Kosmos-2: Grounding Multimodal Large Language Models to the World
Kosmos-2는 객체 설명(예: bounding boxes)을 인식하고 텍스트를 시각 세계에 grounding하는 새로운 기능을 갖춘 Multimodal Large Language Model (MLLM)입니다. 이 모델은 참조 표현을 마크다운의 링크 형식, 즉 "[text span] (bounding boxes)"로 나타내며, 대규모의 grounded image-text pair 데이터셋(GRIT)을 사용하여 학습됩니다. Kosmos-2는 기존 MLLM의 기능(예: 일반적인 modality 인식, 지시 따르기, in-context learning)에 더해 grounding 기능을 다양한 다운스트림 애플리케이션에 통합합니다. 이를 통해 multimodal grounding, multimodal referring 등 여러 작업에서 뛰어난 성능을 보이며, Embodiment AI 발전의 토대를 마련합니다. 논문 제목: Kosmos-2: Grounding Multimodal Large Language Models to the World
논문 요약: Kosmos-2: Grounding Multimodal Large Language Models to the World
- 논문 링크: https://arxiv.org/abs/2306.14824
- 저자: Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei (Microsoft Research)
- 발표 시기: 2023년, arXiv
- 주요 키워드: MLLM, Multimodal, Grounding, Embodiment AI
1. 연구 배경 및 문제 정의
- 문제 정의:
기존 Multimodal Large Language Model (MLLM)은 텍스트, 이미지 등 일반적인 모달리티를 인지하고 자유 형식 텍스트 응답을 생성할 수 있었으나, 시각 세계에 텍스트를 'grounding'하는 능력이 부족했습니다. 이는 사용자가 이미지 내 특정 객체나 영역을 직접 가리키거나, 모델이 시각적 응답(예: 바운딩 박스)을 생성하는 데 한계가 있었습니다. - 기존 접근 방식:
이전 MLLM은 주로 텍스트 기반의 응답만을 제공하여, 이미지 내 특정 영역을 직접 참조하거나 시각적 응답을 생성하는 데 어려움이 있었습니다. 이는 인간-AI 상호작용의 효율성을 저해하고, 공동 참조(coreference) 모호성을 해결하기 어려웠습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 객체 설명(바운딩 박스)을 인지하고 텍스트를 시각 세계에 grounding하는 새로운 MLLM인 Kosmos-2를 제안했습니다.
- 참조 표현을 "[text span] (bounding boxes)"와 같은 마크다운 링크 형식으로 표현하는 방식을 도입했습니다.
- 대규모 grounded image-text 쌍 데이터셋인 GRIT를 구축하여 모델 학습에 활용했습니다.
- 기존 MLLM의 기능(모달리티 인지, 지시 따르기, in-context learning)에 grounding 기능을 통합하여 다양한 다운스트림 애플리케이션에 적용 가능성을 제시했습니다.
- 제안 방법:
- 모델 구조: Kosmos-1을 기반으로 하는 Transformer 기반의 인과적 언어 모델이며, next-token prediction 방식으로 학습됩니다.
- Grounding 능력 구현:
- GRIT 데이터셋 구축: COYO-700M 및 LAION-2B의 이미지-텍스트 쌍을 기반으로 대규모 Grounded Image-Text 쌍 데이터셋인 GRIT를 구축했습니다. 이 데이터셋은 캡션 내의 명사 덩어리 및 지칭 표현을 해당 이미지 영역(바운딩 박스)에 연결하는 파이프라인을 통해 생성됩니다.
- 명사 덩어리-바운딩 박스 쌍 생성: spaCy로 캡션에서 명사 덩어리를 추출하고, 사전학습된 detector(예: GLIP)로 이미지 영역과 연결합니다.
- 지칭 표현-바운딩 박스 쌍 생성: spaCy의 의존성 관계를 활용하여 명사 덩어리를 지칭 표현으로 확장하고, 명사 덩어리의 바운딩 박스를 확장된 지칭 표현에 할당합니다.
- 입력 표현: 바운딩 박스의 연속적인 좌표를 이산적인 위치 토큰(location token) 시퀀스로 변환하고, 이를 해당 텍스트 스팬과 마크다운의 "하이퍼링크" 형식(
"<p> text span </p><box><loc_1><loc_2></box>")으로 연결하여 모델에 입력합니다.
- GRIT 데이터셋 구축: COYO-700M 및 LAION-2B의 이미지-텍스트 쌍을 기반으로 대규모 Grounded Image-Text 쌍 데이터셋인 GRIT를 구축했습니다. 이 데이터셋은 캡션 내의 명사 덩어리 및 지칭 표현을 해당 이미지 영역(바운딩 박스)에 연결하는 파이프라인을 통해 생성됩니다.
- 학습: 새로 구축된 grounded image-text 쌍과 기존의 단일 모달 텍스트, 이미지-캡션 쌍, 인터리브드 멀티모달 데이터를 함께 사용하여 학습합니다. 학습 손실은 텍스트 토큰 및 위치 토큰에만 적용됩니다.
- Instruction Tuning: 학습 완료 후, LLaVA-Instruct, Unnatural Instructions, FLANv2 등의 데이터셋과 GRIT 기반의 grounded instruction 데이터를 활용하여 모델을 튜닝하여 인간의 지시에 더 잘 부합하도록 합니다.
3. 실험 결과
- 데이터셋:
- 학습 데이터셋: 자체 구축한 대규모 Grounded Image-Text 쌍 데이터셋인 GRIT (약 9,100만 이미지, 1억 1,500만 텍스트 스팬, 1억 3,700만 바운딩 박스)와 기존의 단일 모달 텍스트, 이미지-캡션 쌍, 인터리브드 멀티모달 데이터를 사용했습니다.
- 평가 데이터셋:
- 멀티모달 Grounding: Flickr30k Entities (Phrase Grounding), RefCOCO, RefCOCO+, RefCOCOg (Referring Expression Comprehension).
- 멀티모달 Referring: RefCOCOg (Referring Expression Generation).
- 인지-언어 태스크: Flickr30k Karpathy split (Image Captioning), VQAv2 test-dev (Visual Question Answering).
- 언어 태스크: StoryCloze, HellaSwag, Winograd, Winogrande, PIQA, BoolQ, CB, COPA.
- 학습 환경: 256개의 V100 GPU에서 약 하루 동안 학습되었습니다.
- 주요 결과:
- 멀티모달 Grounding:
- Phrase Grounding (Flickr30k Entities): Kosmos-2는 제로샷(zero-shot) 설정에서 기존의 detector 기반 모델(GRILL)을 크게 능가하며, 일부 파인튜닝된 모델보다도 우수한 성능을 보였습니다 (VisualBert 대비 R@1 7.4% 향상). R@1, R@5, R@10 지표에서 유사한 결과를 보여, 고품질의 위치를 생성할 수 있음을 입증했습니다.
- Referring Expression Comprehension (RefCOCO, RefCOCO+, RefCOCOg): RefCOCOg 벤치마크에서 이전 제로샷 모델들을 크게 능가하는 유망한 제로샷 성능을 달성했습니다. RefCOCO 및 RefCOCO+에서는 파인튜닝된 모델 대비 약간 낮은 성능을 보였으나, 이는 데이터셋의 특성(짧은 표현) 때문으로 분석됩니다.
- 멀티모달 Referring:
- Referring Expression Generation (RefCOCOg): 제로샷 설정에서 파인튜닝된 SLR 모델보다 1.1 CIDEr 점수 높은 인상적인 성능을 달성했습니다. Few-shot 설정에서는 추가적인 성능 향상을 보여 in-context learning 능력을 입증했습니다.
- 인지-언어 태스크 (Image Captioning, VQA): Kosmos-1과 유사한 전반적인 성능을 유지했습니다. Flickr30k에서는 약간의 향상을, VQAv2에서는 미미한 감소를 보였으나, 새로운 기능 도입에도 불구하고 경쟁력 있는 성능을 유지했습니다.
- 언어 태스크: StoryCloze, HellaSwag 등 8가지 언어 태스크에서 Kosmos-1과 전반적으로 유사한 성능을 유지하며, 새로운 능력 획득과 언어 능력 간의 균형을 보여주었습니다.
- 멀티모달 Grounding:
4. 개인적인 생각 및 응용 가능성
- 장점:
- 텍스트와 시각 정보를 단순히 연결하는 것을 넘어, 텍스트 스팬을 이미지 내 특정 영역(바운딩 박스)에 직접 'grounding'하는 새로운 능력을 성공적으로 구현한 점이 가장 인상 깊습니다. 이는 MLLM의 활용 범위를 크게 확장할 수 있는 핵심적인 발전입니다.
- 바운딩 박스 좌표를 위치 토큰으로 이산화하고 이를 텍스트와 함께 "하이퍼링크" 형식으로 통합한 아이디어가 매우 독창적이고 효과적입니다. 이를 통해 모델이 시각적 정보를 언어 모델의 프레임워크 내에서 자연스럽게 처리할 수 있게 되었습니다.
- 대규모 GRIT 데이터셋을 자동화된 파이프라인으로 구축하여 모델 학습에 활용한 점은 이러한 grounding 능력 구현의 기반이 됩니다.
- 새로운 grounding 및 referring 능력 추가에도 불구하고, 기존의 언어 및 인지-언어 태스크에서 경쟁력 있는 성능을 유지했다는 점은 모델의 균형 잡힌 발전을 보여줍니다.
- 단점/한계:
- RefCOCO 및 RefCOCO+ 데이터셋에서 기존 파인튜닝 모델 대비 약간 낮은 성능을 보인 점은 한계로 지적될 수 있습니다. 이는 짧은 지칭 표현에 대한 이해도 개선이 필요함을 시사합니다.
- 바운딩 박스 좌표를 이산적인 토큰으로 변환하는 과정에서 미세한 공간 정보 손실이 발생할 가능성이 있습니다.
- 모델의 크기(약 1.6B 파라미터)와 학습에 필요한 컴퓨팅 자원(256 V100 GPU, 1일)은 여전히 상당하여, 일반적인 환경에서의 활용에는 제약이 있을 수 있습니다.
- 응용 가능성:
- Embodiment AI: 로봇이 주변 환경을 인식하고 언어 지시에 따라 특정 객체를 조작하거나 상호작용하는 데 필수적인 기반 기술이 될 수 있습니다.
- 고급 시각 질의응답 (Grounded VQA): 사용자가 이미지의 특정 영역을 가리키며 질문하거나, 모델이 답변과 함께 관련 이미지 영역을 바운딩 박스로 제시하여 더욱 정확하고 명확한 소통이 가능해집니다.
- 정밀한 이미지 캡셔닝: 생성된 캡션 내의 명사구를 해당 이미지 영역에 연결하여, 캡션의 정확성과 정보량을 극대화할 수 있습니다.
- 인간-AI 상호작용 개선: 사용자가 텍스트 설명 대신 이미지 내 객체를 직접 가리키는 방식으로 AI와 상호작용할 수 있게 되어, 더욱 직관적이고 효율적인 인터페이스를 제공합니다.
- 시각적 검색 및 탐색: 특정 시각적 특징을 가진 객체를 이미지 내에서 찾아내거나, 복잡한 시각적 쿼리에 대한 정확한 응답을 제공하는 데 활용될 수 있습니다.
5. 추가 참고 자료
Peng, Zhiliang, et al. "Kosmos-2: Grounding multimodal large language models to the world." arXiv preprint arXiv:2306.14824 (2023).
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng*, Wenhui Wang, Li Dong*, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei Microsoft Research<br>https://aka.ms/GeneralAI
Abstract
우리는 Kosmos-2를 소개한다. Kosmos-2는 **Multimodal Large Language Model (MLLM)**로서, 객체 설명(예: bounding box)을 인지하고 텍스트를 시각 세계에 grounding하는 새로운 능력을 가능하게 한다. 구체적으로, 우리는 참조 표현(refer expression)을 Markdown 링크 형식, 즉 "[text span] (bounding boxes)"로 표현한다. 여기서 객체 설명은 위치 토큰(location token)들의 시퀀스이다. 멀티모달 코퍼스와 함께, 우리는 **grounded image-text 쌍의 대규모 데이터(GRIT이라고 명명)**를 구축하여 모델을 학습시킨다. 기존 MLLM의 능력(예: 일반적인 modality 인지, 지시 따르기, in-context learning 수행) 외에도, Kosmos-2는 grounding 능력을 다운스트림 애플리케이션에 통합한다. 우리는 Kosmos-2를 다음과 같은 광범위한 task에서 평가한다: (i) Referring Expression Comprehension 및 Phrase Grounding과 같은 멀티모달 grounding, (ii) Referring Expression Generation과 같은 멀티모달 referring, (iii) Perception-Language task, (iv) 언어 이해 및 생성. 이 연구는 Embodiment AI 개발의 토대를 마련하고, 인공 일반 지능(artificial general intelligence)을 향한 핵심 단계인 언어, 멀티모달 지각, 행동, 세계 모델링의 큰 융합에 대한 통찰을 제공한다. 코드와 사전학습된 모델은 https://aka.ms/kosmos-2 에서 확인할 수 있다.
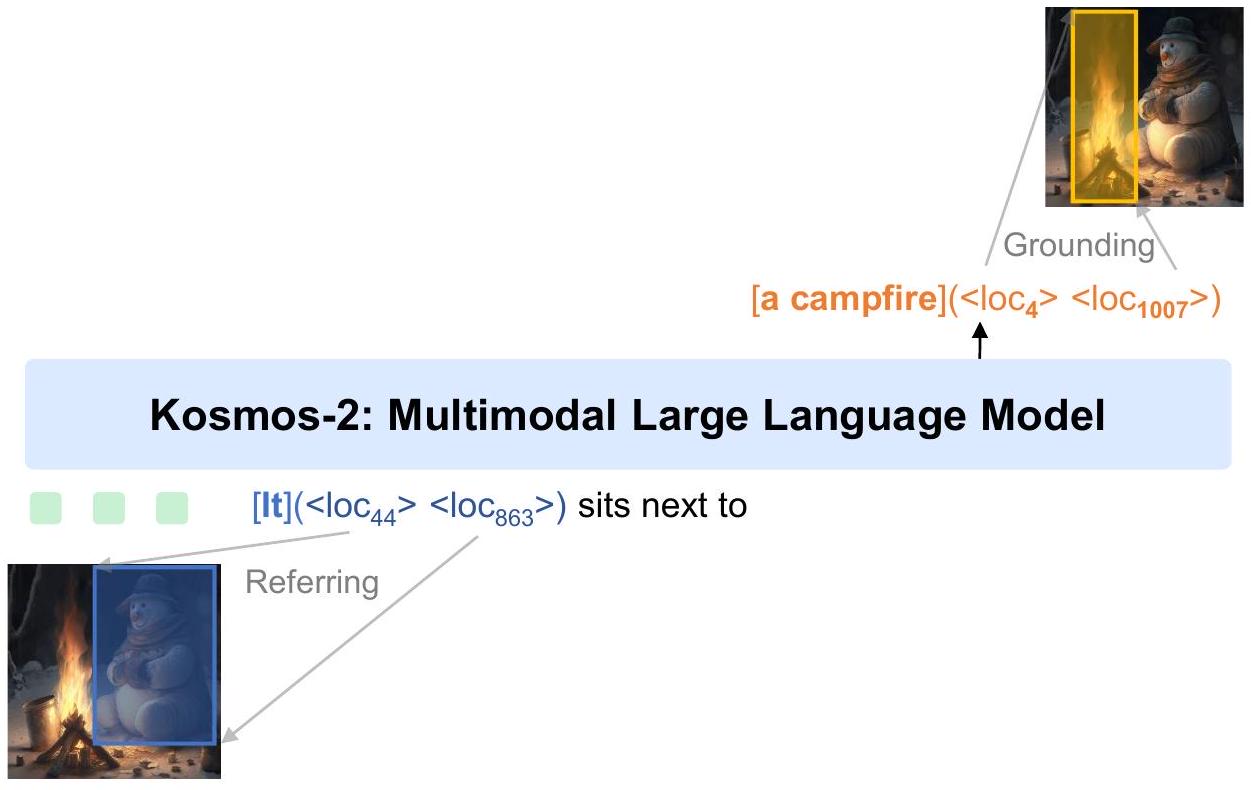
Figure 1: Kosmos-2는 멀티모달 grounding 및 referring의 새로운 능력을 갖춘 Multimodal Large Language Model이다. Kosmos-2는 멀티모달 입력을 이해하고, 지시를 따르며, 객체 설명(예: bounding box)을 인지하고, 언어를 시각 세계에 grounding할 수 있다.

Figure 2: Kosmos-2에서 생성된 예시들. 예시에는 (1) visual grounding, (2)-(3) grounded question answering, (4)-(6) bounding box를 통한 멀티모달 referring, (7) grounded image captioning이 포함된다.
1 Introduction
Multimodal Large Language Model (MLLM) [HSD 22, , Ope23]은 언어, 비전, vision-language task 등 광범위한 task에서 범용적인 인터페이스 역할을 성공적으로 수행해왔다. MLLM은 텍스트, 이미지, 오디오를 포함한 일반적인 modality를 인지하고, zero-shot 및 few-shot 설정에서 자유 형식의 텍스트로 응답을 생성할 수 있다.
본 연구에서는 멀티모달 대규모 언어 모델의 grounding 능력을 구현한다. Grounding 능력은 vision-language task에서 더욱 편리하고 효율적인 인간-AI 상호작용을 제공할 수 있다. 이는 사용자가 상세한 텍스트 설명을 입력하는 대신 이미지 내의 객체나 영역을 직접 가리킬 수 있도록 하며, 모델은 해당 이미지 영역을 공간적 위치와 함께 이해할 수 있다. 또한 grounding 능력은 모델이 시각적 응답(예: bounding box)을 생성할 수 있도록 하여, referring expression comprehension과 같은 더 많은 vision-language task를 지원할 수 있게 한다. 시각적 응답은 텍스트 전용 응답에 비해 더 정확하며, 공동 참조(coreference) 모호성을 해결한다. 또한, grounding 능력은 생성된 자유 형식 텍스트 응답 내의 명사구(noun phrase)와 참조 표현(referring expression)을 이미지 영역에 연결하여, 더욱 정확하고 정보가 풍부하며 포괄적인 답변을 제공할 수 있다.
우리는 Kosmos-1을 기반으로 구축된 grounding 능력을 갖춘 멀티모달 대규모 언어 모델인 Kosmos-2를 소개한다. Kosmos-2는 Transformer 기반의 causal language model이며, next-word prediction task를 사용하여 학습되었다. Grounding 능력을 구현하기 위해, 우리는 웹 규모의 grounded image-text 쌍 데이터셋을 구축하고, 이를 Kosmos-1의 멀티모달 코퍼스와 결합하여 모델을 학습시켰다. Grounded image-text 쌍은 LAION-2B [] 및 COYO-700M []의 이미지-텍스트 쌍 서브셋을 기반으로 구축되었다. 우리는 캡션 내의 텍스트 스팬(즉, 명사구 및 참조 표현)을 해당 이미지 내 객체 또는 영역의 공간적 위치(예: bounding box)에 추출하고 연결하는 파이프라인을 구축했다. Bounding box의 공간 좌표는 일련의 위치 토큰으로 변환되며, 이 토큰은 해당 텍스트 스팬 뒤에 추가된다. 이 데이터 형식은 이미지의 객체 또는 영역을 캡션에 연결하는 "하이퍼링크" 역할을 한다. 실험 결과는 Kosmos-2가 Kosmos-1에서 평가된 언어 및 vision-language task에서 경쟁력 있는 성능을 달성했을 뿐만 아니라, grounding task (phrase grounding 및 referring expression comprehension) 및 referring task (referring expression generation)에서도 인상적인 성능을 달성했음을 보여준다. Figure 2에서 보듯이, grounding 능력의 통합은 Kosmos-2가 grounded image captioning 및 grounded visual question answering과 같은 더 많은 다운스트림 task에 사용될 수 있도록 한다.
2 Construction of Web-Scale Grounded Image-Text Pairs (GRIT)
우리는 GrIT를 소개한다. GrIT는 COYO-700M [BPK22] 및 LAION-2B [SBV22]의 일부 이미지-텍스트 쌍을 기반으로 생성된 대규모 Grounded Image-Text 쌍 데이터셋이다. 우리는 캡션 내의 텍스트 스팬(즉, 명사구 및 지칭 표현)을 해당 이미지 영역에 추출하고 연결하는 파이프라인을 구축한다. 이 파이프라인은 주로 두 단계로 구성된다:
- 명사 덩어리-바운딩 박스(noun-chunk-bounding-box) 쌍 생성
- 지칭 표현-바운딩 박스(referring-expression-bounding-box) 쌍 생성
이러한 단계들은 아래에서 자세히 설명한다:
Step-1: 명사 덩어리-바운딩 박스 쌍 생성
주어진 이미지-텍스트 쌍에서, 우리는 먼저 캡션에서 명사 덩어리(noun chunk)를 추출하고, 사전학습된 detector를 사용하여 이를 이미지 영역과 연결한다. Figure 3에 나타난 바와 같이, 우리는 spaCy [HMVLB20]를 사용하여 캡션("a dog in a field of flowers")을 파싱하고 모든 명사 덩어리("a dog", "a field", "flowers")를 추출한다. "time", "love", "freedom"과 같이 이미지에서 인식하기 어려운 추상적인 명사구는 잠재적인 노이즈를 줄이기 위해 제거한다.
이후, 이미지와 캡션에서 추출된 명사 덩어리를 사전학습된 grounding model (예: GLIP [LZZ22])에 입력하여 관련 바운딩 박스를 얻는다. Non-maximum suppression 알고리즘을 적용하여 동일한 명사 덩어리에 대한 것이 아니더라도 다른 바운딩 박스와 높은 중첩을 보이는 바운딩 박스를 제거한다. 예측된 신뢰도 점수가 0.65보다 높은 명사 덩어리-바운딩 박스 쌍만 유지한다. 만약 유지되는 바운딩 박스가 없으면 해당 이미지-캡션 쌍은 폐기한다.
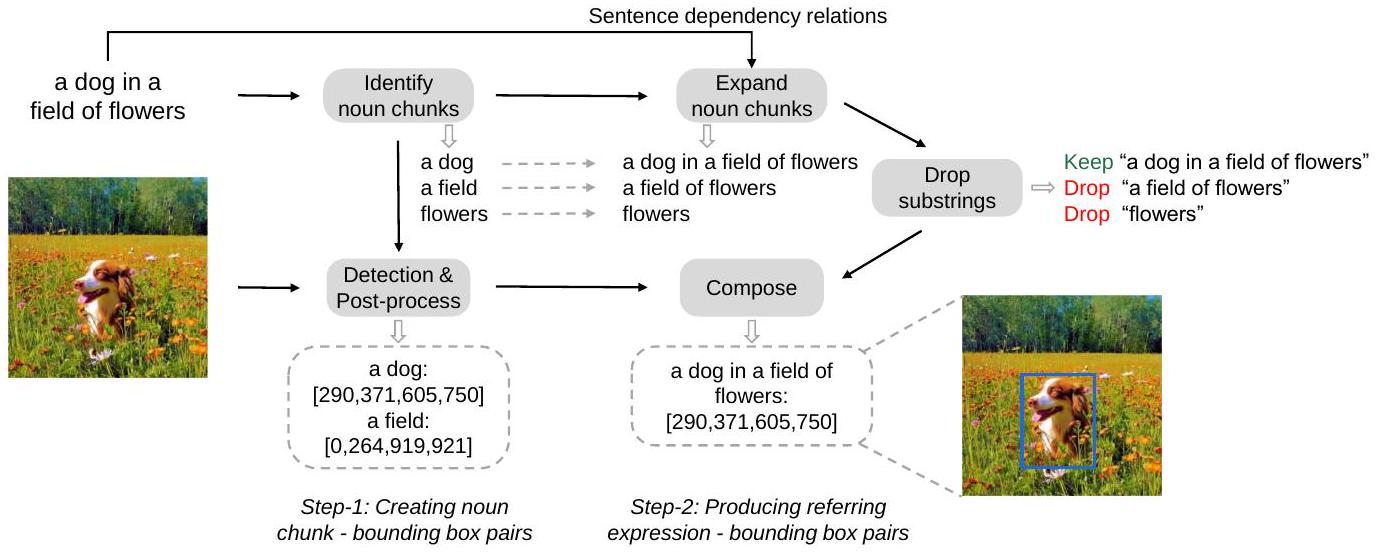
Figure 3: 웹 규모의 grounded image-text 쌍을 구축하는 파이프라인.
| Dataset | Images | Objects | Text Spans | Avg Expression Length |
|---|---|---|---|---|
| Flickr Entities [PWC 15] | 31,783 | 275,775 | 513,644 | - |
| RefCOCOg [ 15] | 26,711 | 54,822 | 85,474 | 8.43 |
| RefCOCO [YPY+ 16] | 19,994 | 50,000 | 142,209 | 3.61 |
| RefCOCO+ [YPY+ 16] | 19,992 | 49,856 | 141,564 | 3.53 |
| Visual Genome [KZG 16] | 108,077 | 4,102,818 | - | - |
| Grit (Ours) | 90,614,680 | 137,349,210 | 114,978,233 | 4.7 |
Table 1: 기존 visual grounding 데이터셋과 GRIT의 비교.
Step-2: 지칭 표현-바운딩 박스 쌍 생성
모델에 복잡한 언어적 설명을 grounding하는 능력을 부여하기 위해, 우리는 명사 덩어리를 지칭 표현(referring expression)으로 확장한다. 구체적으로, 우리는 spaCy를 사용하여 문장의 의존성 관계(dependency relations)를 얻는다. 그런 다음, 의존성 트리에서 자식 토큰을 재귀적으로 탐색하고 명사 덩어리와 자식 토큰을 연결하여 명사 덩어리를 지칭 표현으로 확장한다. 우리는 접속사(conjuncts)가 있는 명사 덩어리는 확장하지 않는다. 자식 토큰이 없는 명사 덩어리는 다음 프로세스를 위해 그대로 유지한다. Figure 3에 제시된 예시에서, 명사 덩어리 'a dog'는 "a dog in a field of flowers"로 확장될 수 있으며, 명사 덩어리 'a field'는 "a field of flowers"로 확장될 수 있다.
또한, 우리는 다른 표현에 포함되지 않는 지칭 표현 또는 명사 덩어리만 유지한다. Figure 3에서 보듯이, 우리는 지칭 표현 "a dog in a field of flowers"를 유지하고 "a field of flowers" (이는 "a dog in a field of flowers"에 포함되므로)와 'flowers'는 제거한다. 우리는 명사 덩어리('a dog')의 바운딩 박스를 해당 생성된 지칭 표현("a dog in a field of flowers")에 할당한다.
최종적으로, 우리는 약 9,100만 개의 이미지, 1억 1,500만 개의 텍스트 스팬, 그리고 1억 3,700만 개의 관련 바운딩 박스를 얻는다. Table 1에서 GrIT를 기존의 공개된 visual grounding 데이터셋과 비교하였다. GrIT의 데이터 샘플은 Appendix에 제시되어 있다.
3 Kosmos-2: A Grounded Multimodal Large Language Model
Kosmos-2는 Kosmos-1에 grounding 및 referring 능력을 통합한 grounded multimodal large language model이다. 이 모델은 사용자가 bounding box를 사용하여 선택한 이미지 영역을 입력으로 받아들일 수 있으며, 시각적 답변(즉, bounding box)을 제공하고, 텍스트 출력을 시각 세계에 grounding할 수 있다. Kosmos-2는 Kosmos-1과 동일한 모델 아키텍처와 학습 목표를 채택한다. 우리는 모델에 grounding 및 referring 능력을 부여하기 위해 grounded image-text pair를 학습 데이터에 추가한다.
grounded image-text pair 내의 **텍스트 스팬(예: 명사구 및 referring expression)**과 그에 해당하는 bounding box에 대해, 우리는 **bounding box의 연속적인 좌표를 일련의 위치 토큰(location token)으로 이산화(discretize)**하여 텍스트 토큰과 통합된 방식으로 인코딩한다. 그런 다음, 우리는 위치 토큰과 해당 텍스트 스팬을 "hyperlink" 데이터 형식으로 연결한다. 모델은 이미지 영역과 해당 위치 토큰 간의 매핑을 설정하고, 이미지 영역을 관련 텍스트 스팬과 연결하도록 학습된다.
3.1 Grounded Input Representations
주어진 grounded image-text 쌍에서 텍스트 스팬과 그에 연결된 바운딩 박스가 있을 때, 우리는 먼저 바운딩 박스의 연속적인 좌표를 이산적인 위치 토큰(discrete location tokens) 시퀀스로 변환한다 [CSL 21]. 너비 와 높이 를 가진 이미지의 경우, 너비와 높이 모두를 각각 개의 세그먼트로 균등하게 나눈다. 이렇게 개의 빈(bin)이 생성되며, 각 빈은 픽셀로 구성된다. 각 빈에 대해, 우리는 해당 빈 내의 좌표를 나타내기 위해 **위치 토큰(location token)**을 사용한다. 이미지 상의 바운딩 박스를 결정하기 위해 각 빈의 중심 픽셀 좌표를 사용한다. 총 개의 위치 토큰이 도입되며, 이 토큰들은 텍스트와 통합 모델링을 가능하게 하기 위해 단어 어휘(word vocabulary)에 추가된다.
바운딩 박스는 **좌상단 점 과 우하단 점 **을 사용하여 표현될 수 있다. 우리는 좌상단 및 우하단 모서리 점들을 각각 위치 토큰으로 이산화한다. 단일 바운딩 박스를 표현하기 위해 좌상단 위치 토큰 <loc_1>, 우하단 위치 토큰 <loc_2>, 그리고 특별한 경계 토큰 <box>와 </box>를 연결한다: "<box><loc_1><loc_2></box>".
만약 텍스트 스팬이 여러 바운딩 박스와 연결되어 있다면, 우리는 특별 토큰 <delim>을 사용하여 이 바운딩 박스들의 위치 토큰들을 연결한다:
"<box><loc_1^i><loc_2^i><delim>...<loc_1^j><loc_2^j></box>".
그런 다음 우리는 텍스트 스팬과 그에 연결된 위치 토큰들을 마크다운의 "하이퍼링크"와 유사한 형식으로 배열한다. 단일 바운딩 박스를 가진 텍스트 스팬의 경우, 결과 시퀀스는 "<p> text span </p><box><loc_1><loc_2></box>"가 된다. 여기서 <p>와 </p>는 텍스트 스팬의 시작과 끝을 나타내는 특별 토큰이다. 이 데이터 형식은 바운딩 박스 내의 이미지 영역이 텍스트 스팬과 연결되어 있음을 모델에게 알려준다.
Figure 1에 제시된 예시의 입력 표현은 다음과 같다:
<s> <image> Image Embedding </image> <grounding> <p> It </p><box><loc44><loc863></box>
seats next to <p> a campfire </p><box><loc 4><loc 1007></box></s>
여기서 <s>와 </s>는 시퀀스의 시작과 끝을 나타내며, <image>와 </image>는 인코딩된 이미지 임베딩의 시작과 끝을 나타낸다. <grounding>은 모델에게 텍스트 출력을 시각 세계에 grounding하도록 지시하는 특별 토큰이다. 우리는 입력 텍스트 토큰과 위치 토큰을 lookup table을 통해 임베딩으로 매핑한다. Kosmos-1을 따라, vision encoder와 resampler 모듈이 입력 이미지에 대한 이미지 임베딩을 얻기 위해 사용된다.
언어 전용 데이터, 교차 모달 쌍 데이터(즉, 이미지-텍스트 쌍), 그리고 interleaved 멀티모달 데이터의 경우, 우리는 Kosmos-1과 동일한 입력 표현을 사용한다.
3.2 Grounded Multimodal Large Language Models
Kosmos-1을 기반으로 하는 Kosmos-2는 grounding 및 referring 능력을 통합하여 **멀티모달 대규모 언어 모델(multimodal large language model)**을 향상시킨다. Kosmos-2 또한 Transformer 기반의 causal language model을 backbone으로 사용하며, next-token prediction task로 학습된다.
Kosmos-1에서 사용된 멀티모달 코퍼스(텍스트 코퍼스, 이미지-캡션 쌍, interleaved 이미지-텍스트 데이터 포함) 외에도, 우리는 grounded 이미지-텍스트 쌍을 학습에 추가한다. 학습 손실은 텍스트 토큰 및 위치 토큰과 같은 이산 토큰(discrete token)만을 고려한다. 모델은 위치 토큰과 전체 이미지를 통해 이미지 영역을 찾아 이해하고, 텍스트 스팬을 이미지 영역과 연결하며, 위치 토큰을 사용하여 이미지 영역의 bounding box를 출력하는 방법을 학습할 수 있다.
Kosmos-2는 grounding 및 referring이라는 새로운 능력을 보여준다. Referring 능력을 통해 우리는 bounding box로 이미지 영역을 지적할 수 있다. Kosmos-2는 사용자가 bounding box의 좌표로 지칭하는 이미지 영역을 이해할 수 있다. 이 referring 능력은 새로운 상호작용 방식을 제공한다. 텍스트 출력만 제공할 수 있었던 이전 MLLM [ADL+ 22, HSD+ 22, HDW+ 23]과 달리, Kosmos-2는 시각적 답변(즉, bounding box)을 제공하고 텍스트 출력을 이미지에 grounding할 수 있다. Grounding 능력은 모델이 더 정확하고, 정보가 풍부하며, 포괄적인 응답을 제공할 수 있도록 한다.
Kosmos-1에서 평가된 vision, language, vision-language task 외에도, 이 모델은 grounded image-captioning, grounded VQA, referring expression comprehension 및 generation과 같은 더 많은 다운스트림 task에 사용될 수 있다.
3.3 Model Training
학습 설정 (Training Setup)
우리는 새로 추가된 grounded image-text pairs, monomodal text corpora, image-caption pairs, 그리고 interleaved image-text data를 사용하여 모델을 학습시킨다.
학습 과정에서는 총 419K 토큰의 batch size를 사용하며, 이는 텍스트 코퍼스에서 185K 토큰, 원본 및 grounded image-caption pairs에서 215K 토큰, 그리고 interleaved 데이터에서 19K 토큰으로 구성된다.
Kosmos-2는 60k 스텝 동안 학습되며, 이는 약 250억 토큰에 해당한다.
AdamW optimizer가 사용되었고, 로 설정되었다.
weight decay는 0.01, dropout rate는 0.1로 설정되었다.
learning rate는 처음 375 warm-up 스텝 동안 2e-4로 증가한 후, 선형적으로 0으로 감소한다.
모델은 256개의 V100 GPU에서 학습되었으며, 학습 완료까지 약 하루가 소요된다.
모델에게 텍스트 출력을 시각 세계에 grounding해야 할 시점을 알려주기 위해, 학습 중 grounded caption 앞에 '<grounding>' 토큰을 추가한다.
Kosmos-1에 따라, vision encoder는 24개의 layer로 구성되며, hidden size는 1,024, FFN intermediate size는 4,096이다. multimodal large language model 구성 요소는 24-layer Magneto Transformer [WMH22, MWH22]이며, hidden dimension은 2,048, attention head는 32개, FFN intermediate size는 8,192이다. 학습 가능한 총 파라미터 수는 약 1.6B에 달한다. 이미지 해상도는 224x224로 설정되었고, patch size는 14x14이다. 이미지의 너비와 높이는 각각 32개의 bin으로 나뉘며, 각 bin은 7x7 픽셀로 구성된다. 총 32x32개의 location token이 vocabulary에 추가된다. Kosmos-2는 Kosmos-1의 가중치를 초기값으로 사용하며, 새로 추가된 location token의 word embedding은 무작위로 초기화된다. 학습 및 instruction tuning 동안 모든 파라미터가 업데이트된다.
Instruction Tuning
모델 학습이 완료된 후, Kosmos-2가 인간의 지시(instruction)에 더 잘 부합하도록 instruct tuning을 수행한다.
이를 위해 **vision-language instruction dataset (예: LLaVA-Instruct [LLWL23])**과 **language-only instruction dataset (예: Unnatural Instructions [HSLS22] 및 FLANv2 [LHV23])**을 학습 데이터와 결합하여 모델을 튜닝한다.
또한, GrIT에 포함된 bounding box와 표현(예: 명사구, 지칭 표현) 쌍을 활용하여 grounded instruction data를 구축한다.
표현-bounding box 쌍이 주어지면, "<p> expression </p>"을 입력 instruction으로 사용하고, 모델이 해당 bounding box의 location token을 생성하도록 prompt한다.
또한 "<p> It </p><box><loc><loc></box> is"와 같은 prompt를 사용하여 모델이 bounding box에 따라 표현을 생성하도록 요청한다.
더 많은 템플릿은 Appendix의 Table B에 제시되어 있다.
4 Evaluation
우리는 먼저 Kosmos-2를 multimodal grounding 및 multimodal referring task에 대해 평가하여 새로운 기능들을 검증한 다음, Kosmos-1에서 평가했던 language 및 perception-language task에 대해 모델을 테스트한다.
- Multimodal grounding
- Phrase grounding
- Referring expression comprehension
- Multimodal referring
- Referring expression generation
- Perception-language tasks
- Image captioning
- Visual question answering
- Language tasks
- Language understanding
- Language generation
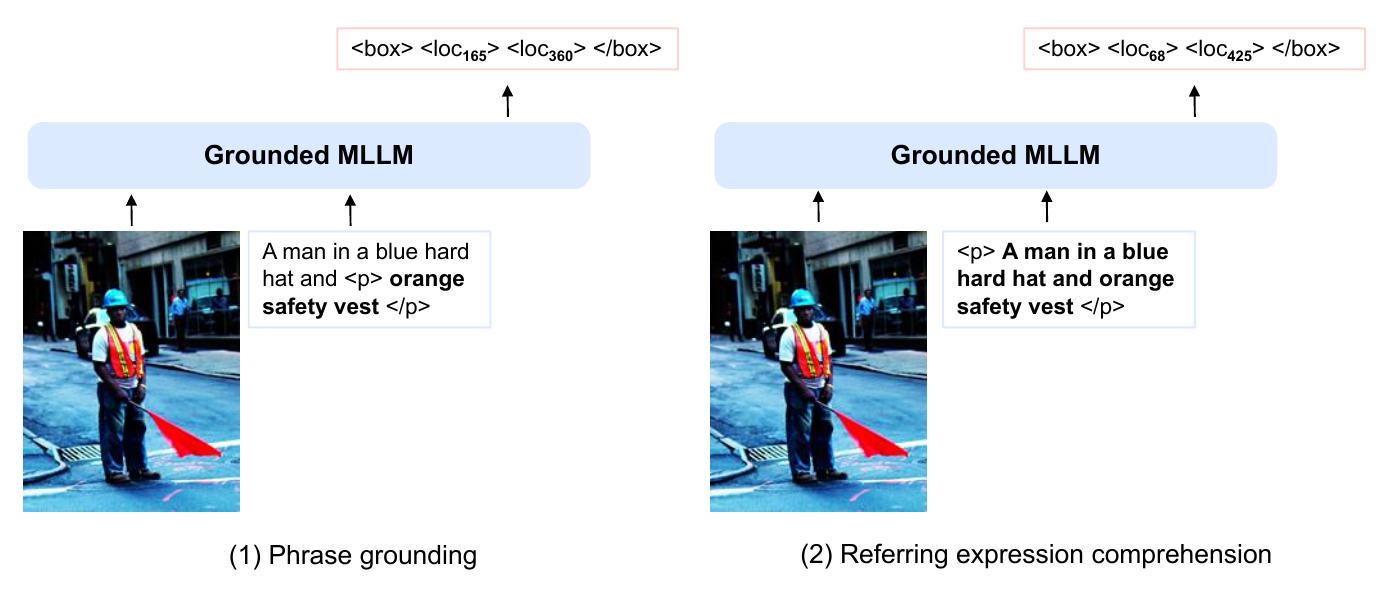
Figure 4: (1) phrase grounding 및 (2) referring expression comprehension 평가를 위한 입력 형식.
4.1 Multimodal Grounding
멀티모달 grounding 능력을 평가하기 위해, 우리는 Kosmos-2를 널리 사용되는 phrase grounding 및 referring expression comprehension task에 대해 생성(generation) 방식으로 테스트한다. Phrase grounding task는 모델이 단일 caption 내에서 상호 연관될 수 있는 하나 이상의 주어진 phrase를 기반으로 bounding box 집합을 예측하도록 요구한다. Referring expression comprehension task는 모델이 주어진 이미지 내에서 텍스트 referring expression에 설명된 객체를 찾아내도록 한다.
이 두 task에 대해 Kosmos-2를 테스트함으로써, 우리는 모델이 텍스트 설명을 시각 세계에 얼마나 잘 grounding하는지를 평가할 수 있으며, 이는 복잡한 멀티모달 task를 처리할 수 있는 고급 AI 시스템을 개발하는 데 매우 중요하다. phrase grounding 및 referring expression comprehension task 모두에서 Kosmos-2는 위치 토큰(location token)을 생성해야 하며, 이 토큰들은 평가를 위해 bounding box로 변환된다. 입력 형식은 "<s><image> Image Embedding </image><grounding>..."이며, 여기서 "<grounding>"은 모델이 위치 토큰을 생성하도록 prompt하는 데 사용된다.
4.1.1 Phrase Grounding
우리는 Flickr30k Entities [PWC15]의 val 및 test split에서 phrase grounding task를 평가한다. 모호성을 줄이기 위해, 우리는 모델에 개별 phrase를 직접 prompt로 주지 않는다. 대신, 현재 phrase와 선행 단어들을 함께 입력으로 사용하며, 이때 선행 단어들은 컨텍스트 역할을 한다: "... <p> {phrase} </p>". Figure 4(1)에 제시된 예시에서, 모델은 "A man in a blue hard hat and orange safety vest stands in an intersection."이라는 캡션에서 "A man", "a blue hard hat", "orange safety vest", "an intersection"이라는 phrase들의 위치를 예측해야 한다. 캡션의 시작 부분인 "A man"이라는 phrase의 위치 토큰을 생성하기 위한 prompt는 "<p>A man</p>"이다. "orange safety vest"라는 phrase의 경우, prompt는 "A man in a blue hard hat and <p>orange safety vest</p>"이다. 이미지에 여러 명의 남자가 있을 때, "A man in a blue hard hat and"라는 컨텍스트는 모델이 모호성을 줄이고 올바른 객체를 찾는 데 명확하게 도움을 준다.
우리는 모델 응답에서 "<box> . . . </box>" 형식의 위치 토큰을 얻은 다음, 이를 bounding box로 변환한다. 생성된 bounding box는 ground-truth bounding box와의 IoU(Intersection over Union)가 0.5보다 클 경우 올바른 것으로 간주한다. 만약 KOSMOS-2가 올바르게 변환될 수 없는 위치 시퀀스(예: "<box><locbox>")를 생성하면, 이를 negative sample로 처리한다. 우리는 MDETR [KSL21]의 ANY-BOX 프로토콜을 사용한다. 우리는 R@1, R@5, R@10 metric을 보고하는데, 여기서 R@1/5/10은 상위 1/5/10개의 생성된 bounding box를 사용하여 recall을 계산하는 것을 의미한다. 만약 Kosmos-2가 5개 또는 10개 미만의 bounding box를 생성했다면, 계산을 위해 사용 가능한 모든 bounding box를 사용한다.
결과 Table 2는 Flickr30k Entities [PWC15]의 val 및 test split에 대한 결과를 제시한다. Kosmos-2는 인상적인 zero-shot 성능을 달성하며, detector에 의존하는 GRILL [JMC23]을 큰 차이로 능가한다. 또한, 우리 모델은 기존의 fine-tuned 모델보다 뛰어난 성능을 보인다.
| Model | Zero-shot | Val Split | Test Split | ||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| VisualBert [LYY19] | 70.4 | 84.5 | 86.3 | 71.3 | 85.0 | 86.5 | |
| MDETR [KSL21] | 83.6 | 93.4 | 95.1 | 84.3 | 93.9 | 95.8 | |
| GLIP [LZZ22] | 86.7 | 96.4 | 97.9 | 87.1 | 96.9 | 98.1 | |
| FIBER [DKG22] | 87.1 | 96.1 | 97.4 | 87.4 | 96.4 | 97.6 | |
| GRILL [JMC23] | - | - | - | 18.9 | 53.4 | 70.3 | |
| Kosmos-2 | 77.8 | 79.2 | 79.3 | 78.7 | 80.1 | 80.1 |
Table 2: Flickr30k Entities에 대한 Phrase grounding 결과. 우리는 R@1, R@5, R@10 metric을 보고하며, 여기서 R@1/5/10은 상위 1/5/10개의 생성된 bounding box를 사용하여 recall을 계산하는 것을 의미한다.
| Model | Zero- | RefCOCO | RefCOCO+ | RefCOCOg | |||||
|---|---|---|---|---|---|---|---|---|---|
| shot | val | testA | testB | val | testA | testB | val | test | |
| UNITER [CLY19] | 81.41 | 87.04 | 74.17 | 75.90 | 81.45 | 66.70 | 74.86 | 75.77 | |
| MDETR [KSL+ 21] | 87.51 | 90.40 | 82.67 | 81.13 | 85.52 | 72.96 | 83.35 | 83.31 | |
| OFA [WYM22] | 90.05 | 92.93 | 85.26 | 84.49 | 90.10 | 77.77 | 84.54 | 85.20 | |
| FIBER [DKG+22] | 90.68 | 92.59 | 87.26 | 85.74 | 90.13 | 79.38 | 87.11 | 87.32 | |
| VisionLLM [WCC23] | 86.7 | - | - | - | - | - | - | - | |
| GRILL [JMC23] | - | - | - | - | - | - | - | 47.5 | |
| Kosmos-2 | 52.32 | 57.42 | 47.26 | 45.48 | 50.73 | 42.24 | 60.57 | 61.65 |
Table 3: RefCOCO, RefCOCO+ 및 RefCOCOg에 대한 Referring expression comprehension 결과. 모든 방법에 대해 accuracy metric을 보고한다.
VisualBert [LYY19] 모델보다 val 및 test split 모두에서 R@1이 7.4% 더 높다. 다른 모델들과 달리, Kosmos-2는 사전 설계된 요소(예: object query 또는 proposal)를 포함하지 않으면서도, R@1, R@5, R@10 간에 유사한 결과를 보인다. 이러한 결과는 Kosmos-2가 중복된 위치에 대한 후처리 없이도 고품질의 위치를 생성할 수 있음을 보여준다. 이러한 능력은 phrase grounding task를 처리하는 데 있어 우리 모델의 효과성을 강조한다.
4.1.2 Referring Expression Comprehension
Referring Expression Comprehension task는 잘 알려진 세 가지 데이터셋인 **RefCOCO [YPY+16], RefCOCO+ [YPY+16], RefCOCOg [MHT+15]**를 사용하여 평가한다.
RefCOCO와 RefCOCO+는 모두 two-player game을 통해 생성되었으며, RefCOCO+는 특히 "on the left"와 같은 공간 관계(spatial relations)를 배제하도록 설계되었다. RefCOCOg는 공간 관계를 포함하며, 평균적으로 더 긴 표현을 특징으로 한다.
Flickr30k entities에 대한 phrase grounding과는 다르게, 우리는 referring expression을 입력으로 사용하여 이 task를 측정한다: "<p> referring expression </p>".
Figure 4(2)에 제시된 예시의 경우, 입력 시퀀스는 "<p>A man in a blue hard hat and orange safety vest</p>"이다.
마찬가지로, 예측된 bounding box는 ground-truth bounding box와의 IOU가 0.5보다 클 경우에만 정확하다고 간주된다. 디코딩에 실패한 시퀀스 또한 negative sample로 처리된다. 우리는 쿼리 표현에 대해 처음으로 생성된 bounding box를 사용하여 정확도를 측정한다.
결과
Table 3는 RefCOCO [YPY+16], RefCOCO+ [YPY+16], RefCOCOg [MHT+15]에 대한 referring comprehension 결과를 보고한다.
Kosmos-2는 comprehension task에서 유망한 zero-shot 성능을 얻었으며, 특히 RefCOCOg 벤치마크에서 이전 zero-shot 모델들을 크게 능가한다.
그러나 이전 fine-tuned 연구들과 비교했을 때, Kosmos-2는 RefCOCOg보다 RefCOCO와 RefCOCO+에서 약간 낮은 성능을 보인다. 이러한 불일치는 RefCOCO와 RefCOCO+에 존재하는 데이터 분포에 기인할 수 있는데, 이들 데이터셋은 two-player game 동안 더 짧은 referring expression (예: "left bottom")을 사용하는 경향이 있다.
따라서 우리의 향후 목표 중 하나는 MLLM이 더 다양한 유형의 인간 표현을 정확하게 이해하는 능력을 향상시키는 것이다.

Figure 5: Referring expression generation 평가의 입력 형식 (1) zero-shot 및 (2) few-shot 설정. 이미지에 표시된 bounding box는 시각화를 위한 것이다.
4.2 Multimodal Referring
멀티모달 grounding task 외에도, 우리는 사용자가 바운딩 박스(bounding box)를 입력하여 참조하는 이미지 영역 또는 객체를 모델이 이해하는 능력을 평가한다. 자세한 텍스트 설명으로만 이미지 영역이나 객체를 모델에 참조할 수 있었던 기존 멀티모달 LLM과 비교할 때, 바운딩 박스를 사용하여 이미지 영역을 직접 참조하는 방식은 더 효과적이며 모호성을 줄여준다.
우리는 referring expression generation task에서 모델을 평가한다. 이 task는 바운딩 박스 내의 특정 객체나 영역에 대해 모호하지 않은 텍스트 설명(unambiguous text description)을 생성하는 것을 목표로 한다. 모델의 성능을 zero-shot 및 few-shot 설정 모두에서 평가하기 위해 널리 사용되는 **RefCOCOg 데이터셋 [MHT15]**을 사용하며, 이는 다양한 시나리오에서의 모델 적응성을 보여준다.
4.2.1 Evaluation Setup
모델은 바운딩 박스의 위치 토큰(예: "<box><loc box ")이 주어졌을 때, 해당 객체 또는 영역에 대한 텍스트 설명을 생성하는 task를 수행한다. 통합된 입력 형식의 이점을 활용하여, 우리는 모델이 텍스트 설명을 예측하도록 유도하기 위해 **"<p> It </p><box><loc box is"**를 prompt로 사용한다. Figure 5 (1)과 (2)는 각각 zero-shot 및 few-shot referring expression generation을 위한 입력 형식을 보여준다. 이전 연구들을 따라, 우리는 METEOR 및 CIDEr metric을 사용하여 결과를 보고한다. 이미지 해상도는 ****이며, 디코딩에는 Greedy search가 사용된다.
4.2.2 Results
Table 4는 RefCOCOg 데이터셋에 대한 referring expression generation의 zero-shot 및 few-shot 결과를 보여준다. 우리는 Kosmos-2를 fine-tuned listener-speaker 모델과 비교했는데, 이 모델은 reward 기반 모듈(SLR)을 추가로 도입한다. 우리 모델은 referring expression generation에서 인상적인 zero-shot 성능을 얻었으며, fine-tuned SLR보다 1.1 CIDEr 점수 더 높은 성능을 보인다. 더욱이, few-shot demonstration으로 prompt를 구성했을 때 Kosmos-2는 추가적인 개선을 보여주며, 이는 in-context learning 능력을 강조한다.
| Model | Setting | RefCOCOg | |
|---|---|---|---|
| Meteor | CIDEr | ||
| SLR[YTBB17] | Finetuning | 15.4 | 59.2 |
| SLR+Rerank[YTBB17] | Finetuning | 15.9 | 66.2 |
| Kosmos-2 | Zero-shot | 12.2 | 60.3 |
| Few-shot | 13.8 | 62.2 | |
| Few-shot | 14.1 | 62.3 |
Table 4: RefCOCOg에 대한 referring expression generation 결과.
4.3 Perception-Language Tasks
멀티모달 grounding 및 referring task 외에도, 우리는 Kosmos-1에 이어 Kosmos-2를 vision-language task에 대해서도 평가한다. 특히, 우리는 image captioning과 visual question answering이라는 두 가지 인기 있는 task에 대해 zero-shot 평가를 수행한다. Image captioning은 모델이 주어진 이미지에 대한 텍스트 설명을 생성하도록 요구하는 반면, visual question answering은 이미지에 기반하여 자연어 질문에 답하는 것을 목표로 한다. Kosmos-1과의 공정한 비교를 위해, 우리는 instruction tuning 없이 결과를 보고한다.
4.3.1 Evaluation Setup
**이미지 캡셔닝(image captioning)**의 경우, 널리 사용되는 Flickr30k Karpathy split test set에서 모델을 평가한다. 캡션 생성에는 beam size 5의 beam search를 사용한다. 결과는 COCOEvalCap으로 평가된 CIDEr [VLZP15] metric을 사용하여 보고한다. 이미지 설명을 생성하기 위해 "An image of"라는 prompt를 사용한다.
**Visual Question Answering (VQA)**의 경우, VQAv2의 test-dev set에서 zero-shot 성능을 평가한다. 디코딩에는 greedy search를 사용한다. VQA 점수는 VQAv2 평가 서버에서 얻은 점수를 보고한다. 데이터셋의 prompt로는 "Question: {question} Answer: {answer}"를 사용한다. 두 task 모두 이미지 해상도는 224x224이다.
4.3.2 Results
우리는 Flickr30k와 VQAv2에 대한 zero-shot 성능을 Table 5에 제시한다. Kosmos-2는 Kosmos-1과 비슷한 전반적인 성능을 보이며, Flickr30k에서는 약간의 향상을 보였지만 VQA에서는 미미한 감소를 경험했다. Kosmos-2가 grounding 및 referring과 같은 새로운 기능을 도입했음에도 불구하고, 모델은 인지-언어(perception-language) task에서 여전히 경쟁력 있는 성능을 달성한다.
| Model | Flickr30k | VQAv2 |
|---|---|---|
| CIDEr | VQA acc. | |
| FewVLM [JCS 22] | 31.0 | - |
| METALM [HSD 22] | 43.4 | 41.1 |
| Flamingo-3B | 60.6 | 49.2 |
| Flamingo-9B | 61.5 | 51.8 |
| Kosmos-1 | 65.2 | 46.7 |
| Kosmos-2 | 66.7 | 45.6 |
Table 5: Flickr30k test set에 대한 zero-shot image captioning 결과 및 VQAv2 test-dev set에 대한 zero-shot visual question answering 결과. instruction tuning 없이 Kosmos-2와 Kosmos-1의 결과를 보고한다.
4.4 Language Tasks
우리는 Kosmos-2를 cloze 및 completion task(StoryCloze, HellaSwag), Winograd 스타일 task(Winograd, Winogrande), commonsense reasoning(PIQA), 그리고 세 개의 SuperGLUE benchmark [WPN 19] 데이터셋(BoolQ, CB, COPA) 등 총 여덟 개의 language task에서 평가하였다. Table 6에는 zeroshot 결과를 보고하였다. Kosmos-1과 비교했을 때, Kosmos-2는 StoryCloze, HellaSwag, Winograd, Winogrande, PIQA에서 유사한 성능을 보였고, CB에서는 성능이 감소했지만, BoolQ와 COPA에서는 향상을 보였다. 요약하자면, Kosmos-2는 새로운 능력의 획득을 보여주는 동시에, language task에서 전반적으로 유사한 성능을 유지하였다. 이는 다양한 도메인에서 모델이 능력을 균형 있게 확장할 수 있는 가능성을 보여준다.
| Model | Story <br> Cloze | Hella <br> Swag | Winograd | Winogrande | PIQA | BoolQ | CB | COPA |
|---|---|---|---|---|---|---|---|---|
| LLM | 72.9 | 50.4 | 71.6 | 56.7 | 73.2 | 56.4 | 39.3 | 68.0 |
| Kosmos-1 | 72.1 | 50.0 | 69.8 | 54.8 | 72.9 | 56.4 | 44.6 | 63.0 |
| Kosmos-2 | 72.0 | 49.4 | 69.1 | 55.6 | 72.9 | 62.0 | 30.4 | 67.0 |
Table 6: Kosmos-2, Kosmos-1, 그리고 LLM 간의 language task에 대한 zero-shot 성능 비교. LLM은 Kosmos-1과 동일한 텍스트 데이터와 training setup을 사용하여 language model을 재구현한 것이다. 우리는 Kosmos-2와 Kosmos-1의 instruction tuning을 적용하지 않은 결과를 보고한다. Kosmos-1과 LLM baseline의 결과는 [HDW 23]에서 가져온 것이다.
5 Conclusion
우리는 시각 세계에 grounding할 수 있는 **멀티모달 대규모 언어 모델(multimodal large language model)**인 Kosmos-2를 소개한다. 구체적으로, 우리는 Kosmos-1에서 사용된 멀티모달 코퍼스에 GrIT를 추가하여 Kosmos-2를 사전학습한다. GrIT는 Grounded Image-Text 쌍으로 구성된 대규모 데이터셋으로, 캡션 내의 **명사구(noun phrase)**와 **지칭 표현(referring expression)**을 장면에 있는 객체나 영역과 연결하여 추출함으로써 생성된다.
Kosmos-2는 이미지 영역을 인지하고 텍스트 출력을 시각 세계에 grounding하는 새로운 능력을 가능하게 하며, 이는 많은 다운스트림 애플리케이션에서 grounding을 MLLM의 핵심 기반 능력으로 만든다. 실험 결과는 Kosmos-2가 Kosmos-1에서 평가된 언어 및 vision-language task, phrase grounding 및 referring expression comprehension을 포함한 grounding task, 그리고 referring expression generation과 같은 referring task에서 인상적인 결과를 달성함을 보여준다.
Acknowledgement
일부 예시(Figure 1 등)는 WHOOPS 코퍼스 []에서 가져왔다.
Ethics Statement
본 논문에서 제시된 모델은 학술 및 연구 목적으로 개발되었다. 부적절한 자료를 생성하기 위한 모델의 활용은 엄격히 금지되며, 본 연구에서 지지하지 않는다. 모델의 부적절하거나 용납할 수 없는 적용에 대한 책임은 전적으로 그러한 콘텐츠를 생성한 개인에게 있다. 우리는 또한 모델을 개발할 때 Microsoft AI Principles를 실천하였다.
A Hyperparameters
Kosmos-2의 학습 하이퍼파라미터는 Table 7에 나열되어 있다.
| Hyperparameters | |
|---|---|
| Image embedding number | 64 |
| Location tokens | 1,024 |
| Training steps | 60,000 |
| Warmup steps | 375 |
| Optimizer | AdamW |
| Learning rate | |
| Learning rate decay | Linear |
| Adam | (0.9, 0.98) |
| Weight decay | 0.01 |
| Batch size of text corpora | 93 |
| Batch size of original image-caption pairs | 1,117 |
| Batch size of grounded image-text pairs | 1,117 |
| Batch size of interleaved data | 47 |
Table 7: Kosmos-2의 학습 하이퍼파라미터
instruction tuning 하이퍼파라미터는 Table 8에 나열되어 있다.
| Hyperparameters | |
|---|---|
| Training steps | 10,000 |
| Warmup steps | 375 |
| Learning rate | |
| Batch size of language instruction data | 117 |
| Batch size of vision-language instruction data | 351 |
| Batch size of grounded image-text pairs | 1404 |
| grounded instruction data | 30 |
| Batch size of text corpora | 15 |
| Batch size of interleaved data |
Table 8: Kosmos-2의 instruction tuning 하이퍼파라미터
B Templates for Grounded Instruction Data
Table 9는 instruction tuning 중 bounding box와 관련된 표현(expression) 생성에 사용된 instruction template을 보여준다.
- "What is it ? It is expression ."
- "What is this box box ? This is expression ."
- "Describe <p> this object </p><box><loc box . This object is expression ."
- "<p> It </p><box><loc loc box is expression ."
- "<p> This </p><box><loc box is expression ."
- "<p> The object </p><box><loc loc box is expression ."
Table 9: 표현(expression) 생성에 사용된 instruction template.
C Examples of GriT
우리는 Figures 6-9에서 GrIT 코퍼스의 몇 가지 예시를 제시한다. Grounded image-text 쌍은 다양한 도메인에 걸쳐 있으며, 서로 다른 수의 객체를 포함한다.

Figure 6: GrIT의 예시. Caption: "A serving of kale and roasted vegetable salad on an aluminium tray served with a small white bowl filed with creamy light green avocado Caesar dressing".

Figure 7: GrIT의 예시. Caption: "A Keto Chicken Nugget being dipped into a bowl of keto honey mustard.".

Figure 8: GrIT의 예시. Caption: "Solar cells on a red roof are in the foreground. The Sydney skyline is in the background.".

Figure 9: GrIT의 예시. Caption: "Woman standing outdoors in a city landscape and wearing a hijab. Her arm is around a young girl who is hugging her side. The background is blurred.".
D More Examples of Kosmos-2

Figure 10: Kosmos-2에서 생성된 visual dialogue 예시.
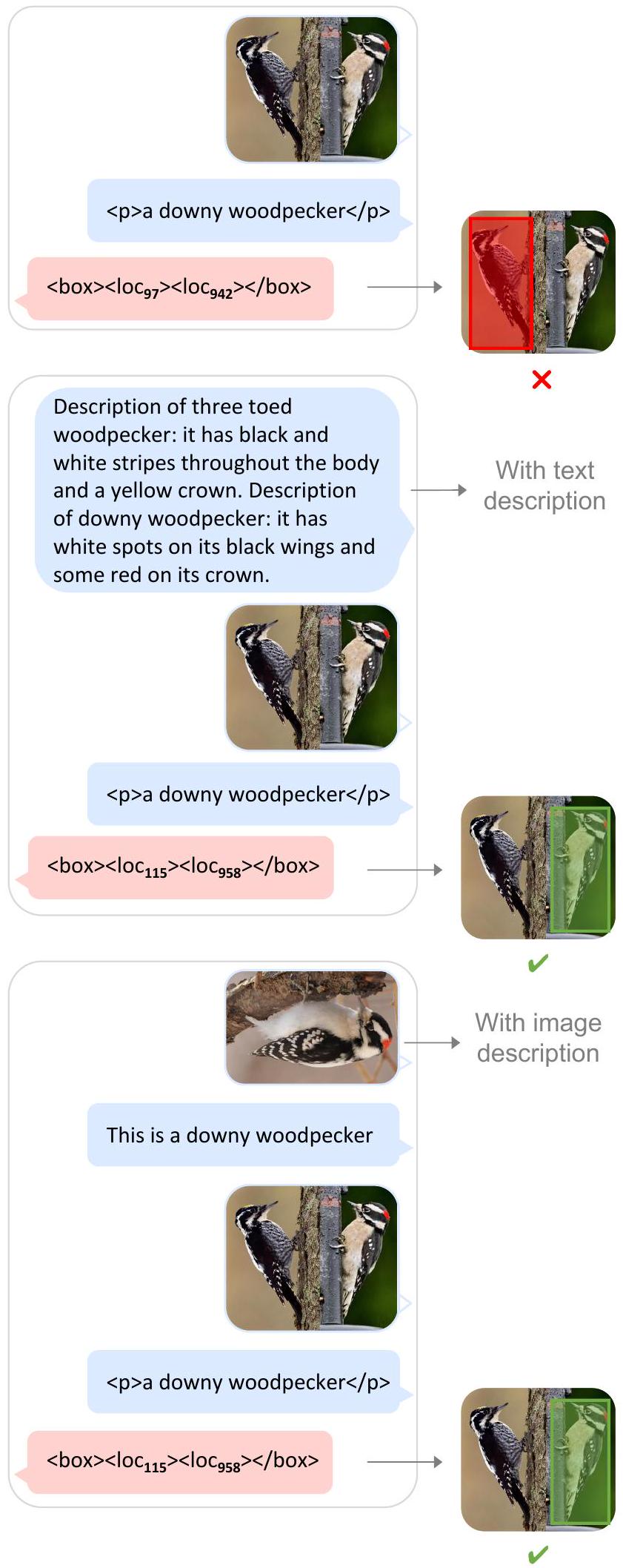
Figure 11: Kosmos-2에서 생성된 멀티모달 설명을 이용한 object detection 예시.

Figure 12: Kosmos-2에서 생성된 예시.

Figure 13: Kosmos-2에서 생성된 grounded image captioning 예시.