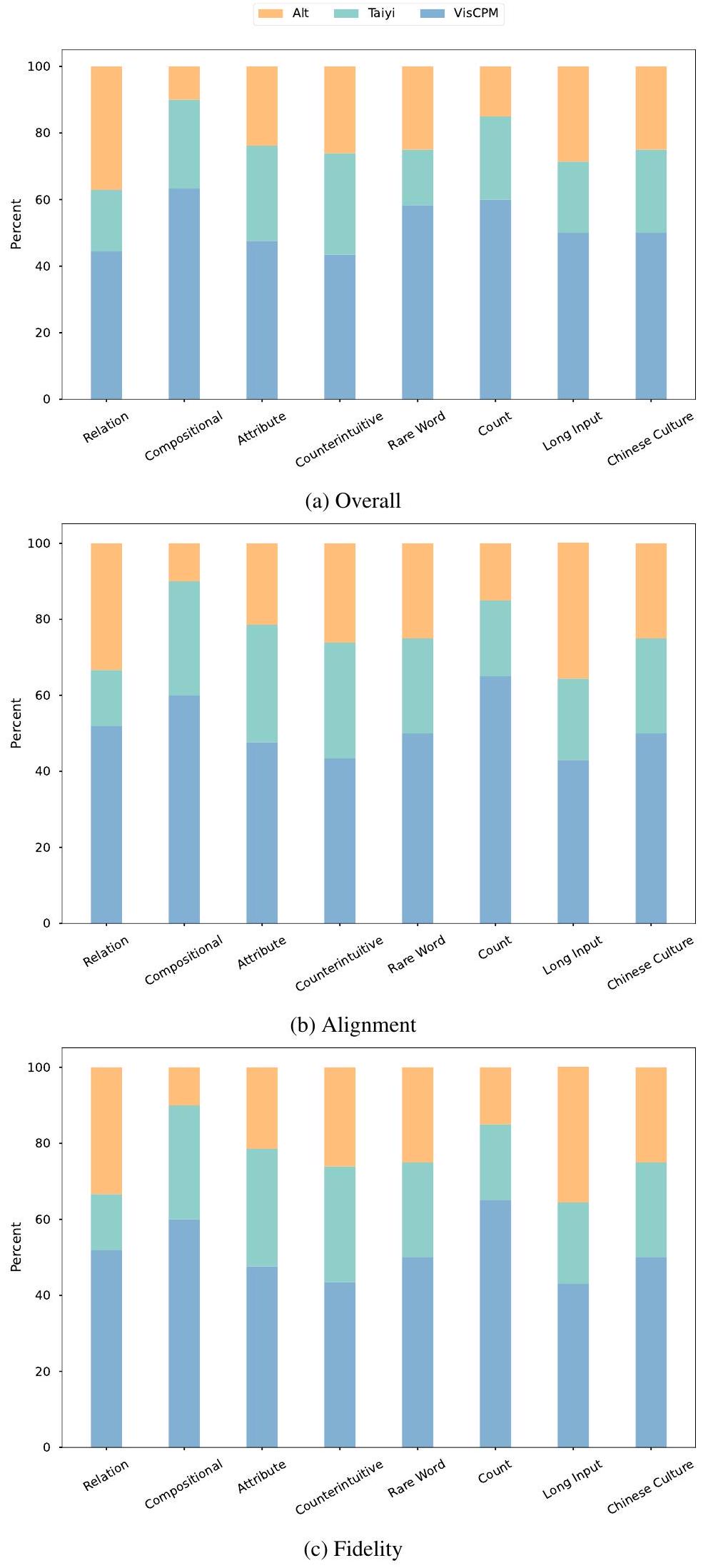
Figure 10: 다양한 측면에서 Chinese Drawbench에 대한 인간 선호도.